





撰文:Jeff Amico
編譯:深潮TechFlow
引言
在新冠疫情期間,Folding@home 取得了一個重大里程碑。研究計畫獲得了2.4 exaFLOPS 的運算能力,由全球200 萬台志工設備提供。這代表了當時世界上最大超級電腦的十五倍處理能力,使科學家能夠大規模模擬COVID 蛋白質動態。他們的工作推動了我們對病毒及其病理機制的理解,尤其是在疫情初期。
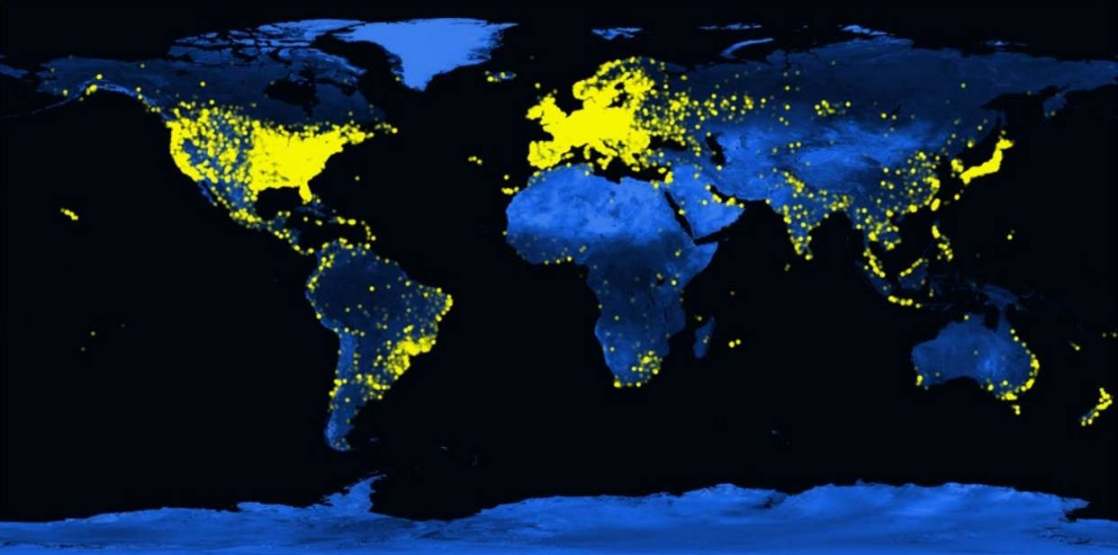
Folding@home 用戶的全球分佈,2021
Folding@home 基於志願運算的悠久歷史,專案透過眾包運算資源來解決大規模問題。這個想法在1990 年代的SETI@home 中得到了廣泛關注,該計畫匯集了超過500 萬台志願者電腦以尋找外星生命。此後,這一理念已被應用於多個領域,包括天文物理學、分子生物學、數學、密碼學和遊戲。在每種情況下,集體力量增強了單一項目的能力,遠遠超出了他們單獨能夠實現的範圍。這推動了進步,使研究能夠以更開放和合作的方式進行。
許多人想知道我們是否可以將這個眾包模型應用於深度學習。換句話說,我們能否在大眾中訓練一個大型神經網路?前沿模型訓練是人類歷史上計算最密集的任務之一。與許多@home 專案一樣,目前的成本超出了只有最大參與者才能承擔的範圍。這可能會阻礙未來的進展,因為我們依賴越來越少的公司來尋找新的突破。這也將我們的AI 系統的控制權集中在少數人手中。無論你對這項技術的看法如何,這都是一個值得關注的未來。
大多數批評者駁斥了去中心化訓練的想法,認為與目前的訓練技術不相容。然而,這種觀點已經越來越過時。新的技術已經出現,能夠減少節點間的通訊需求,從而允許在網路連接不佳的設備上有效訓練。這些技術包括DiLoCo 、 SWARM Parallelism 、 lo-fi 和異質環境中基礎模型的分散訓練等多種技術。其中許多具有容錯性,並支援異構計算。還有一些新架構專為去中心化網路設計,包括DiPaCo 和去中心化混合專家模型。
我們也看到各種加密原語開始成熟,使得網路能夠在全球範圍內協調資源。這些技術支援數位貨幣、跨境支付和預測市場等應用情境。與早期的志工計畫不同,這些網路能夠匯聚驚人的運算能力,通常比目前設想的最大雲端訓練集群大幾個數量級。
這些要素共同構成了新的模式訓練範式。這種範式充分利用全球的運算資源,包括如果連接在一起可以使用的大量邊緣設備。這將透過引入新的競爭機制來降低大多數訓練工作負載的成本。它還可以解鎖新的訓練形式,使得模型開發變得協作和模組化,而不是孤立和單一的方式。模型可以從大眾中取得計算和數據,即時學習。個人可以擁有他們所創建模型的一部分。研究人員也可以重新公開分享新穎的研究成果,而無需透過貨幣化他們的發現來彌補高昂的運算預算。
本報告檢視了大型模型訓練的現況及相關成本。它回顧了以往的分散式運算努力——從SETI 到Folding 再到BOINC——以此為靈感探索替代路徑。報告討論了去中心化訓練的歷史挑戰,並轉向可能有助於克服這些挑戰的最新突破。最後,它總結了未來的機會與挑戰。
