
4月17日,IOSG Ventures 第十二屆老友記(Old Friends Reunion)如期舉行,本次活動主題為《Singularity: AI x Crypto Convergence》, 因此,我們也邀請了業界正在嶄露頭角的傑出代表。這次聚會的目的是讓參與者共同探討人工智慧和加密貨幣領域的融合之處,以及這種融合對未來的影響。在這樣的活動中,與會者有機會分享他們的見解、經驗和想法,以促進業界的合作與創新。
接下來是本次活動的Keynote之一,由來自IOSG Ventures的Portfolio NEAR Protocol 的聯合創始人Illia Polosukhin 為大家帶來《Why AI Needs to be Open - 為何AI需要Web3》

Why AI Needs to be Open
讓我們來探討一下「為什麼人工智慧需要開放」。我的背景是Machine Learning,在我的職業生涯中大約有十年的時間一直在從事各種機器學習的工作。但在涉足Crypto、自然語言理解和創立NEAR之前,我曾在Google工作。我們現在開發了驅動大部分現代人工智慧的框架,名為Transformer。離開谷歌之後,我開始了一家Machine Learning公司,以便我們能夠教導機器編程,從而改變我們如何與電腦互動。但我們沒有在2017或18年這樣做,那時太早了,當時也沒有計算能力和數據來做到這一點。

我們當時所做的是吸引世界各地的人們為我們做標註數據的工作,大多數是學生。他們在中國、亞洲和東歐。其中許多人在這些國家沒有銀行帳戶。美國不太願意輕易匯款,所以我們開始想要使用區塊鏈作為我們問題的解決方案。我們希望以一種程序化的方式向全球的人們支付,無論他們身在何處,都能讓這變得更加容易。順便說一句,Crypto的目前挑戰是,現在雖然NEAR解決了很多問題,但通常情況下,你需要先購買一些Crypto,才能在區塊鏈上進行交易來賺取,這個過程反其道而行了。
