
鏈上數據處理面臨的挑戰
區塊鏈數據公司,在索引以及處理鏈上數據時,可能會面臨一些挑戰,包括:
海量數據。隨著區塊鏈上數據量的增加,數據索引將需要擴大規模以處理增加的負載並提供對數據的有效訪問。因此,它導致了更高的存儲成本;緩慢的指標計算和增加數據庫服務器的負載。
複雜的數據生產流程。區塊鏈技術是複雜的,建立一個全面和可靠的數據索引需要對底層數據結構和算法有深刻的理解。這是由區塊鏈實現方式的多樣性所決定的。舉一個具體的例子,以太坊中的NFT 通常是在遵循ERC721 和ERC1155 格式的智能合約中進行創建的,而像Polkadot 上通常是直接在區塊鏈運行時間內構建的。對於用戶來說,不管是任何形式的存在,這些數據應該被視為NFT 的交易,需要被存儲,並且處理為可讀狀態,方便分析以及進行計算。
集成能力。為了給用戶提供最大的價值,區塊鏈索引解決方案可能需要將其數據索引與其他系統集成,如分析平台或API。這很有挑戰性,需要在架構設計上投入大量精力。
隨著區塊鏈技術的使用越來越廣泛,存儲在區塊鏈上的數據量也在增加。這是因為更多的人在使用該技術,而每筆交易都會給區塊鏈增加新的數據。此外,區塊鏈技術的使用已經從簡單的資金轉移應用,如涉及使用比特幣的應用,發展到更複雜的應用,包括智能合約之間的相互調用。這些智能合約可以產生大量的數據,從而造成了區塊鏈數據的複雜性和規模的增加。隨著時間的推移,這導致了更大、更複雜的區塊鏈數據。
本文中,我們將以Footprint Analytics 的技術架構演變作為分析案例,探索Iceberg-Trino 如何解決鏈上數據面臨的挑戰。
Footprint Analytics 擁有最全面的鏈上數據索引倉庫,目前涵蓋22 個公鏈,17 個NFT 市場,超過1900 個GameFi 項目,以及超過66 萬個NFT 收藏。當我們談及22 條公鏈底層數據時,不同與其他行業,區塊鏈的數據大部分都是交易數據,而非單純傳統行業的日誌數據,22 條公鏈大概數量級行數大概是200 億以上,而這些是經常需要被查詢的數據。
在過去幾個月中,我們經歷了以下三次大的系統版本升級,以滿足不斷增長的業務需求:
架構1.0 Bigquery
在Footprint Analytics 初創階段,我們使用Bigquery 作為存儲和查詢引擎。 Bigquery 是一款優秀的產品,它提供的動態算力,和靈活的UDF 語法幫助我們解決了很多問題。
不過Bigquery 也存在著一些問題:
數據沒有經過壓縮,存儲費用過高,特別是我們需要存儲將近20 條區塊鏈的原始數據;
並發能力不足:Bigquery 同時運行的Query 只有100 條,不能為Footprint Analytics 提供高並發查詢;
非開源產品,綁定Google 一家供應商。
所以我們決定探索新架構。
架構2.0 OLAP
我們對最近很火熱的OLAP 產品非常感興趣,OLAP 讓人印象深刻的地方就是其查詢反應速度,僅需亞秒級響應時間即可返回海量數據下的查詢結果,對高並發的點查詢場景也支持比較好。
我們挑選了其中一款OLAP 數據庫,Doris 進行了深入的嘗試。
但是很快,我們碰到了以下問題:
不支持Array JSON 等數據類型