前沿模型訓練的現狀
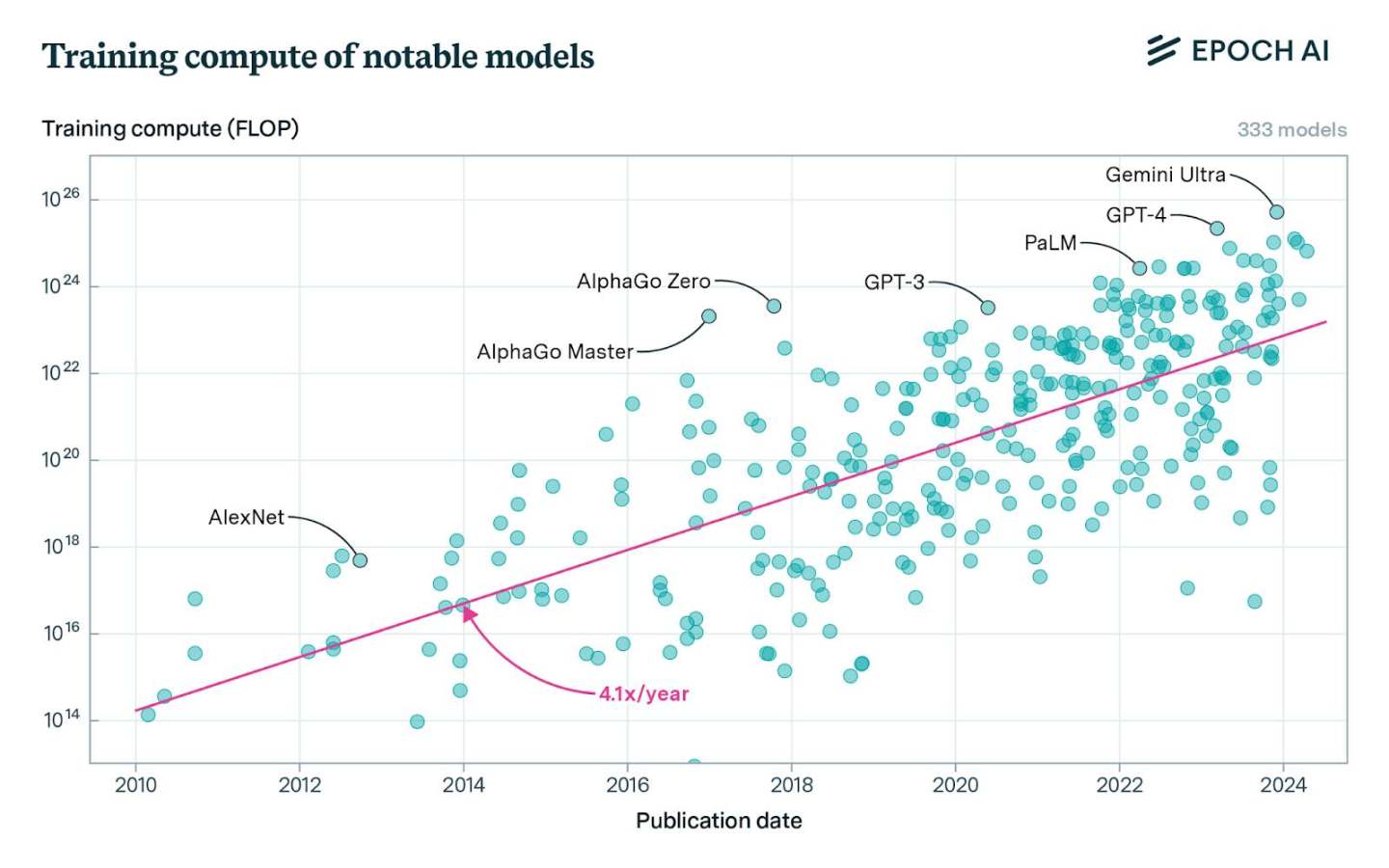
前緣模型訓練的成本對非大型參與者而言已經不可承受。這個趨勢並不新鮮,但根據實際情況,情況正在變得更加嚴重,因為前沿實驗室不斷挑戰擴展假設。據報道,OpenAI 今年在訓練方面花費超過30 億美元。 Anthropic 預測到2025 年,我們將開始進行100 億美元的訓練,而1000 億美元的模型也不會太遠。
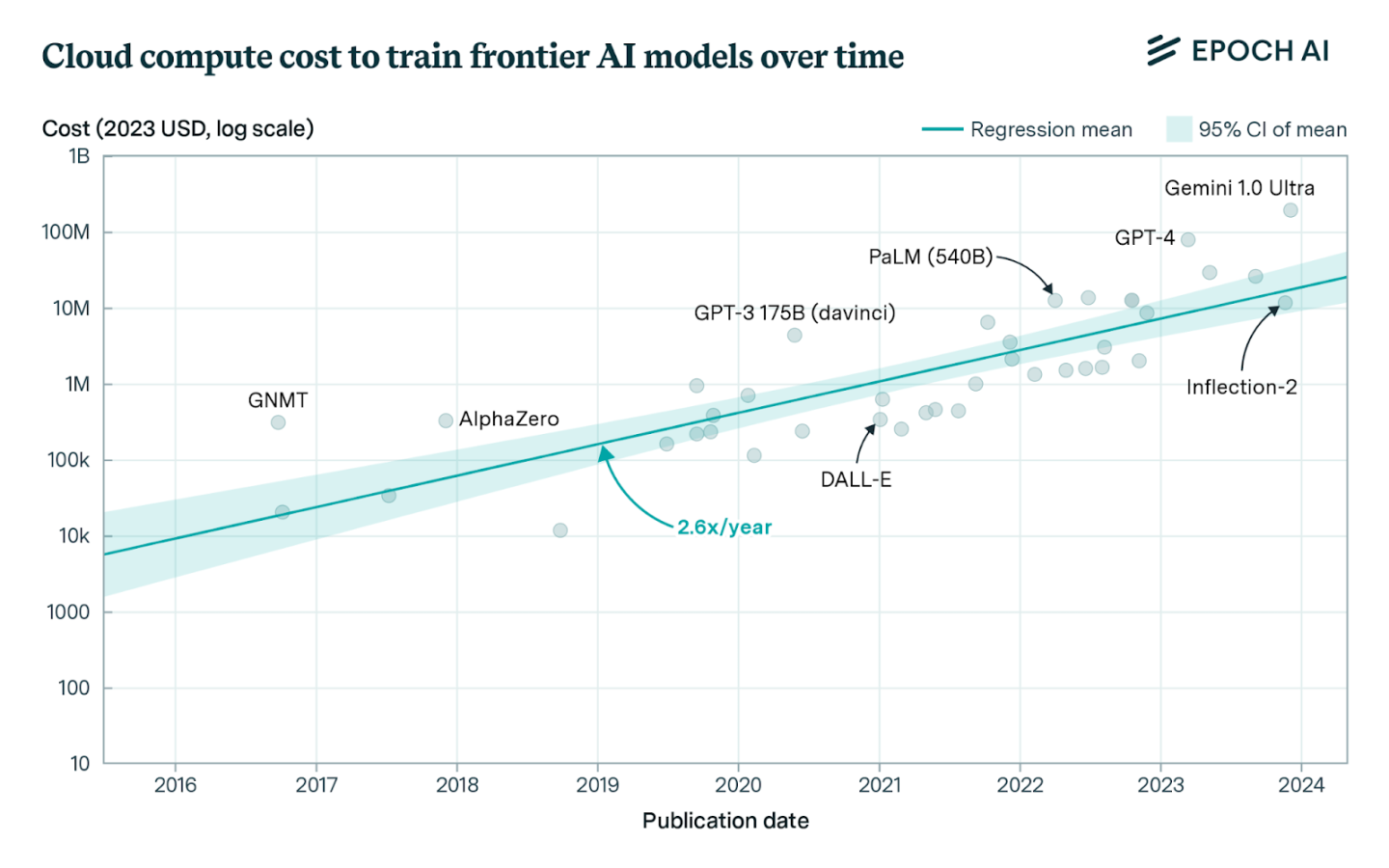
這一趨勢導致行業的集中化,因為只有少數幾家公司能夠承擔參與的費用。這引發了未來的核心政策問題——我們是否能接受所有領先的AI 系統由一兩家公司控制的局面?這也限制了進展速度,這一點在研究社群中顯而易見,因為較小的實驗室無法承擔擴展實驗所需的運算資源。產業領導者也多次提到這一點:
Meta 的Joe Spisak:要真正理解[模型] 架構的能力,你必須在規模上進行探索,我認為這正是當前生態系統中所缺少的。如果你看看學術界——學術界有很多傑出的人才,但他們缺乏計算資源的訪問,這就成了一個問題,因為他們有這些偉大的想法,卻沒有真正以所需水平實現這些想法的途徑。
Together 的Max Ryabinin:對昂貴硬體的需求給研究社群帶來了極大壓力。大多數研究人員無法參與大型神經網路開發,因為進行必要的實驗對他們而言成本過高。如果我們繼續透過擴大模型規模來增加其大小,最終能夠進行競
Google 的Francois Chollet:我們知道大語言模型(LLMs) 尚未實作通用人工智慧(AGI)。同時,朝AGI 發展的進展已經停滯。我們在大語言模型上所面臨的限制與五年前面臨的限製完全相同。我們需要新的想法和突破。我認為下一個突破很可能來自外部團隊,而所有大型實驗室則忙於訓練更大的大語言模型。 有些人對這些擔憂持懷疑態度,認為硬體改善和雲端運算資本支出將解決這個問題。但這似乎不太現實。一方面,到本十年末,新一代Nvidia 晶片的FLOP 數量將大幅增加,可能達到今天H100 的10 倍。這將使每FLOP 的價格下降80-90%。同樣,預計到本十年末,總FLOP 供應將增加約20 倍,同時改善網路和相關基礎設施。所有這些都將提高每美元的訓練效率。
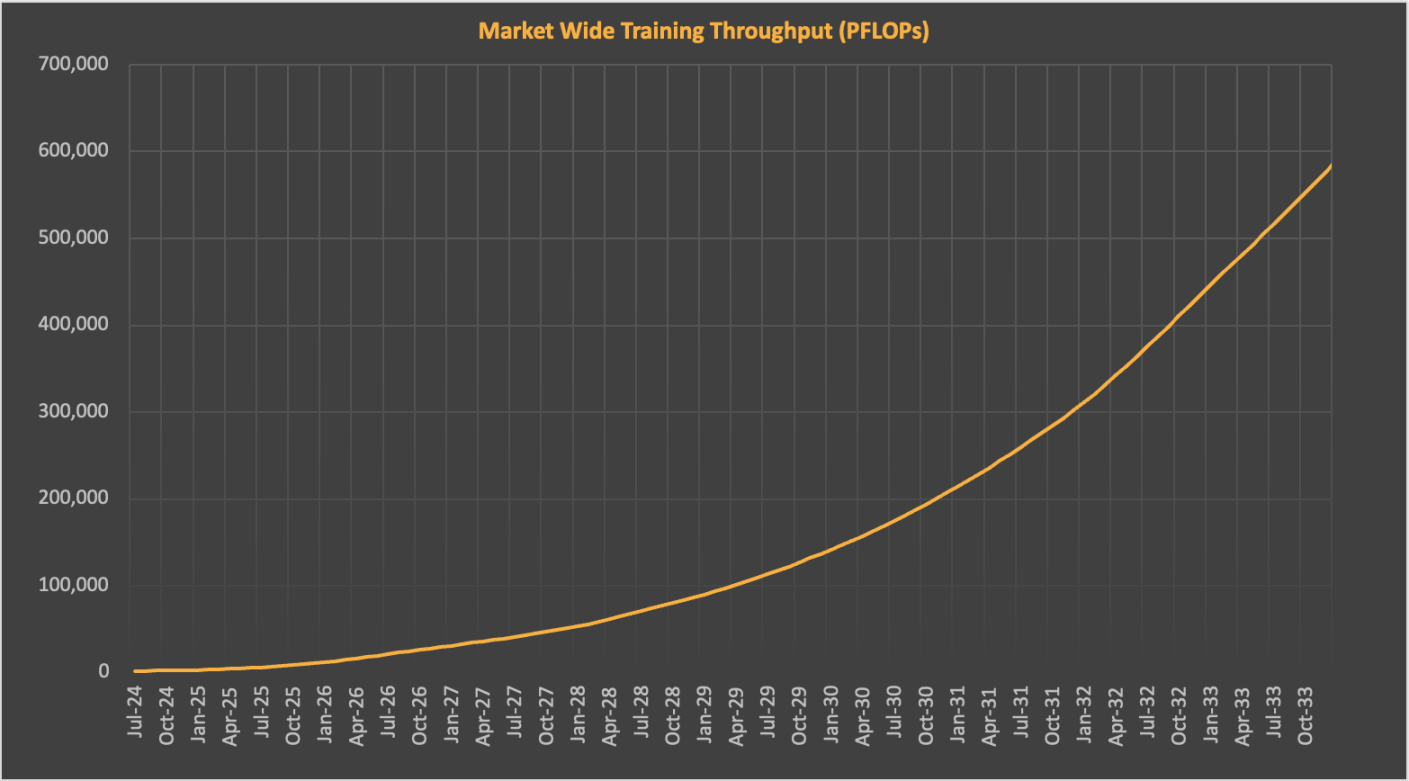
資料來源:SemiAnalysis AI Cloud TCO 模型
同時,總FLOP 需求也將大幅上升,因為實驗室希望進一步擴大規模。如果持續十年的訓練運算趨勢保持不變,到2030 年前緣訓練的FLOPs 預計將達到約2e29。進行這種規模的訓練大約需要2,000 萬個H100 等效GPU,依據目前的訓練運行時間和使用率。假設這一領域仍有多個前沿實驗室,總所需的FLOPS 數量將會是這個數字的幾倍,因為整體供應將在它們之間分配。 EpochAI 預測到那時我們需要大約1 億個H100 等效GPU,約為2024 年出貨量的50 倍。 SemiAnalysis 也做出了類似的預測,認為前緣訓練需求和GPU 供應在此期間大致同步成長。