就像企業一樣,他們會說,嘿,首先,你需要購買一些公司的股權才能使用它。這是我們NEAR正在解決的許多問題之一。現在讓我們稍微深入討論一下人工智慧方面。語言模型並不是什麼新鮮事物,50年代就存在了。它是一種在自然語言工具中被廣泛使用的統計工具。很長一段時間以來,從2013年開始,隨著深度學習重新被重新啟動,一種新的創新就開始了。這種創新是你可以匹配單詞,添加到多維度的向量中並轉換為數學形式。這與深度學習模型配合得很好,它們只是大量的矩陣乘法和激活函數。

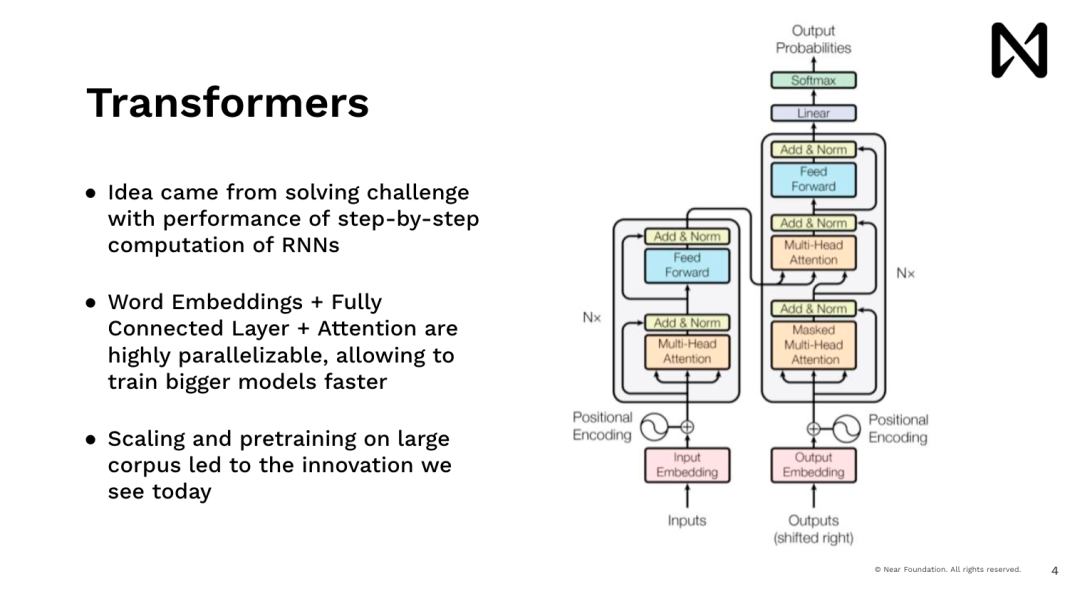
這使我們能夠開始進行先進的深度學習,並訓練模型來做很多有趣的事情。現在回顧起來,我們當時正在做的是神經元神經網絡,它們在很大程度上是模仿人類的模型,我們一次可以讀一個單字。因此,這樣做速度非常慢,對吧。如果你試圖在Google.com上為用戶展示一些內容,沒有人會等待去閱讀維基百科,比如說五分鐘後才給出答案,但你希望馬上得到答案。因此,Transformers 模型,也就是驅動ChatGPT、Midjourney以及所有最近的進展的模型,都是同樣來自這樣的想法,都希望有一個能夠並行處理數據、能夠推理、能夠立即給出答案。
因此這個想法在這裡的一個主要創新是,即每個單字、每個token、每個圖像塊都是並行處理的,利用了我們具有高度平行運算能力的GPU和其他加速器。透過這樣做,我們能夠以規模化的方式對其進行推理。這種規模化能夠擴大訓練規模,從而處理自動訓練資料。因此,在此之後,我們看到了Dopamine,它在短時間內做出了驚人的工作,實現了爆炸性的訓練。它擁有大量的文本,開始在推理和理解世界語言方面取得了驚人的成果。
現在的方向是加速創新人工智慧,之前它是一種資料科學家、機器學習工程師會使用的工具,然後以某種方式,解釋在他們的產品中或能夠去與決策者討論資料的內容。現在我們有了這個AI 直接與人溝通的模式。你甚至可能不知道你在與模型交流,因為它實際上隱藏在產品背後。因此,我們經歷了這種轉變,從之前那些理解AI 如何運作的,轉變成了理解並能夠將其使用。

