來源:OpenAI
編譯:巴比特

圖片來源:由無界AI工俱生成
OpenAI:我們已經在ChatGPT 中實現了對插件的初步支持。插件是專門為語言模型設計的工具,以安全為核心原則,並幫助ChatGPT 訪問最新的信息,運行計算,或使用第三方服務。
根據我們的迭代部署理念,我們正在逐步推出ChatGPT 中的插件,以便我們能夠研究它們在現實世界中的使用、影響以及安全和協調方面的挑戰-- 為了實現我們的使命,我們必須做好這些工作。
自從我們推出ChatGPT 以來,用戶一直在要求使用插件(許多開發者也在嘗試類似的想法),因為它們可以釋放大量可能的用例。我們正從一小部分用戶開始,併計劃在我們了解到更多信息後,逐步推出更大規模的訪問(針對插件開發者、ChatGPT 用戶,以及在alpha 期之後,希望將插件整合到他們產品中的API 用戶)。我們很高興能建立一個塑造未來人類與人工智能互動模式的社區。
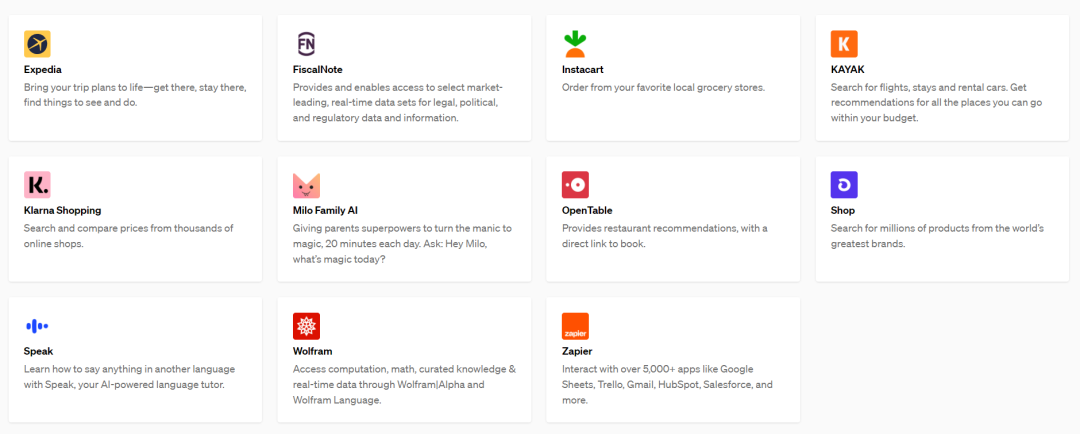
從我們的候選名單中被邀請的插件開發人員可以使用我們的文檔來構建ChatGPT 插件,然後在顯示給語言模型的提示中列出啟用的插件,以及指導模型如何使用每個插件的文檔。首批插件由Expedia、FiscalNote、Instacart、KAYAK、Klarna、Milo、OpenTable、Shopify、Slack、Speak、Wolfram 和Zapier 創建。
我們自己也有兩個插件,一個是網頁瀏覽器,一個是代碼解釋器。我們還開源了一個知識庫檢索插件的代碼,任何有信息的開發者都可以自行託管,以增強ChatGPT 的功能。
今天,我們將開始向白名單上的用戶和開發者提供該插件的alpha 權限。雖然我們最初會優先考慮少數開發者和ChatGPT Plus 用戶,但我們計劃隨著時間的推移推出更大規模的訪問。
今天的語言模型,雖然對各種任務都很有用,但仍然是有限的。它們可以學習的唯一信息是它們的訓練數據。這些信息可能是過時的,而且在各種應用中都是一刀切的。此外,語言模型唯一可以開箱即用的就是發出文本。這個文本可以包含有用的指令,但要真正遵循這些指令,你需要另一個過程。
雖然不是一個完美的比喻,但插件可以成為語言模型的“眼睛和耳朵”,讓它們獲得太新、太個人、太具體而無法包含在訓練數據中的信息。為了響應用戶的明確要求,插件也可以使語言模型代表其執行安全的、受限制的行動,從而提高系統的整體實用性。