產能狀況可能會因多種原因而變得更加緊張。例如,如果製造瓶頸延遲了預計的出貨週期,這種情況是常有的事。或者如果我們未能生產足夠的能源來為資料中心供電。又或者如果我們在將這些能源來源連接到電網方面遇到困難。或者如果對資本支出的日益審查最終導致行業縮減規模,等等因素。在最好的情況下,我們目前的方法只能讓少數公司繼續推動研究的進展,而這可能還不夠。
顯然,我們需要一種新的方法。這種方法不需要不斷擴展資料中心、資本支出和能源消耗來尋找下一個突破,而是有效利用我們現有的基礎設施,能夠隨著需求的波動靈活擴展。這將讓研究中有更多實驗的可能,因為訓練運行不再需要確保億萬美元計算預算的投資回報。一旦擺脫這個限制,我們可以超越目前的大語言模型(LLM) 模式,正如許多人所認為的,實現通用人工智慧(AGI) 是必要的。為了理解這種替代方案可能呈現的樣子,我們可以從過去的分散式運算實踐中汲取靈感。
群體計算:簡史
SETI@home 在1999 年普及了這個概念,讓數百萬參與者分析無線電訊號,尋找外星智慧。 SETI 從Arecibo 望遠鏡收集電磁數據,將其分成若干批次,並透過網路傳送給使用者。用戶在日常活動中分析數據,並將結果傳回。用戶之間無需溝通,批次可以獨立審核,從而實現高度的並行處理。在其巔峰時刻,SETI@home 擁有超過500 萬名參與者,處理能力超過當時最大的超級電腦。它最終在2020 年3 月關閉,但它的成功激勵了隨後的志願計算運動。
Folding@home 在2000 年延續了這個理念,利用邊緣運算模擬阿茲海默症、癌症和帕金森氏症等疾病的蛋白質摺疊。志願者在個人電腦的空閒時間進行蛋白質模擬,幫助研究人員研究蛋白質如何錯誤折疊並導致疾病。在其歷史的不同時間段,其計算能力超過了當時最大的超級計算機,包括在2000 年代後期和COVID 期間,當時它成為第一個超過一exaFLOPS 的分散式計算項目。自成立以來,Folding 的研究人員已發表超過200 篇同行評審論文,每一篇都依賴志工的運算能力。
伯克利開放網路運算基礎設施(BOINC) 在2002 年普及了這個概念,提供了一個眾包運算平台,用於各種研究計畫。它支援SETI@home 和Folding@home 等多個項目,以及在天文物理學、分子生物學、數學和密碼學等領域的新項目。到2024 年,BOINC 列出了30 個正在進行的項目,以及近1,000 篇發表的科學論文,均利用其計算網絡產生。
在科學研究領域之外,志願計算被用於訓練圍棋(LeelaZero、KataGo)和國際象棋(Stockfish、LeelaChessZero)等遊戲引擎。 LeelaZero 透過志願計算從2017 年到2021 年進行訓練,使其能夠與自己下棋超過一千萬局,創造了今天最強的圍棋引擎之一。類似地,Stockfish 自2013 年以來一直在志願網絡上持續訓練,使其成為最受歡迎和最強大的國際象棋引擎之一。
關於深度學習的挑戰
