
本文將分析IPFS的特性,並在與其他分佈式文件系統和超文本傳輸協議(HTTP)比較的基礎上,進行並行研究。
引言
互聯網是由協議和物理設備連接起來的大量計算機器的集合。大多數互聯網內的生態系統都基於客戶端-服務器(請求-響應)模型,但這種模型並非不可破壞,網絡時不時會出現故障。無論是否有控制中心,點對點(P2P)系統都可以高效分發海量數據。 2014年,Juan Benet提出了整合現有的先進技術(分佈式哈希表(DHT)、BitTorrent-like協議、基於Git的數據模型等)創建一個新的協議/文件系統,使每個人都具有共享數據的平等權利,符合互聯網的早期思想。 IPFS具有高效的數據存儲與分發、數據保持、面向離線模式和非集中式管理的特性。
IPFS理論介紹
IPFS是一個純粹的點對點分佈式文件系統,這種系統側重於從主要體系結構中刪除中心點,並在網絡中為相互連接的節點提供相同的功能。所有共享的數據和計算資源都存儲在網絡的邊緣,節點能夠自動運行,並與它們的對等節點共享所需數據。它們能夠自主通信、分發數據、本地化其他節點和所需的文件,並使用同一組協議。

IPFS源於Juan Benet的分佈式、去中心化、共享互聯網的理念,自2014年出現以來,目前仍處於開發階段。現在已有一些可用的實現(如Go和JavaScript),以及一套使用各種編程語言實現的工具、庫和API(應用程序編程接口)。 IPFS的一些主要特點有:數據持久性、點對點基本原理、完全去中心化、無中心點故障、在無互聯網上行鏈路情況下具有本地連接。
HTTP在日常基礎使用中效率低下且昂貴;IPFS使以一種有效的方式使分發大量數據成為可能;
儲存在互聯網上的舊內容通常會和舊版本的文件一起被刪除;IPFS有一種類似於Git的數據版本控制方法;
互聯網用戶依賴於管理其功能的集中設備,當沒有連接到互聯網骨幹網時,他們無法與這些設備通信,也無法訪問他們的個人數據;IPFS是各種彈性網絡的引擎,無論是否有全球上行鏈路,這些網絡都試圖將盡可能提高其分散性。
Juan Benet發布的官方白皮書代表了他對協議架構和模塊的觀點。總的來說,IPFS的靈感來源於一些被塑造成單一、模塊化協議的技術,IPFS利用了這些想法和經驗。我們將簡要介紹這些技術,以更好的理解IPFS。
從IPFS堆棧的最底層開始,網絡層可以進行數據儲存、信息交換及交換控制信息。傳輸本身可使用各種協議(如TCP、UTP、WebSocket、WebRTC等)以一種安全可靠的方式實現,而IPFS本身不綁定到某個特定的協議上。
