
TL;DR
1. 我們正在努力構建第一個基於PE-VM的ZKVM,通過ZK-friendly的設計和ZK算法的改進,使它具備更高的吞吐率;其技術特點如下:
a. 證明快:
i. ZK-friendly: 獲得更小的電路規模,以及精簡的底層約束單元;
ii. 更快的ZK實現: 對plonky2的進一步優化改進。
b. 執行快:
採用並行執行的VM(在Parallel prove技術背景下,證明生成時間越短,作用越明顯)。
2. 我們已經做的工作:
a. 2022年7月份,發布了OlaVM的白皮書;
b. 2022年11月份,完成指令集的設計和開發,並初步實現了OlaVM的虛擬機執行模塊, 你可以打開鏈接:https://github.com/Sin7Y/olavm去查看我們的代碼,持續更新中! ! !
c. 針對目前執行效率最快的ZK算法,我們完成plonky2的電路設計及算法研究,你可以打開鏈接:https://github.com/Sin7Y/plonky2/tree/main/plonky2/designs去了解plonky2更多的設計,下一步我們將對其進行優化改進,請持續關注。 。 。
我們正在做什麼?
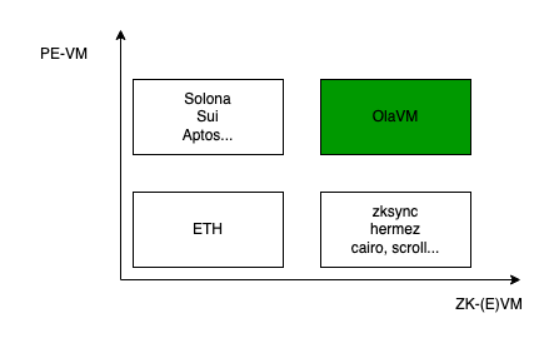
OlaVM是首個把並行執行的VM引入的二層的ZKVM,融合兩種方案的技術點,獲得更快的執行速度和更快的證明速度,從而在未來實現更高的系統吞吐率。
在現在的以太坊系統中,造成吞吐率慢的原因主要有兩個:
1. 共識的過程:每個節點重複執行交易進行交易的有效性校驗;
2. 交易的執行:交易的執行是單線程的。
為了解決問題第1點,且需要同時具備可編程性,許多項目進行了ZK(E)VM的研究,即交易在鏈下完成,鏈上只驗證狀態(當然也有其他的擴容方案,這裡不再過多贅述),但是想要真正提高系統吞吐率,則需要盡可能快的生成證明;為了解決問題第2點,Aptos, Solona, Sui等新公鏈引入了可以並行執行的VM(PE-VM )(當然也包含更快的共識機制)來提高系統的吞吐率。
儘管在現階段,對於ZK(E)VM來講,影響整個系統吞吐率瓶頸在於證明的生成;但是當採用Parallel prove去加快整個系統吞吐率時,區塊生成的越快,則對應的證明生成開始的時間就越早(隨著ZK算法的演進和加速手段的提升,證明生成時間越短,則這個模塊的提升效果越明顯)。
如何獲取高吞吐率?
盡可能快的證明生成(目前最高優先級)
想要加速證明的生成,其大體可以分為兩個部分:盡可能小的電路規模和盡可能快的算法執行;盡可能快的算法執行又可以分為:算法本身參數的提升(比如選擇更小的域)和外部執行環境的改善(比如採用硬件加速)。
1. 盡可能小的約束規模
是的,證明生成的消耗是和約束的整體規模n強相關的,如果能大幅縮減整體的約束規模,則證明的生成的時間則會明顯減少。這就要求,在VM的設計中,你需要使用盡可能多的設計以減少整體的約束規模。
a. Prophet
Prophet的意思為“預言家”,先“預言”再“校驗“,其主要目的是:針對一些複雜的計算,我們不需要用VM的指令去實現這些複雜的計算(可能會消耗很多的指令,從而增大VM的執行軌跡和最終的約束規模);而是利用內置的Prophet去完成計算,並且把結果發送給VM,然後VM只是執行對於這個結果的合法性校驗。 Prophet是一些具備特定計算功能的內置函數,比如除法計算,平方根計算,立方根計算等等,我們會根據實際場景,逐漸豐富Prophets庫,使得對於大部分複雜計算場景,整體約束的縮減效果達到最大化。
b. Zk-friendly
當計算是複雜計算時,Prophet可以幫助縮減VM執行的軌跡大小;但在此之前,我們更希望這個計算本身是Zk-friendly。因此,在設計中,我們會採用一些Zk-friendly的操作,比如常見的哈希算法,驗簽算法等;這些優化也經常存在於其他ZK(E)VM的方案裡;但最終的關鍵就是,當你選擇一個Zk-friendly的複雜計算時,如何用更小的約束去約束這個複雜的計算?