因此,我在這裡給你們一些背景,當我們說我們在使用GPU來訓練模型時,這不是我們桌上玩電玩時用的那種遊戲GPU。

每台機器通常配備八個GPU,它們都透過一個主機板相互連接,然後堆疊成機架,每個機架大約有16台機器。現在,所有這些機架也都透過專用的網路電纜相互連接,以確保資訊可以在GPU之間直接極速傳輸。因此,資訊不適合CPU。實際上,你根本不會在CPU上處理它。所有的計算都發生在GPU上。所以這是一個超級電腦設定。再次強調,這不是傳統的「嘿,這是一個GPU的事情」。所以規模如GPU4的模型在大約三個月的時間裡就使用了10,000個H100進行訓練,費用達到6400萬美元。大家了解當前成本的規模是什麼樣的以及對於訓練一些現代模型的支出是多少。
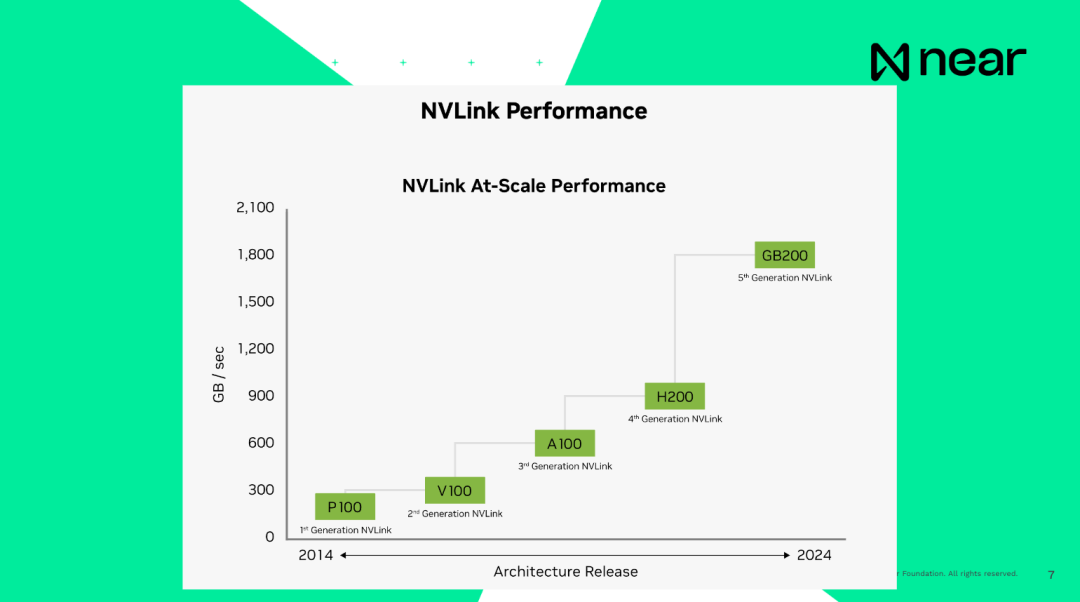
重要的是,當我說系統是相互連接的時候,目前H100的連接速度,即上一代產品,是每秒900GB,電腦內部CPU 與RAM 之間的連接速度是每秒200GB,都是電腦本地的。因此,在同一個資料中心內從一個GPU發送資料到另一個GPU的速度比你的電腦還快。你的計算機基本上可以在箱子裡自己進行通訊。而新一代產品的連線速度基本上是每秒1.8TB。從開發者的角度來看,這不是一個個體的計算單元。這些是超級計算機,擁有一個巨大的記憶體和計算能力,為你提供了極大規模的計算。
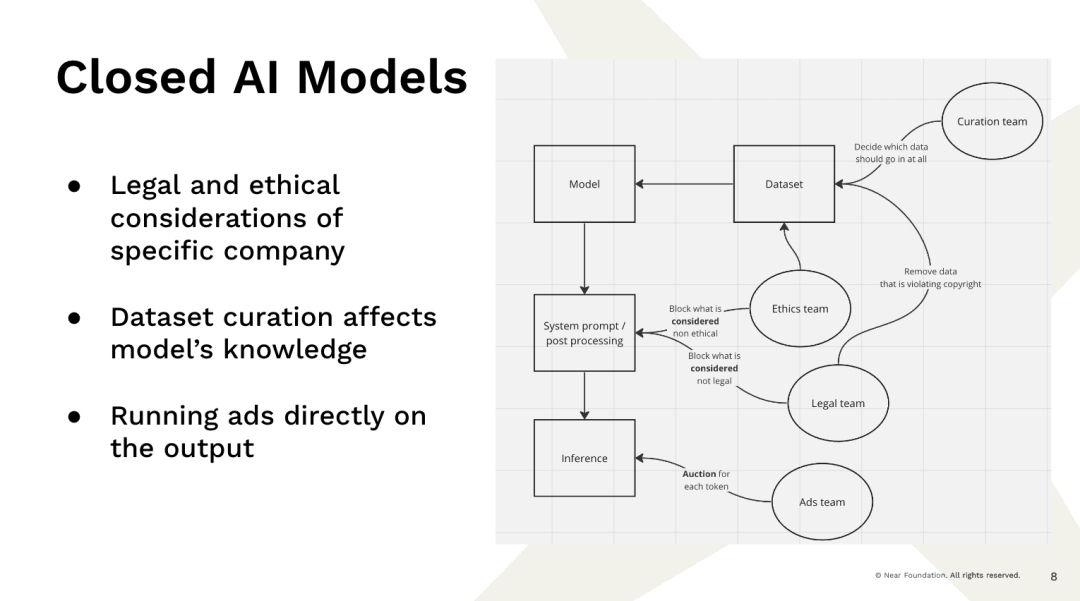
現在,這導致了我們面臨的問題,即這些大公司擁有資源和能力來建立這些模型,這些模型現在幾乎已經為我們提供了這種服務,我不知道其中究竟有多少工作,對吧?所以這就是一個例子,對吧?你去找一個完全集中式的公司提供者,然後輸入一個查詢。結果是,有幾個團隊並不是軟體工程團隊,而是決定結果如何顯示的團隊,對吧?你有一個團隊決定哪些資料進入資料集。