向上進入到路由層,分佈式哈希表(DHT)用於存儲和管理系統內部的元數據。這些信息包含在給定的時間點上相互連接的節點的信息,並提供快速有效地查找數據的機制。 Kademlia在路由層十分重要,它提供了在大型網絡中查找元數據的有效方法、低協調成本,Coral DSHT通過查詢最近的能夠存儲數據的節點來實現擴展,並提高數據被存儲在更遠位置的節點上的可能性。 S/Kademlia通過強制節點創建用於生成身份和簽名消息的PKI(公鑰基礎設施)密鑰對,進一步增強了針對惡意攻擊的安全性。對於本地定位的節點,使用組播DNS(域名系統)實現相互搜索。
交換層用於確保節點之間的塊傳輸。
進一步到達堆棧上層,默克爾有向無環圖(Merkle DAG)是協議的主要數據模型,很大程度上是受到Git數據結構的啟發。數據樹的節點是通過其內容加密尋址的對象,而它們之間的鏈接由對其他對象的哈希引用表示。每個數據都是由其不可變哈希引用唯一標識的(因此只存儲一次,重複數據刪除),系統能夠使用校驗和檢測損壞的數據。
堆棧的最後一層是命名層。每個節點的唯一標識符是使用PKI密鑰對以加密的方式在本地生成的。星際命名系統(IPNS)是一種用於識別可修改對象的策略。數據塊具有不可變的哈希引用,因此一旦它們的內容改變,哈希引用就會改變。 IPNS概念使用自認證文件系統方案,因此節點能夠在自己唯一的節點標識符上發布數據。如果數據本身改變,哈希引用也會改變,但節點可能會將新的引用重新發佈到相同的唯一節點標識符。 IPNS還支持DNS來提供人類可讀的地址。
處於最上層的是應用層,在這裡,開發人員能夠使用堆棧的底層功能設計和實現新的分佈式、去中心化技術。
IPFS vs. 其他DFS
這一部分將討論各種DFS(分佈式文件系統)和HTTP(超文本傳輸協議)的各方面特性。
NFS(Network File System,網絡文件系統)
是SUN公司在1984年開發的基於RPC(遠程過程調用)協議的開放協議,其基於UDP/IP協議的應用,主要特性是具有一個控制中心,NFS 允許在多個用戶之間共享公共文件系統,並提供數據集中的優勢,來最小化所需的存儲空間。
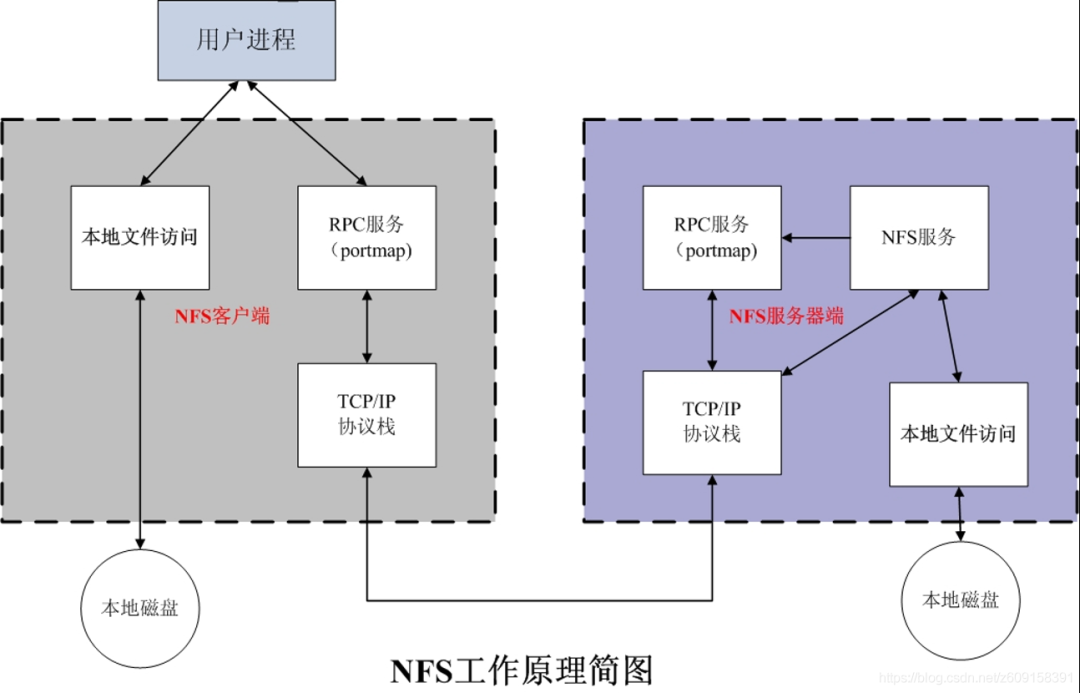
將早期的NFS與IPFS進行比較,我們可以看出,NFS使用服務器和冪等的、無狀態的行為在系統中進行數據同步,而IPFS架構可以不依賴於服務器,因為其哈希引用生成的數據可以在其協議用戶間共享。 IPFS在節點自動狀態下以同步/異步方式處理寫操作,其用戶只要獲得數據標識符,就可以通過元數據交換和搜索在網絡中共享數據。
