撰文:李丹
來源:華爾街見聞
憑藉ChatGPT 掀起人工智能(AI)應用熱潮的OpenAI 發布了最新作品——GPT-4。得到這種新模型支持的ChatGPT 將迎來升級。
美東時間3 月14 日週二,OpenAI 宣布,推出大型的多模態模型GPT-4,稱它可以接收圖像和文本輸入,輸出文本,「比以往任何更具創造性和協作性」,並且「由於它有更廣泛的常識和解決問題的能力,可以更準確地解決難題。」
OpenAI 表示,已經與多家公司合作,要將GPT-4 結合到他們的產品中,包括Duolingo、Stripe 和Khan Academy。 GPT-4 模型也將以API 的形式,提供給付費版ChatGPT Plus 的訂閱用戶。開發者可以註冊,用它打造應用。
微軟此後表示,新款的必應(Bing)搜索引擎將運行於GPT-4 系統之上。
GPT-4 全稱生成式預訓練轉換器4。它的兩位「前輩」GPT-3 和GPT3.5 分別用於創造Dall-E 和ChatGPT,都吸引了公眾關注,刺激其他科技公司大力投入AI 應用領域。
OpenAI 介紹,相比支持ChatGPT 的前代GPT-3.5,GPT-4 和用戶的對話只有微妙的差別,但在面對更複雜的任務時,兩者的差異更為明顯。
「在我們的內部評估中,它產生正確回應的可能性比GPT-3.5 高40%。」
OpenAI 還稱,GPT-4 參加了多種基准考試測試,包括美國律師資格考試Uniform Bar Exam、法學院入學考試LSAT、「美國高考」SAT 數學部分和證據性閱讀與寫作部分的考試,在這些測試中,它的得分高於88% 的應試者。
上週,微軟德國的首席技術官(CTO)Andreas Braun 在德國出席一個AI 活動時透露,本週將發布多模態的系統GPT-4,它「將提供截然不同的可能性,比如視頻」。這讓外界猜測,GPT-4 應該能讓用戶將文本轉換為視頻,因為他說該系統將是多模態的,也就在暗示,不僅能生成文本,還會有其他媒介。
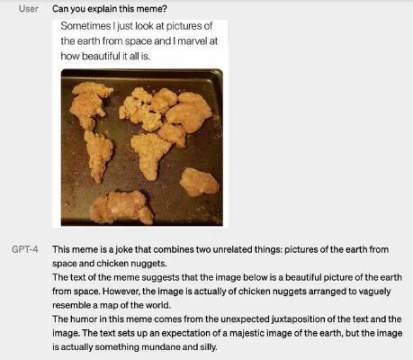
本週二OpenAI 介紹的GPT-4 的確是多模態的,但它能融合的媒介沒有一些人預測的多。 OpenAI 表示,GPT-4 能同時解析文本和圖像,所以能解讀更複雜的輸入內容。
在下面的示例中,我們可以看到GPT-4 系統如何應答圖像輸入內容,比如像以下截圖那樣解釋圖片的不同尋常之處、圖片的幽默之處、一個搞怪圖片的用意。