但是我們能否將此模型應用於深度學習?我們是否可以將世界各地的邊緣設備連網,創造一個低成本的公共訓練集群?消費者硬體——從蘋果筆記本到Nvidia 遊戲顯示卡——在深度學習方面的表現越來越出色。在許多情況下,這些設備的效能甚至超過了資料中心顯示卡的每美元效能。
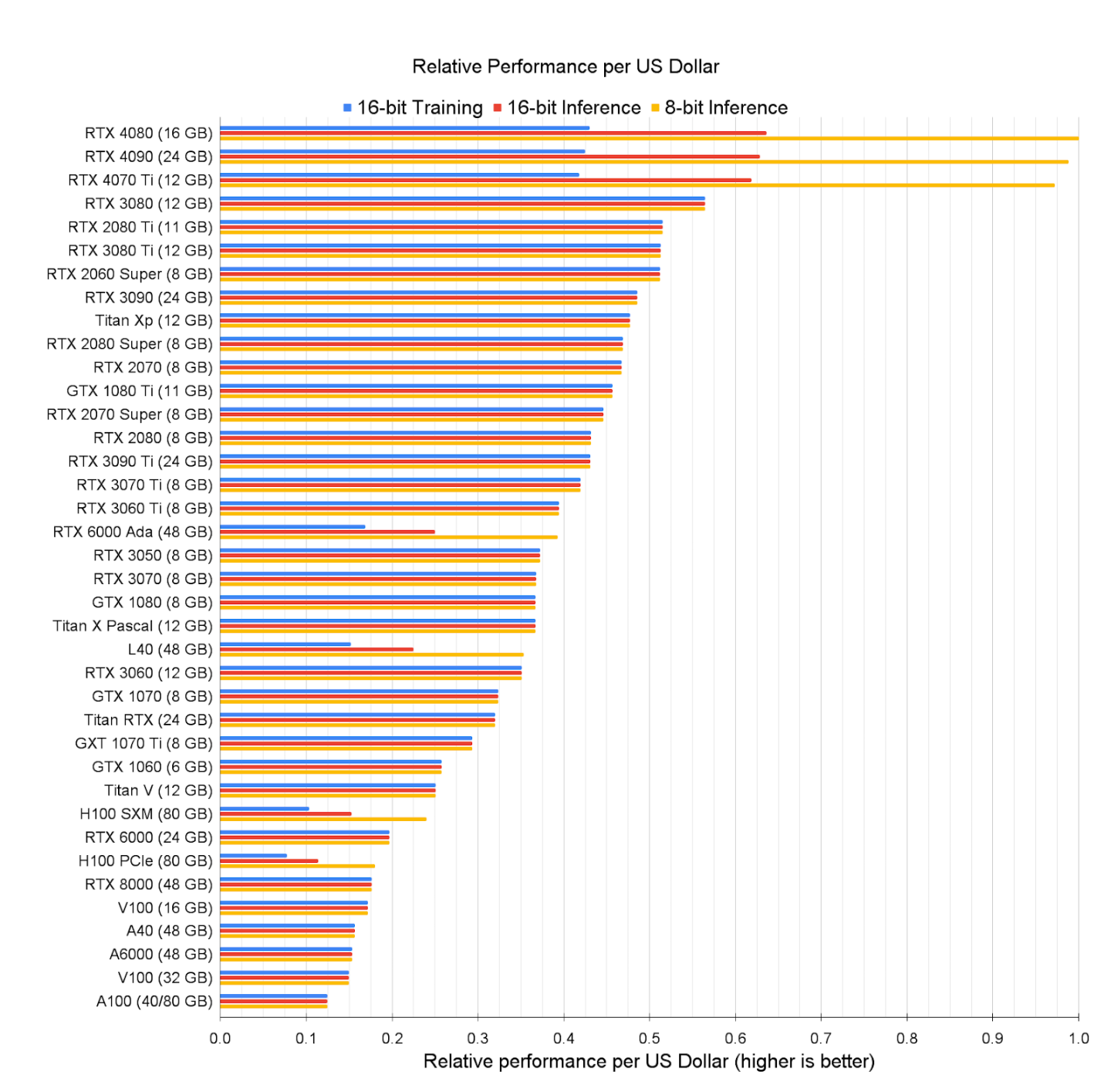
然而,要有效利用這些資源在分散式環境中,我們需要克服各種挑戰。
首先,目前的分散式訓練技術假設節點之間存在頻繁的通訊。
目前最先進的模型已經變得如此龐大,以至於訓練必須拆分到數千個GPU 之間。這是透過多種平行化技術來實現的,通常是在可用的GPU 之間拆分模型、資料集或同時拆分兩者。這通常需要高頻寬和低延遲的網絡,否則節點將閒置,等待資料到來。
例如,分散式資料並行技術(DDP) 將資料集分配到各個GPU 上,每個GPU 在其特定的資料片段上訓練完整的模型,然後共享其梯度更新,以產生各個步驟的新模型權重。這需要相對有限的通訊開銷,因為節點僅在每次反向傳播後共享梯度更新,並且集體通訊操作可以部分與計算重疊。然而,這種方法僅適用於較小的模型,因為它要求每個GPU 在記憶體中儲存整個模型的權重、啟動值和最佳化器狀態。例如,GPT-4 在訓練時需要超過10TB 的內存,而單一H100 僅有80GB。
為了解決這個問題,我們還使用各種技術對模型進行拆分,以便在GPU 之間進行分配。例如,張量並行技術(tensor parallelism) 在單一層內拆分各個權重,使得每個GPU 執行必要的操作並將輸出傳遞給其他的GPU。這降低了每個GPU 的記憶體需求,但需要它們之間進行持續的通訊往來,因此需要高頻寬、低延遲的連線以提高效率。
管線並行技術(pipeline parallelism) 將模型的層分配到各個GPU 上,每個GPU 執行其工作並與管線中的下一個GPU 共享更新。儘管這所需的通訊量比張量並行更少,但可能會出現「氣泡」(例如,空閒時間),在這種情況下,位於流水線後面的GPU 會等待來自前面GPU 的訊息,以便開始其工作。
為了解決這些挑戰,發展出各種技術。例如,ZeRO(零冗餘優化器)是一種記憶體優化技術,它透過增加通訊開銷來減少記憶體使用,從而使更大的模型能夠在特定設備上進行訓練。 ZeRO 透過在GPU 之間分割模型參數、梯度和最佳化器狀態來降低記憶體需求,但依賴大量的通信,以便設備能夠獲取分割的資料。它是流行技術如完全分片資料並行(FSDP) 和DeepSpeed 的基礎方法。
這些技術通常在大模型訓練中結合使用,以最大化資源的利用效率,稱為3D 並行。在這種配置中,張量並行技術(tensor parallelism) 通常用於在單一伺服器內將權重分配到各個GPU 上,因為在每個被分割的層之間需要大量通訊。然後,管線並行技術(pipeline parallelism) 被用來在不同伺服器之間(但在資料中心的同一島嶼內)分配層,因為它所需的通訊量較少。接著,資料並行技術(data parallelism) 或完全分片資料並行技術(FSDP) 被用來在不同伺服器島嶼之間拆分資料集,因為它可以透過非同步共享更新和/ 或壓縮梯度來適應更長的網路延遲。 Meta 使用這種組合方法來訓練Llama 3.1,如下面的圖示所示。
