
加入PolkaWorld 社區,共建Web 3.0!

Web3.0 的願景是讓互聯網更加去中心化。
毫無疑問,提供安全、高可用性、低成本和易於使用的去中心化存儲基礎設施,將成為Web3.0 應用的重要組成部分。
這次PolkaWorld 專訪,我們邀請到了波卡生態永久存儲項目Canyon 創始人徐留成,來聊聊為什麼我們需要永久存儲網絡,Canyon 會如何為波卡生態和Web3.0 帶來更加優秀的存儲基礎設施。
PW:能不能用比較通俗的語言介紹一下Canyon 是做什麼的?
留成:Canyon 是基於Substrate 的波卡生態永久存儲網絡,這個項目受到了Arweave 的很大啟發,你可以簡單把Canyon 看作是波卡生態裡面PoS 版本的Arweave。
通過將PoA(Proof of Access)共識與PoS 系統相結合,Canyon 極大地減少了存儲礦工的准入門檻,並以一種激勵驅動的方式鼓勵礦工存儲盡可能多的數據來贏得更多獎勵。作為一個新項目,除了一些由於區塊鏈技術迭代天然帶來的優越性,Canyon 還在永存數據的持久率(durability)和冗餘度(redundancy)方面進行了創新和改進。我們的最終願景是成為一個在Web3.0 時代真正實用並且可持續的存儲基礎設施。
PW:為什麼會想去做一個永久存儲網絡?
留成:這個問題可以分為兩點來看,一個是為什麼選擇存儲,另一個為什麼選擇永久存儲。
先來看第一個問題,為什麼選擇區塊鏈存儲這個方向。想法其實很簡單,當區塊鏈的計算問題解決以後,毫無疑問將會產生更多的存儲需求。在計算機科學領域,計算與存儲是永遠分不開的兩個問題。對於區塊鏈也是一樣, 目前整個區塊鏈行業其實還是在努力解決去中心化計算的問題,簡單來說也就是TPS 的問題。最早在區塊鏈上做通用計算的是以太坊,我們發現去中心化計算真的有用,但是當以太坊生態慢慢起來以後同時也發現,以太坊的計算功能好用但是也完全不夠用。所以後來出現了很多項目來試圖解決計算問題,比如波卡、Solana、Near 等等。可以說這些項目在計算方面已經有了不少進步,TPS 有了很大提高。隨著未來區塊鏈計算問題得到進一步改善,我們相信加密世界將催生出不僅僅是DeFi 應用, 而是更加豐富多樣的DApps, 這些去中心化應用也將必然催生出更多的去中心化存儲需求。
第二個問題,為什麼要選擇永久存儲。一個是當我們研究了Arweave 以後,我們還是很認同它關於永久存儲的一些看法。然後也確實發現了一些永久存儲的需求,比如目前大火的NFT, 以及一些基於永久存儲網絡解決鏈上計算問題的項目,比如everFinance, 他們利用一個永存網絡實現將鏈上的計算完全放到鏈下, 我們也覺得這是一個值得嘗試的方向。還有一些區塊鏈歷史也會需要永久存儲, 比如以太坊要從PoW 遷到PoS,以太坊基金會就提出了一個方案希望將以太坊整個PoW 的歷史保存在一個存儲網絡中。由此,我們認為永久存儲在未來的Web3.0 也必然會佔有一席之地, 所以最終選擇了永存這個方向。
PW: 當前的存儲項目如何應對當前的去中心化存儲需求十分匱乏的情況?
留成:首先真實的去中心化存儲需求匱乏很大原因還是由於整個加密行業仍然處於早期,一個存儲項目自身其實很難解決存儲需求增長的問題,還是要靠整個加密行業不斷發展,人們對於區塊鏈的認知不斷加深,誕生越來越多在雲盤、視頻、社交等方面更加豐富的去中心化應用才能催生真正的去中心化存儲需求。
比如我們可以設想這樣一個場景,當前的Web2.0 時代,我們登錄每個網絡都可能會需要輸入一些個人信息,那麼未來我們可能可以將個人信息以一種加密的方式存儲到一個存儲網絡,每當一個應用需要讀取部分信息的時候,需要向用戶發起讀取請求,如果用戶確實想開放某些數據的話,在確認後應用可以獲取相關數據並進行解密。這樣就避免了當個人信息託管到一個中心化實體,真正實現了擁有個人數據的所有權。當前的存儲項目在目前真實存儲需求匱乏的情況下,只要做到不鼓勵向網絡中存儲垃圾數據進行獲利的行為,讓數據存儲隨著行業自然生長就可以了。
PW:你認為目前市場上其他的一些存儲方案,比如IPFS、Arweave 等,存在哪些問題?