我們期待開放標準的出現,以統一應用程序公開面向AI 界面的方式。我們正在對這樣一個標准進行早期嘗試,正在尋找有興趣與我們一起建設的開發者的反饋。
今天,我們開始逐步為ChatGPT 用戶啟用我們早期合作者的現有插件,從ChatGPT Plus 用戶開始。另外,我們也開始允許開發人員為ChatGPT 創建自己的插件。
在未來幾個月,隨著我們從部署中學習並繼續改進我們的安全系統,我們將對這個協議進行迭代,我們計劃讓使用OpenAI 模型的開發者將插件整合到他們自己的應用程序中,而不是ChatGPT。
將語言模型連接到外部工具,既帶來了新的機遇,也帶來了新的風險。
插件提供了解決與大型語言模型相關的各種挑戰的潛力,包括“幻覺”,跟上最近的事件,以及(經許可)訪問專有信息源。通過整合對外部數據的明確訪問-- 例如網上的最新信息、基於代碼的計算或自定義插件檢索的信息-- 語言模型可以通過基於證據的參考來加強其反應。
這些參考資料不僅可以提高模型的效用,而且還可以使用戶評估模型輸出的可信度,並反複檢查其準確性,從而有可能減輕與過度依賴有關的風險,正如我們最近在GPT-4 系統卡中所討論的。最後,插件的價值可能遠遠超出解決現有的限制,幫助用戶完成各種新的用例,從瀏覽產品目錄到預訂航班或訂購食物。
同時,風險是插件可能通過採取有害的或非預期的行動來增加安全挑戰,增加那些會欺詐、誤導或虐待他人的不良行為者的能力。通過增加可能的應用範圍,插件可能會提高模型在新領域採取錯誤或不一致的行動所帶來的負面影響的風險。從第一天起,這些因素就指導著我們的插件平台的發展,我們已經實施了一些保障措施。
我們已在內部並與外部合作者進行了紅隊測試練習(red-teaming exercises),發現了一些可能的相關情況。例如,我們的紅隊成員發現了插件的方法-- 如果在沒有保護措施的情況下發布,可以執行複雜的提示注入,發送欺詐性和垃圾郵件,繞過安全限制,或濫用發送到插件的信息。我們正在使用這些發現來告知設計安全緩解措施,以限制有風險的插件行為,並提高作為用戶體驗一部分的插件如何以及何時運作的透明度。我們還利用這些發現來決定逐步部署對插件的訪問。
如果你對該領域的安全風險或緩解措施感興趣,我們鼓勵你參與我們的研究人員訪問計劃。我們還將邀請開發者和研究人員提交與插件相關的安全和能力評估,作為我們最近開源的 Evals 框架的一部分。