這些方法為去中心化訓練網路帶來了核心挑戰,這些網路依賴於透過(速度更慢且波動更大的)消費級網路連接的設備。在這種環境中,通訊成本很快就會超過邊緣運算帶來的效益,因為設備通常是空閒的,等待資料到達。以一個簡單的例子說明,分散式資料並行訓練一個具有10 億參數的半精度模型,每個GPU 在每個最佳化步驟中需要共享2GB 的資料。以典型的網路頻寬(例如1 千兆位元每秒)為例,假設計算與通訊不重疊,傳輸梯度更新至少需要16 秒,導致顯著的空閒。像張量並行技術(tensor parallelism) 這樣的技術(需要更多的通訊)當然會表現得更糟。
其次,目前的訓練技術缺乏容錯能力。像任何分散式系統一樣,隨著規模的增加,訓練叢集變得更容易發生故障。然而,這個問題在訓練中更加嚴重,因為我們目前的技術主要是同步的,這意味著GPU 必須協同工作以完成模型訓練。成千上萬的GPU 中單一GPU 的故障會導致整個訓練過程停止,迫使其他GPU 從頭開始訓練。在某些情況下,GPU 並不會完全故障,而是因為各種原因變得遲緩,進而減慢叢集中成千上萬其他GPU 的速度。考慮到當今集群的規模,這可能意味著數千萬到數億美元的額外成本。
Meta 在他們的Llama 訓練過程中詳細闡述了這些問題,他們經歷了超過400 次意外中斷,平均每天約8 次中斷。這些中斷主要歸因於硬體問題,例如GPU 或主機硬體故障。這導致他們的GPU 使用率僅為38-43%。 OpenAI 在GPT-4 的訓練過程中表現較差,僅32-36%,這也是由於訓練過程中故障頻繁。
換句話說,前沿實驗室們在完全優化的環境中(包括同質的、最先進的硬體、網路、電源和冷卻系統)進行訓練時,仍然難以達到40% 的利用率。這主要歸因於硬體故障和網路問題,而在邊緣訓練環境中,這些問題會更加嚴重,因為設備在處理能力、頻寬、延遲和可靠性方面存在不均衡。更不用說,去中心化網路容易受到惡意行為者的侵害,他們可能出於各種原因試圖破壞整體專案或在特定工作負載上作弊。即使是純志工網路SETI@home,也曾出現不同參與者的作弊現象。
第三,前沿模型訓練需要大規模的運算能力。雖然像SETI 和Folding 這樣的專案達到了令人印象深刻的規模,但與當今前沿訓練所需的運算能力相比,它們相形見絀。 GPT-4 在一個由20,000 個A100 組成的集群上訓練,其峰值吞吐量為半精度的6.28 ExaFLOPS。這比Folding@home 在其峰值時的運算能力多出三倍。 Llama 405b 使用16,000 個H100 進行訓練,峰值吞吐量為15.8 ExaFLOPS,是Folding 峰值的7 倍。隨著多個實驗室計劃建造超過100,000 個H100 的集群,這一差距只會進一步擴大,每個集群的運算能力高達驚人的99 ExaFLOPS。
這很有道理,因為@home 計畫是志工驅動的。貢獻者捐贈了他們的記憶體和處理器週期,並承擔了相關成本。這自然限制了它們相對於商業項目的規模。
最近的進展