留成:首先談談Filecoin。 Filecoin 其中一個問題是它實現數據存儲的成本很高,它採用了零知識證明的手段保證了礦工在規定時間內正確存儲了數據,但是零知識證明方案導致礦工礦機的硬件成本非常高。另外有個很簡單的原則,如果廠商所提供的一個服務自身成本很高,那麼這種高成本最終必然會疊加到用戶身上。拋開項目早期的貼補政策,從邏輯上來說,Filecoin 這麼高的存儲成本最終是一定是由客戶來買單的, Filecoin 自然也就無法提供真正低成本的數據存儲服務。
Filecoin 另外一個問題是網絡中存儲了大量的垃圾數據。礦工為了為了逐利不斷地向網絡中存儲垃圾數據來提高算力, 目前整個Filecoin 網絡的存儲容量已經達到了EiB 級別, 顯然這其中99%都是無效的垃圾數據。相比之下,Arweave 現在全網一共才11 T 的數據,中間差了6 個數量級。
與Filecoin 相比,Arweave 的PoA 是一種概率性的存儲共識,以一種近乎零成本的方式實現了激勵數據存儲的效果。但是Arweave 將PoA 共識建立在PoW 之上,拋開PoW 的浪費電力,速度慢,沒有最終性等問題,在數據方面,Arweave 只能基於概率的方式鼓勵礦工存儲數據,但是無法保證數據不會丟失,用戶數據存儲本質上無法得到任何保障。
第二個問題是Arweave 沒有在協議層保證數據的可檢索性,也就是保證數據可讀,雖然它的白皮書提出了wildfire 等依靠網絡節點自身的一些行為進行約束,但是該機制實際上並沒有實現。此外,由於提供數據讀取服務所消耗的帶寬並非零成本,要求節點免費提供檢索服務也不太合理。一個存儲網絡如果無法保證用戶能夠往網絡中獲取到數據,那麼就是沒有價值的。
Arweave 還存在類似於自私挖礦的問題, 就是整個網絡中有一些隱藏數據是其他所有人都讀不到的,節點可以將某些數據藏起來獲得一些挖礦優勢。雖然Arweave 最初這樣設計,是希望激勵礦工存儲更稀少的數據來獲得挖礦優勢,從而增加稀少數據的冗餘度,但實際上最終演變成了可以自私挖礦的一個手段。
最後一個問題就是存儲礦池的問題。存儲礦池是什麼意思呢? Arweave 可能最終會演變成為只有一個存儲礦池的情況。因為PoA 要求只要能獲取到數據就好,那麼作為一個節點,我可以本地不存這個數據,而是加入一個很大的礦池,當需要數據就通過網絡來礦池讀取,這就導致數據可能在全網只存了一份。如果數據只有一份,一旦存儲節點出現任何問題,數據就永久丟失了。