舉個例子,如果你只是從網路上爬取數據,關於巴拉克·歐巴馬出生在肯亞和巴拉克·歐巴馬出生在夏威夷的次數是完全相同的,因為人們喜歡猜測爭議。所以你要決定要在什麼上訓練。你要決定過濾掉一些訊息,因為你不相信這是真的。因此,如果像這樣的個人已經決定哪些數據會被採用且存在這些數據,這些決定在很大程度上是由做出它們的人所影響的。你有一個法律團隊決定我們不能查看哪些內容是受版權保護,哪些是非法的。我們有一個「道德團隊」決定什麼是不道德的,我們不應該展示什麼內容。
所以在某種程度上,有很多這樣的過濾和操縱行為。這些模型是統計模型。它們會從數據中挑選出來。如果數據中沒有某些內容,它們就不會知道答案。如果數據中有某些內容,它們很可能會將其視為事實。現在,當你從AI得到一個答案時,這可能會令人擔憂。對吧。現在,你理應是從模型那裡得到回答,但是沒有任何的保證。你不知道結果是如何產生的。一家公司可能會把你的特定會話賣給出價最高的人來實際改變結果。想像一下,你去詢問應該買哪種車,豐田公司決定覺得應該偏向豐田這個結果,豐田將支付這家公司10美分來做到這一點。

因此,即使你將這些模型用作應該中立並代表數據的知識庫,實際上在你得到結果之前,會發生很多事情,這些事情會以一種非常特定的方式對結果進行偏見。這已經引發了很多問題,對吧?這基本上就是大公司和媒體之間不同法律訴訟的一個星期。 SEC,現在幾乎每個人都在試圖起訴對方,因為這些模式帶來瞭如此多的不確定性和權力。而且,如果往前看,問題在於大型科技公司將永遠有繼續增加收入的動機,對吧?例如,如果你是一家上市公司,你需要報告收入,你需要繼續保持成長。
為了實現這個目標,如果你已經佔據了目標市場,比如說你已經有20億用戶了。在網路上已經沒有那麼多新用戶了。你沒有太多的選擇,除了最大化平均收入,這意味著你需要從用戶那裡提取更多的價值,而他們可能根本沒有什麼價值,或者你需要改變他們的行為。生成式人工智慧非常擅長於操縱和改變使用者的行為,特別是如果人們認為它是以一切知識智能的形式出現的。因此,我們面臨著這種非常危險的情況,在這種情況下,監管壓力很大,監管機構並不完全了解這項技術的工作原理。我們幾乎沒有保護用戶免受操縱的情況。