在區塊鏈的數據中,數組Array 是個很常見的類型,例如evm logs 中的topic 字段,無法對Array 進行計算處理,會影響我們計算很多指標。
DBT 支持有限,不支持merge 語法來update data
DBT 是數據工程師比較典型的處理ETL/ELT 的工具,尤其是Footprint Analytics 團隊。 merge and update這也是很常見的需求,我們需要對一些新探索的數據進行更新操作。
也就是說,我們無法在Doris 上完成我們的數據生產流程,所以我們退而求其次,讓OLAP 數據庫解決我們的部分問題,作為查詢引擎,提供快速且高並發的查詢能力。
很遺憾的是,該方案無法將Bigquery 作為Data Source替換掉,我們必須把不斷地把Bigquery 上的數據進行同步,同步程序的不穩定性給我們帶來了非常多的麻煩,因為在使用存算分離的架構,當其查詢壓力過大時,也會影響寫入程序的速度,造成寫入數據堆積,同步無法繼續進行嗎,我們需要有固定的人員來處理這些同步問題。
我們意識到,OLAP 可以解決我們所面臨的幾個問題,但不能成為Footprint Analytics 的全套解決方案,特別是在數據處理以及生產方面。我們的問題更大更複雜,我們可以說,OLAP 作為一個查詢引擎對我們來說是不夠的。
架構3.0 Iceberg + Trino
在Footprint Analytics 架構3.0 的升級中,我們從頭開始重新設計了整個架構,將數據的存儲、計算和查詢分成三個不同的部分。從Footprint Analytics 早期的兩個架構中吸取教訓,並從其他成功的大數據項目中學習經驗,如Uber、Netflix 和Databricks。
4.1. 數據湖的引入
我們首先把注意力轉向了數據湖,這是一種新型的結構化和非結構化數據的存儲方式。數據湖非常適合鏈上數據的存儲,因為鏈上數據的格式範圍很廣,從非結構化的原始數據到結構化的抽像數據,都是Footprint Analytics 特色亮點。我們期望用數據湖來解決數據存儲的問題,最好還能支持主流的計算引擎,如Spark 和Flink,這樣隨著Footprint Analytics的發展,與不同類型的處理引擎整合起來能更容易,更具備拓展性。
Iceberg 可以與Spark,Flink,Trino 等計算引擎都有著非常良好的集成,我們可以為我們的每一個指標選擇最合適的計算方式。例如:
需要復雜計算邏輯的,選擇Spark;
需要實時計算的,選擇Flink;
使用SQL 就能勝任的簡單ETL 任務,選擇Trino。
4.2. 查詢引擎
有了Iceberg 解決了存儲和計算的問題,我們接下來就要思考,如何選擇查詢引擎。實際上可以選的方案不多,備選的有:
在深度使用之前,我們考慮最多的是,未來的查詢引擎必須要兼容我們當前的架構。
要支持將Bigquery 作為Data Source
要支持DBT,我們要很多指標是依賴DBT 完成生產的
要支持BI 工具metabase
基於以上個點,我們選擇了Trino,Trino 對Iceberg 的支持非常完善,而且團隊執行力非常強,我們提了一個BUG,在第二天就被修復,並且在第二週就發佈到了最新版本中。這對同樣要求高執行響應速度的Footprint Analytics 團隊,無疑是最佳選擇。