雖然這些問題在歷史上一直困擾著去中心化訓練工作,但它們似乎不再不可逾越。新的訓練技術已經出現,能夠減少節點間的通訊需求,從而在網路連接的設備上進行高效訓練。這些技術許多源自於大型實驗室,它們希望為模型訓練增加更大的規模,因此需要跨資料中心的高效通訊技術。我們也看到了容錯訓練方法和加密激勵系統的進展,這些方法可以支援更大規模的訓練在邊緣環境中進行。
高效通訊技術
DiLoCo 是Google近期的研究,它透過在裝置間傳遞更新的模型狀態之前進行本地最佳化,從而減少了通訊開銷。他們的方法(基於早期的聯邦學習研究)顯示出與傳統同步訓練相當的效果,同時節點之間的通訊量降低了500 倍。此後,該方法已被其他研究者複製,並擴展至訓練更大模型(超過10 億個參數)。它還擴展到非同步訓練,這意味著節點可以在不同時間共享梯度更新,而不是一次共享所有更新。這更適應了處理能力和網路速度各異的邊緣硬體。
其他資料並行方法,如lo-fi 和DisTrO,旨在進一步減少通訊成本。 Lo-fi 提出了完全局部微調的方法,這意味著節點獨立訓練,只在最後傳遞權重。這種方法在微調超過10 億參數的語言模型時,效能與基準相當,同時完全消除了通訊開銷。在一份初步報告中,DisTrO 聲稱採用了一種新型的分散式優化器,他們認為可以將通訊需求降低四到五個數量級,儘管該方法仍有待確認。
新的模型並行方法也已經出現,這使得實現更大的規模成為可能。 DiPaCo(同樣來自Google)將模型劃分為多個模組,每個模組包含不同的專家模組,以便於特定任務的訓練。然後,訓練資料透過「路徑」進行分片,這些路徑是每個資料樣本對應的專家序列。給定一個分片,每個工作者幾乎可以獨立訓練特定的路徑,除了共享模組所需的通信,這部分由DiLoCo 處理。這種架構將十億參數模型的訓練時間減少了超過一半。
SWARM 平行性和異質環境中基礎模型的去中心化訓練(DTFMHE) 也提出了模型並行的方法,以在異質環境中實現大模型訓練。 SWARM 發現,隨著模型規模的增加,管道並行性通訊約束會減小,這使得在較低的網路頻寬和更高的延遲下有效訓練更大模型成為可能。為了在異質環境中應用這一理念,他們在節點之間使用臨時“管道連接”,這些管道可以在每次迭代中即時更新。這允許節點將其輸出發送到任何下一個管道階段的對等節點。這意味著,如果某個對等節點比其他節點更快,或者任何參與者斷開連接,輸出可以動態重新路由,以確保訓練的持續進行,只要每個階段至少有一個活躍參與者。他們使用這種方法在低成本的異構GPU 上訓練一個超過10 億參數的模型,並且互連速度較慢(如下圖所示)。
DTFMHE 同樣提出了一種新穎的調度演算法,以及管道並行和資料並行,以在3 個大洲的設備上訓練大型模型。儘管他們的網路速度比標準Deepspeed 慢100 倍,但他們的方法速度僅比在資料中心使用標準Deepspeed 慢1.7-3.5 倍。與SWARM 類似,DTFMHE 顯示隨著模型規模增大,通訊成本可以有效隱藏,即使在地理分佈的網路中也同樣適用。這使得我們能夠透過各種技術克服節點之間較弱的連接,包括增加隱藏層的大小和每個管道階段增加更多層。