AFS(Andrew File System,安德魯文件系統)
是由Carnegie Mellon大學在20世紀80年代和IBM公司聯合設計的一個分佈式文件系統,它的主要功能是用於管理分佈在網絡不同節點上的文件,其使用一組受信任的服務器為客戶端提供同類的、地址透明的文件名稱空間,主要目標是實現可擴展性,尤其關注客戶端和服務器之間協議的設計。文件在本地磁盤上整體進行儲存和緩存,客戶端想要訪問一個文件時,將從服務器獲取文件,在本地緩存,然後服務器設置回調(用於之後通知客戶端文件被修改)。 IPFS機制同樣可以用於實現類似的回調和緩存系統,同時保持不集中(單點故障)的優勢。
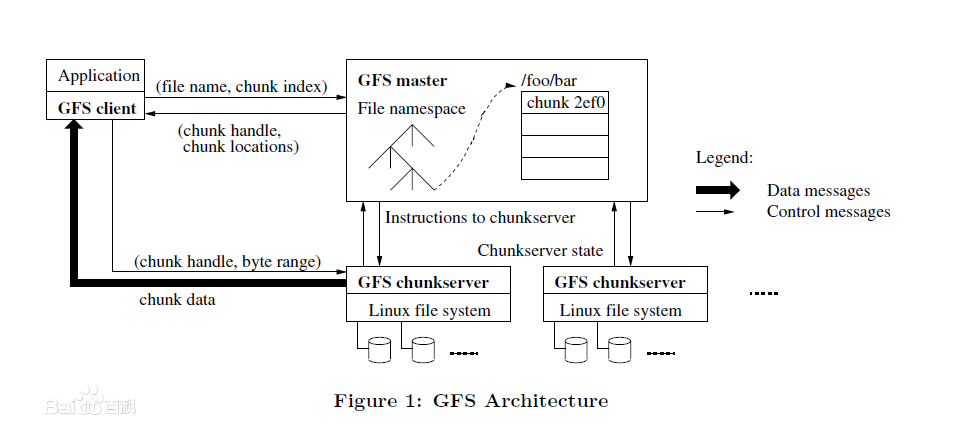
GFS(Google File System,谷歌文件系統)
是谷歌為了存儲海量搜索數據而設計的專用分佈式文件系統,專注於可擴展性、基礎性能和低價硬件。谷歌希望提供一種附加而不是重寫的數據分發方法,從而構建一個可自我持續的文件系統:具有監督恢復、使用主塊架構存儲跨多個服務器備份的大量數據的可能性。 GFS的設計與IPFS有一些相似之處,它使用多個塊服務器、數據塊和替換機器來應對崩潰情況。與IPFS相比,GFS的信息仍然在中心區域管理,由主服務器協調,而IPFS的數據基本上是存儲在網絡中。
HTTP(超文本傳輸協議)
是全球範圍內用於Web上下文中數據交換的最流行的協議之一。它遵循經典的客戶端-服務器模型架構,服務器通常位於互聯網之外,而客戶端則是瀏覽器。整個機制依賴於客戶端和服務器之間的請求(數據)-響應(數據/狀態)交互。其特點是簡單、可擴展、無狀態,具有控制中心。 HTTP目前仍運行良好,但問題逐漸出現:如果資源被刪除、損壞或被其提供者關閉,該怎麼處理?
上述文件系統/協議中使用的所有技術都帶來了保證數據分佈的創新機制:AFS的回調、NFS的冪等性和崩潰時的簡單重試、GFS的可擴展性和低價硬件設計、HTTP的簡單性和長壽命,但它們都依賴於同一個控制中心。
總結
如今的實際應用中,大多數技術都是基於經典的客戶端-服務器模型。此模型自互聯網誕生以來,目前仍能基本滿足客戶的需求。開發人員和工程師需要著重關注的是優化應用程序以最小化計算時間和響應速度,並全面改善我們目前的互聯網系統。 IPFS試圖通過改變數據分佈、存儲和管理的整個視角,同時保持對可能使用的其他協議的開放接口,來解決互聯網的問題。儘管目前IPFS還有很大的改進空間,但其能否成為新一代互聯網協議也猶未可知。