4.3 性能測試
選定了方向之後,我們對Trino+Iceberg 這個組合做了個性能測試,以確定其性能是否能滿足我們的需求,結果出乎我們依賴,查詢速度不可思議地快。
要知道,在各大OLAP 的宣傳文章中,Presto + Hive 可是常年作為最差的對比項存在的,Trino + Iceberg 的組合完全刷新了我們的認知。
下面是我們的測試結果:
case 1: join big table
一個800 GB 的table1 join 另一個50 GB 的table2 並做複雜業務計算
case2: 大單表做distinct 查詢
測試用的sql : select distinct(address) from table group by day 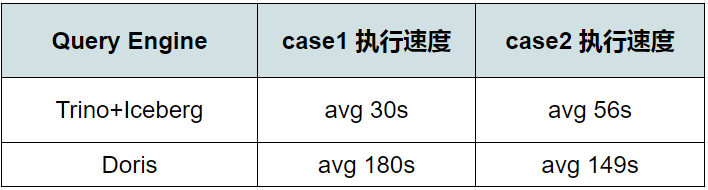
相同配置下,Trino+Iceberg 組合速度大約是Doris 的3 倍。
除此之前,還有一個驚喜,因為Iceberg 底層可以使用Parquet、ORC 等data format,會對數據進行壓縮存儲,Icberg 的table 存儲空間只需要其他數據倉庫的1/5 左右。
同樣一個table,在三個數據庫中的存儲大小分別是:
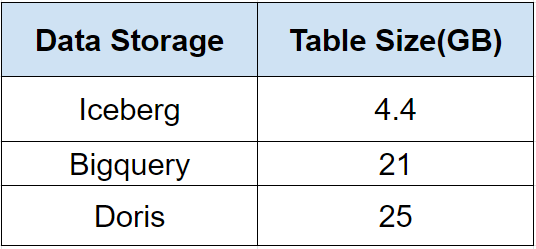
注:以上測試都是我們實際生產中碰到的個別業務例子,結論不嚴謹,僅供參考。
4.4 升級效果
性能測試報告給了我們足夠的性能,我們團隊使用了大概2 個月時間來完成遷移,這個是我們升級之後的架構圖:
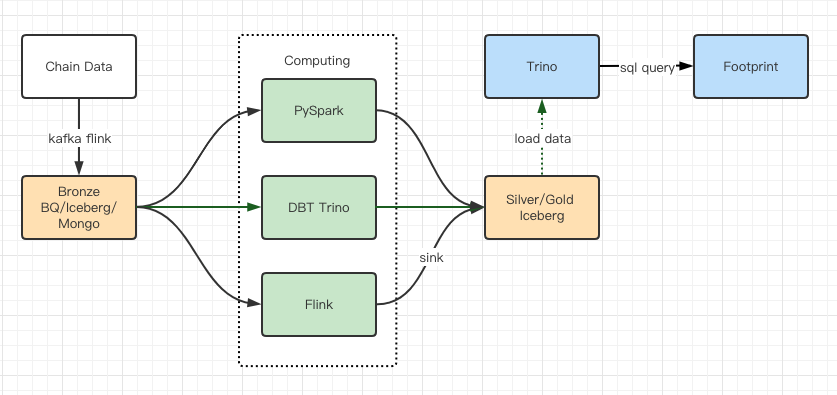
豐富的計算引擎讓我們可以應對各種計算需求;
Trino 可以直接查詢Iceberg,我們再也不用處理數據同步問題;
Trino + Iceberg 讓人驚豔的性能,讓我們可以開放所有Bronze 數據給到用戶。
總結
自2021年8月推出以來,Footprint Analytics 團隊在不到一年半的時間裡完成了三次架構升級,這得益於其為加密貨幣用戶帶來最佳數據庫技術優勢的強烈願望和決心,以及在實施和升級其底層基礎設施和架構方面的紮實執行。
Footprint Analytics 架構升級3.0為其用戶買到了全新的體驗,讓來自不同背景的用戶在更多樣化的使用和應用中獲得洞察力。
與Metabase 商業智能工具一起構建的Footprint 便於分析師獲得已解析的鏈上數據,完全自由地選擇工具(無代碼或編寫代碼)進行探索,查詢整個歷史,交叉檢查數據集,在短時間內獲得洞察力。
整合鏈上和鏈下的數據,在web2 和web3 之間進行分析。
通過在Footprint 的業務抽象之上建立/查詢指標,分析師或開發人員可以節省80% 的重複性數據處理工作的時間,並專注於有意義的指標,研究和基於其業務的產品解決方案。
從Footprint Web 到REST API 調用的無縫體驗,都是基於SQL 的。
對關鍵信號進行實時提醒和可操作的通知,以支持投資決策