操縱性內容、誤導性內容,即使沒有廣告,你也可以只是截取一些東西的螢幕截圖,改變標題,發佈到Twitter上,人們就會發瘋。你有經濟誘因機制,導致你不斷地最大化收入。而且,這其實不像在谷歌內部你在做惡事,對吧?當你決定啟動哪個模型時,你會進行A或B測試,看看哪一個能帶來更多收入。因此,你會透過從用戶那裡提取更多價值來不斷地最大化收入。而且,使用者和社群並沒有對模型的內容、使用的數據以及實際嘗試實現的目標有任何輸入。這就是應用程式用戶的情況。這是一種調節。
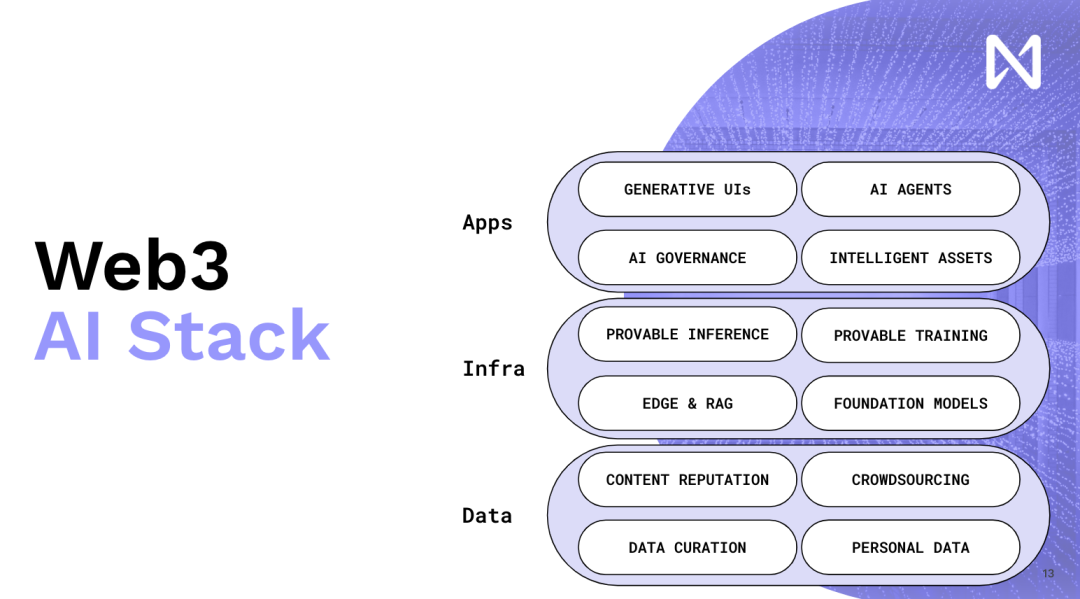
這就是為什麼我們要不斷推動WEB 3和AI融合的原因,web 3 可以是一種重要的工具,它允許我們有新的激勵方式,並且還是以去中心化的形式去激勵我們生產更好的軟體和產品。這是整個web 3 AI 開發的大方向, 現在為了幫助理解細節,我會簡單講一下具體的部分,首先第一部分是Content Reputation。

再次強調,這不是一個純粹的人工智慧問題,儘管語言模型為人們操縱和利用資訊帶來了巨大的影響力並擴大了規模。你想要的是一種可以追蹤的、可追溯的加密聲譽,當你查看不同的內容時,它會顯現出來。所以想像一下,你有一些社群節點,它們實際上是加密的,並且在每個網站的每個頁面上都可以找到。現在,如果你超越這一點,所有這些分發平台都將受到干擾,因為這些模型現在幾乎將閱讀所有這些內容並為你提供個人化摘要和個人化輸出。
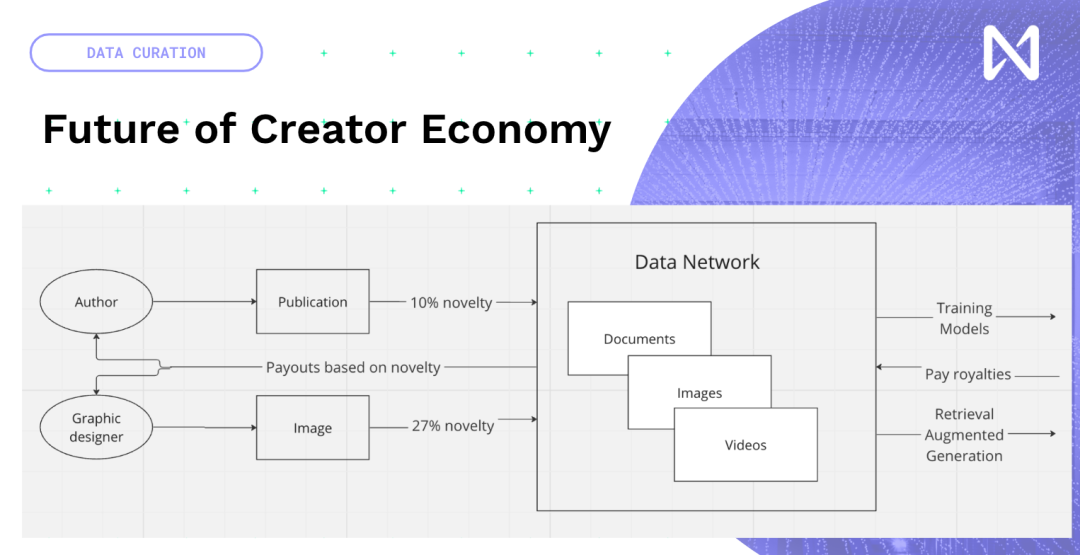