故障容錯
上述許多資料並行方法預設具有容錯能力,因為每個節點都在記憶體中儲存整個模型。這種冗餘通常意味著,即使其他節點發生故障,節點仍然可以獨立工作。這對於去中心化訓練非常重要,因為節點通常是不可靠的、異質的,甚至可能存在惡意行為。然而,如前所述,純資料並行方法僅適用於較小的模型,因此模型大小受到網路中最小節點記憶體容量的限制。
為了解決上述問題,有些人提出了適用於模型並行(或混合併行)訓練的容錯技術。 SWARM 透過優先選擇延遲較低的穩定對等節點來應對對等節點故障,並在發生故障時重新路由管道階段的任務。其他方法,如Oobleck,採用類似的方法,透過建立多個「管道模板」來提供冗餘,以應對部分節點故障。儘管在資料中心進行了測試,Oobleck 的方法提供了強大的可靠性保證,這些保證同樣適用於去中心化環境。
我們也看到了一些新的模型架構(如去中心化混合專家模型(Decentralized Mixture of Experts, DMoE)),用於支援去中心化環境中的容錯訓練。與傳統的專家混合模型類似,DMoE 由多個獨立的「專家」網路組成,這些網路分佈在一組工作者節點上。 DMoE 使用分散式雜湊表以去中心化方式追蹤和整合非同步更新。該機制(在SWARM 中也使用)對節點故障具有良好的抵抗力,因為如果某些節點失敗或未能及時響應,它可以將某些專家排除在平均計算之外。
規模化
最後,像比特幣和以太坊所採用的加密激勵系統可以幫助實現所需的規模。這兩個網路透過向貢獻者支付一種可以隨著採用成長而增值的本地資產來眾包計算。這個設計透過給予早期貢獻者豐厚獎勵來激勵他們,當網路達到最小可行規模後,這些獎勵可以逐步減少。
確實,這種機制有各種陷阱,需要避免。其中最主要的陷阱是,過度激勵供給而未能帶來相應的需求。此外,如果基礎網路不夠去中心化,這可能引發監管問題。然而,當設計得當時,去中心化激勵系統可以在較長時間內實現可觀的規模。
例如,比特幣年電力消耗約為150 太瓦時(TWh),比目前構思中的最大AI 訓練集群的電力消耗高出兩個數量級之多(100,000 個H100 全負荷運行一年)。作為參考,OpenAI 的GPT-4 在20,000 個A100 上進行了訓練,Meta 的旗艦Llama 405B 模型在16,000 個H100 上進行了訓練。同樣,在其高峰期,以太坊的電力消耗約為70 TWh,分散在數百萬個GPU 之間。即使考慮到未來幾年AI 資料中心的快速成長,像這些激勵運算網路仍將多次超越其規模。
當然,並非所有計算都是可替換的,訓練相對於挖礦有獨特的需求,需要考慮。儘管如此,這些網路展示了透過這些機制可以實現的規模。
未來的道路
將這些部分連結在一起,我們可以看到前進的新道路的開端。
很快,新的訓練技術將使我們能夠超越資料中心的限制,因為設備不再需要共同放置才能發揮作用。這將需要時間,因為我們目前的去中心化訓練方法仍處於較小規模,主要在10 億到20 億個參數的範圍內,比像GPT-4 這樣的模型小得多。我們需要進一步的突破,以在不犧牲關鍵屬性(如通訊效率和容錯能力)的情況下提升這些方法的規模。或者,我們需要新的模型架構,這些架構與今天的大型單體模型有所不同——可能更小、更模組化,在邊緣設備上運行,而不是在雲端