VM本身除了要執行計算邏輯之外,還會有一些其他的操作同樣需要被證明,比如RAM操作。基於堆棧的VM,每次訪問時,都要進行POP,PUSH的操作;而在驗證層面,仍然需要去校驗這個操作的有效性,這些操作會組成獨立的Table,然後用約束去校驗這些堆棧操作的有效性;而基於寄存器的VM,執行相同的邏輯,得到的執行軌跡更小,因此約束規模也更小。
2. 盡可能快的算法執行
ZK算法發展至今,在工程可用性上已經取得了驚人的進展。場景越來越通用,效率越來越高,從R1CS到Plonkish,從較大的域(Cairo VM: P=2 251 +17·2 192 +1)到更小的域(Plonky2: P=2 64 –2 32 +1 );從CPU到GPU/FPGA/ASIC的加速實現,例如Ingonyama的FPGA加速設計和Semisand的ASIC設計等。
由於Plonky2的驚人性能表現,我們暫時以Plonky2作為OlaVM的ZK後端。我們已經深入分析了Plonky2的Gate設計,Gadget設計和協議原理,並從中找到了一些優化方向,你可以關注我們的Github Repo: Plonky2 designs去了解更多相關的信息。
更快的交易執行(現階段不是瓶頸)
在OlaVM的設計中,Prover是無許可的,任何人都可以接入;因此,當你有許多Prover資源時,你可以並行的去為這些區塊生成證明,然後把這些證明聚合在一起,提交到鏈上驗證。由於Prover是可以並行的,因此區塊生成的越快(對應的區塊裡交易執行的越快),對應的證明就可以提前生成,這樣最終鏈上驗證的時間也會提前。
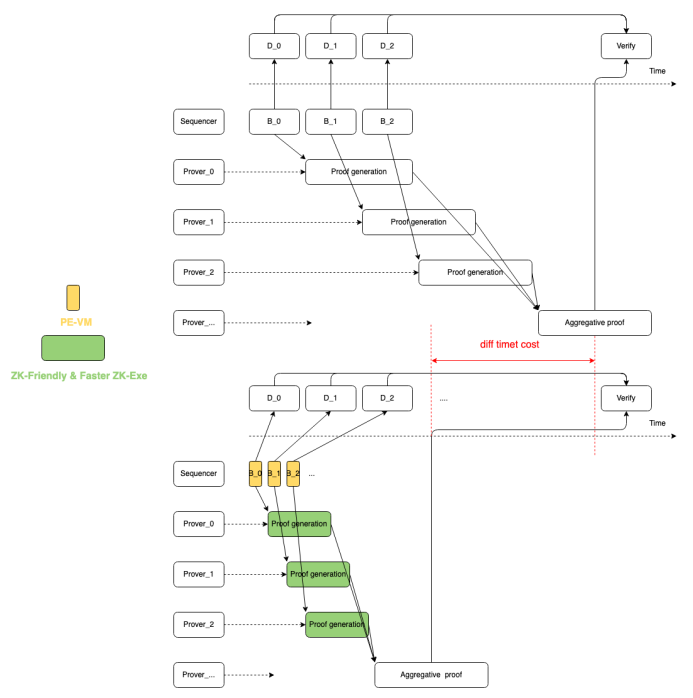
當證明生成需要很久的時候,比如幾個小時,並行執行帶來的提升並不是很明顯;有兩個場景可以提高這種並行帶來的效果,一個是聚合的區塊數量變大,達到量變引起質變;另外一個是證明時間大大縮短。當然兩個提升效果疊加,會更好一些。
兼容性?