總結一下,在存儲的這個角度,Arweave 在數據持久率、可檢索性、數據冗餘度上均都無法沒有做到任何的理論保障。
PW:那麼Canyon 是如何解決以上這些問題的呢?
留成:Arweave 使用的是“PoW + PoA”,而它的種種問題主要都來源於PoW, 在PoW 中無法知道有多少個礦工,也無法對於存儲礦工所提供的存儲服務施加任何限制,所有礦工都是隨時隨地隨意加入。
Canyon 選擇了 “PoS + PoA”,對於一個PoS 系統,我們可以知道所有節點的數量,也可以對節點的存儲服務上做限制,從而能夠實現一個高數據持久率。具體方案是通過PoS 給節點施加一個最低的存儲比例的限制, 也就是要求每個節點至少要存儲一個最低比例的全網數據。然後這就變成了一個簡單的概率問題,假設有100 個節點,要求每個節點至少存儲所有數據的20%,那麼我們很容易算出某個數據不存在的概率是多大, 就是1 減去所有人都沒有存儲改數據的概率。
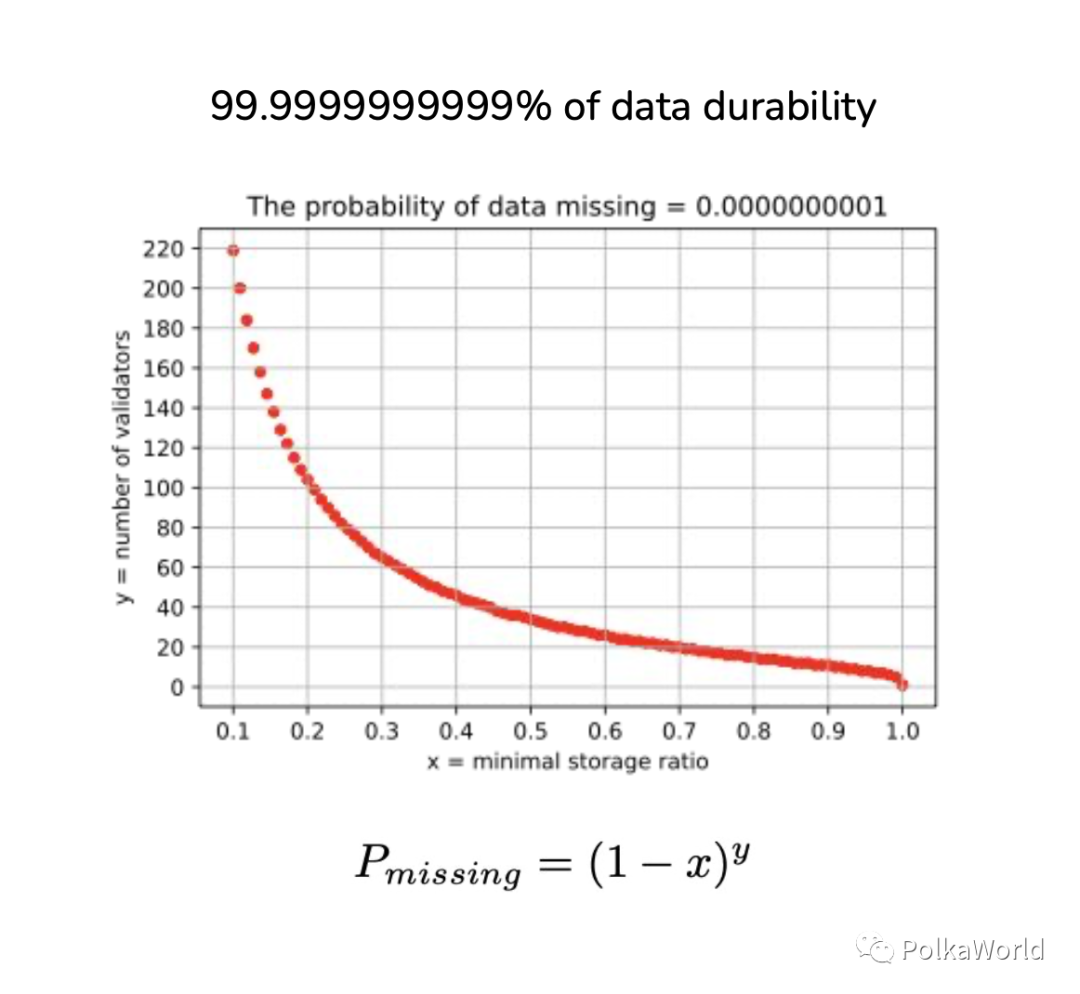
通過這個機制,在200 個節點的情況下,每個人至少存儲10% 的數據就可以做到12 個9 的數據持久率,如果每個人存儲90% 的數據的話,那麼只需要十幾個節點就可以做到。相比而言,亞馬遜只有11 個9 的數據持久率保證。所以說,雖然我們的數據持久率同樣是概率性的,但是我們的
數據丟失概率有理論下限
,而同樣使用PoA 但是選擇PoW 的Arweave 卻無法做到。
數據冗餘度方面,我們是通過讀取付費來間接解決。首先我們認為帶寬不是0 成本的,檢索(讀取)數據也是有成本的。為什麼讀取收費可以解決數據冗餘度問題?因為當這個數據讀取需要付費的時候,對於節點來說就是可盈利的,於是節點就有動機去存儲一些有頻繁讀取需求的數據。那麼如果一個數據被越頻繁地讀取,它在網絡中會自然的擁有越多的備份,因為越多的人會樂意去存它,有任何人來讀,我可以提供給他,我可以掙錢。這個機制通過一種由市場驅動的方式實現自適應式的數據冗餘度。
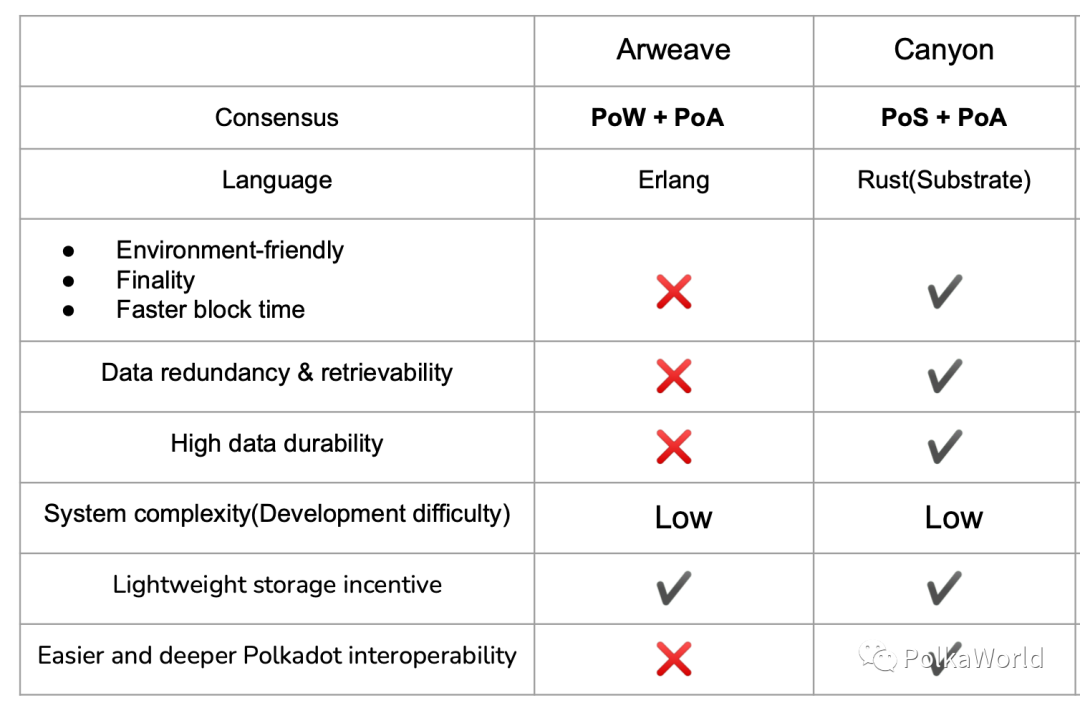