無論如何,可以合理地預期在這個方向上會有進一步的進展。我們目前方法的成本是不可持續的,這為創新提供了強烈的市場動力。我們已經看到這一趨勢,像Apple 這樣的製造商正在建立更強大的邊緣設備,以便在本地運行更多的工作負載,而不是依賴雲端。我們也看到對開源解決方案的支援不斷增加——甚至在像Meta 這樣的公司內部,以促進更去中心化的研究與開發。這些趨勢隨著時間的推移只會加速。
同時,我們也需要新的網路基礎設施來連接邊緣設備,以便能夠這樣使用它們。這些設備包括筆記型電腦、遊戲桌上型電腦,最終甚至可能是擁有高效能顯示卡和大內存的手機。這將使我們能夠建立一個「全球集群」,低成本、始終在線的運算能力,可以並行處理訓練任務。這也是一個具有挑戰性的問題,需要在多個領域取得進展。
我們需要更好的調度技術來在異質環境中進行訓練。目前沒有任何方法可以自動並行化模型以達到最佳化,特別是在設備可以隨時斷開或連接的情況下。這是優化訓練的關鍵下一步,同時保留基於邊緣網路的規模優勢。
我們也必須應對去中心化網路的一般複雜性。為了最大化規模,網路應該建構成開放協議——一套標準和指令,規定參與者之間的互動,就像TCP/IP 而是用於機器學習計算。這將使任何遵循特定規範的設備能夠連接到網絡,無論擁有者和位置。它還確保網路保持中立,允許用戶訓練他們喜歡的模型。
雖然這實現了規模最大化,但它也需要一個機制來驗證所有訓練任務的正確性,而不依賴單一實體。這一點至關重要,因為存在固有的作弊誘因——例如,聲稱自己完成了某個訓練任務以獲得報酬,但實際上並沒有做到。考慮到不同設備通常以不同方式執行機器學習操作,這使得使用標準複製技術難以驗證正確性,因此這尤其具有挑戰性。正確解決這個問題需要在密碼學和其他學科上進行深入研究。
幸運的是,我們在所有這些方面都繼續看到進展。與過去幾年相比,這些挑戰似乎不再是不可逾越。與機會相比,它們也顯得相當微小。 Google 在他們的DiPaCo 論文中對此進行了最佳總結,指出去中心化訓練有潛力打破的負回饋機制:
分散式訓練機器學習模型的進展可能促進基礎設施的簡化建設,最終導致計算資源的更廣泛可用。目前,基礎設施是圍繞著訓練大型單體模型的標準方法而設計的,同時機器學習模型的架構也旨在利用當前的基礎設施和訓練方法。這種回饋循環可能使社群陷入一個誤導性的局部最小值,即計算資源的限制超過了實際需求。
也許最令人興奮的是,研究界對解決這些問題的熱情日益高漲。我們在Gensyn 的團隊正在建立上述網路基礎設施。像Hivemind 和BigScience 這樣的團隊在實踐中應用了許多這些技術。像Petals、sahajBERT 和Bloom 這樣的專案展示了這些技術的能力,以及對社區為基礎的機器學習日益增長的興趣。還有許多其他人也在推動研究進展,目標是建立一個更開放、更協作的模型來訓練生態系統。如果您對這項工作感興趣,請與我們聯繫以參與其中。







 APP
APP 