對於ZKVM來說,具備某種兼容性是為了方便初期的生態構建,畢竟在區塊鏈行業發展至今,已經有許多成熟的應用部署在現有的系統上,以太坊上的生態更為豐富。因此,能實現對這些既有生態的兼容,使得這些項目可以無縫遷移,對項目初期生態的構建有很大的幫助。
當然,OlaVM的主要目標仍然是構建一個高吞吐的ZKVM,當我們的第一步做的不錯時,我們會考慮去實現兼容性,特別是以太坊的兼容性,這也會在我們的路線圖中。
All Together
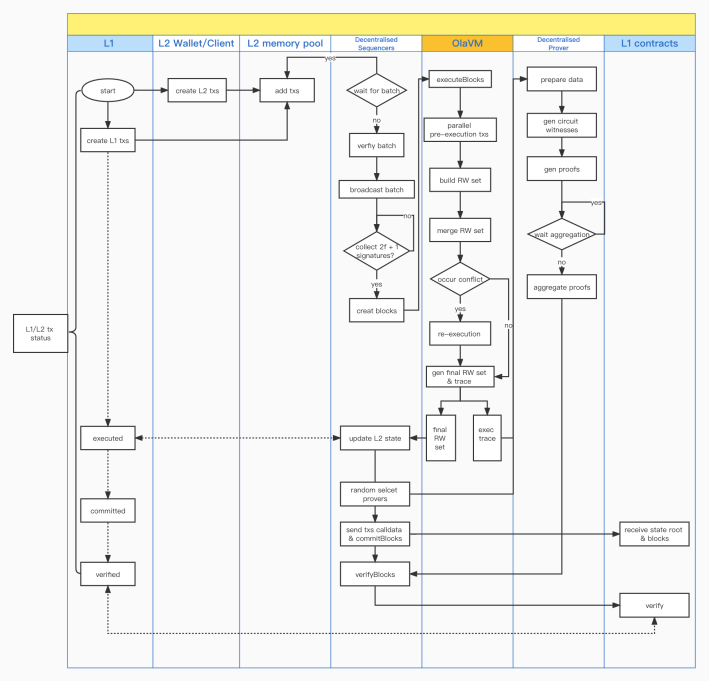
集成上述所有模塊,整個系統的數據流程圖大概如下圖所示:
Coming Soon
1. 2022-12月初:
a. 完成OlaVM DSL設計;
b. 完成OlaVM 預編譯合約的設計和開發;
c. 完成OlaVM 指令約束和Context約束和預編譯合約約束;
d. 完成Plonky2的第一階段優化。
參考
1.OlaVM: https://olavm.org/whitepaper/OlaVM-07-25.pdf
2.Plonkish: https://zcash.github.io/halo2/concepts/arithmetization.html
3.Cairo VM: https://starknet.io/docs/how_cairo_works/cairo_intro.html#field-elements
4.Plonky2: https://github.com/Sin7Y/plonky2/blob/main/field/src/goldilocks_field.rs
5.Ingonyama: https://github.com/ingonyama-zk/cloud-ZK
6.Semisand: https://semisand.com/
7.Plonky2 designs: https://github.com/Sin7Y/plonky2/tree/main/plonky2/designs
關於我們
Sin7y成立於2021年,由頂尖的區塊鏈開發者組成。我們既是項目孵化器也是區塊鏈技術研究團隊,探索EVM、Layer2、跨鏈、隱私計算、自主支付解決方案等最重要和最前沿的技術。團隊於2022年7月推出OlaVM白皮書,致力於打造首個快速、可擴展且兼容EVM的ZKVM。