總結起來,首先,不管是熱數據還是冷數據,PoS+PoA 的高數據持久率保證了數據至少存一份,也就是不會丟。通過數據讀取收費解決數據存得盡量多的問題, 如果某個數據經常被用到,經常被讀取,那麼很自然地它就應該擁有更多的數據備份, 也間接實現了存儲資源上的更合理分配。
PW: Canyon 的存儲挖礦對礦工有什麼要求?
留成:得益於超輕量級的存儲共識(PoA), Canyon 對於礦工的硬件要求極低,不需要任何的礦機,不需要指定類型的硬件,只需要任意運行一個普通的PoS 節點配置加上一定容量的硬盤就可以參與挖礦。
PW:Canyon 的代幣有什麼用途?
留成:普通用戶可以使用代幣支付Gas 費,支付存儲和檢索服務的手續費,參與Staking 和鏈上治理等。對於節點用戶,代幣會激勵節點積極參與網絡共識和提供高質量存儲服務,另外節點還可以通過提供檢索服務獲得檢索服務費等。
PW:Canyon 項目是從什麼時候開始的?目前的進展怎麼樣了?
留成:我們是在2020 年底開始研究區塊鏈存儲這個方向,然後今年3 月份左右第一次申請了Web3 基金會Grant。到目前為止我們已經拿到了兩輪Web3 基金會Grant,並且都已經成功交付。我們的第二輪grant 已經基於Substrate 框架實現了PoA 共識, 並實現了與PoS 的融合。
目前整個項目的一些技術難點其實差不多算是已經調研完畢,接下來的融資、組建團隊如果順利的話,預計能在1-2 年內推出主網。
PW:Canyon 為什麼選擇用Substrate 開發?
留成:一個是本身我們在Substrate 生態裡面也好幾年了,比較熟悉這個生態。其次是Substrate 框架還是非常有用的。還有就是看好波卡生態,期待以後可以跟波卡生態項目有更好的互操作性。另外當時我們最早在研究這個項目的時候,波卡里面還沒有做永存的存儲項目,所以我們是波卡生態裡第一個做這個方向的。
本文來自 “PolkaWorld 專訪計劃”,該計劃旨在幫助更多人了解波卡生態新項目,如果你也希望PolkaWorld 來採訪你,可以點此了解詳情和申請。
歡迎學習Substrate: https://substrate.dev/關注Substrate 進展:https://github.com/paritytech/substrate關注Polkadot 進展:https://github.com/paritytech/polkadot