因此,我們實際上有機會創造新的創意內容,而不是試圖重新發明,讓我們在現有內容上加上區塊鏈和NFT。圍繞著模型訓練和推理時間的新創作者經濟,人們創造的數據,無論是新的出版物、照片、YouTube、還是你創作的音樂,都將進入一個基於其對模型訓練的貢獻程度的網絡。因此,根據這一點,根據內容可以在全球範圍內獲得一些報酬。因此,我們從現在由廣告網路推動的吸引眼球的經濟模式過渡到了真正帶來創新和有趣訊息的經濟模式。
我想提一件重要的事情,那就是大量的不確定性來自於浮點運算。所有這些模型都涉及大量的浮點運算和乘法。這些都是不確定性的操作。
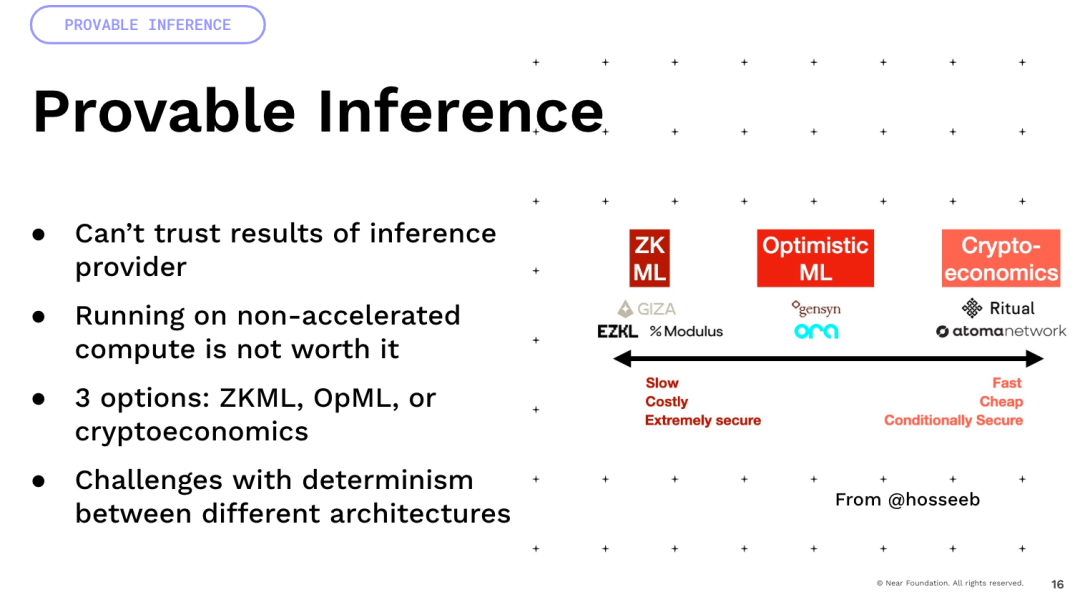
現在,如果你將它們在不同架構的GPU上進行乘法運算。所以你拿一個A100和一個H100,結果會不一樣。因此,許多依賴確定性的方法,例如加密經濟和樂觀主義,實際上會遇到很多困難,並且需要很多創新才能實現這一點。最後,有一個有趣的想法,我們一直在建立可編程貨幣和可編程資產,但是如果你能想像一下,你給它們添加這種智能,你就可以有智能資產,它們現在不是由代碼定義的,而是由自然語言與世界互動的能力來定義,對吧?這就是我們可以有很多有趣的收益優化、DeFi,我們可以在世界內部進行交易策略。

現在的挑戰在於所有當前事件都不具備強大的Robust行為。它們並沒有被訓練成具有對抗性的強大性,因為訓練的目的是預測下一個token。因此,說服一個模型給你所有的錢會更容易。在繼續之前,實際上解決這個問題非常重要。所以我就給你留下這個想法,我們處在一個十字路口上,對吧?有一個封閉的人工智慧生態系統,它有極端的激勵和飛輪,因為當他們推出產品時,他們會產生大量的收入,然後把這些收入投入到建設產品中。但是,該產品天生就是為了最大化公司的收入,從而最大化從用戶提取的價值。或者我們有這種開放、用戶擁有的方法,用戶掌控著局面。

這些模型實際上對你有利的,試圖最大化你的利益。它們為你提供了一種方式,真正保護你免受在網路上的許多危險。所以這就是為什麼我們需要AI x Crypto更多的開發和應用。謝謝大家。