插件將可能產生廣泛的社會影響。例如,我們最近發布了一份工作文件,發現可以使用工具的語言模型可能會比沒有使用工具的語言模型產生更大的經濟影響。更普遍的是,與其他研究人員的發現一致,我們預計當前的人工智能技術浪潮將對就業轉型、轉移和創造的速度產生很大影響。我們渴望與外部研究人員和我們的客戶合作,研究這些影響。
一個知道何時及如何瀏覽互聯網的實驗性模型。
受過去工作(我們自己的WebGPT,以及GopherCite、BlenderBot2、LaMDA2 等)的激勵,允許語言模型從互聯網上讀取信息,嚴格擴展了它們可以討論的內容的數量,超越了訓練語料庫,擴展到了當前的新鮮信息。
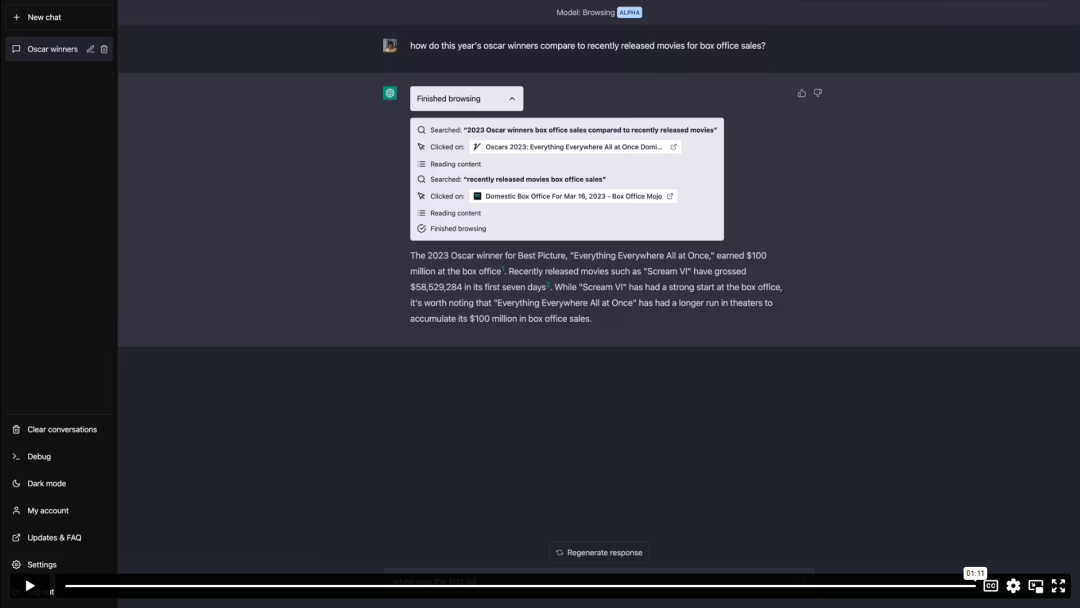
下面是ChatGPT 用戶的Browsing 體驗的一個例子。在此之前,若提出這些問題,模型會禮貌地指出它的訓練數據沒有包含足夠的信息來讓它回答。在這個例子中,ChatGPT 檢索關於最新奧斯卡獎的最新信息,然後執行我們現在熟悉的ChatGPT 詩歌表演,這是Browsing 可以成為附加體驗的一種方式。
除了為終端用戶提供明顯的效用外,我們認為使語言和聊天模型能夠進行徹底和可解釋的研究,在可擴展對齊方面有著令人興奮的前景。
安全考慮
我們已經創建了一個網絡Browsing 插件,允許語言模型訪問網絡瀏覽器,其設計優先考慮安全和作為網絡良好公民來運作。該插件的基於文本的網絡瀏覽器被限制在發出GET 請求,這減少了(但沒有消除)某些類別的安全風險。這使得Browing 插件在檢索信息方面很有用,但不包括”事務性“操作,如表單提交,因為這些操作涉及更多的安全和保障問題。
Browsing 使用Bing 搜索API 從網上檢索內容。因此,我們繼承了微軟在以下方面的大量工作:(1)信息來源的可靠性和真實性;(2)防止檢索有問題內容的”安全模式“。該插件在一個獨立的服務中運行,因此ChatGPT 的browsing 活動與我們基礎設施的其他部分分開。
為了尊重內容創作者並遵守網絡規範,我們的瀏覽器插件的用戶代理標記是 ChatGPT-User,並被配置為尊重網站的robot.txt 文件。這可能偶爾會導致”click failed“的消息,這表明該插件正在尊重網站的指示,以避免抓取它。該用戶代理僅用於代表ChatGPT 用戶採取直接行動,不用於以任何自動方式抓取網絡。我們也已經公佈了我們的 IP 出口範圍。此外,我們還採取了限制速率的措施,以避免向網站發送過多的流量。
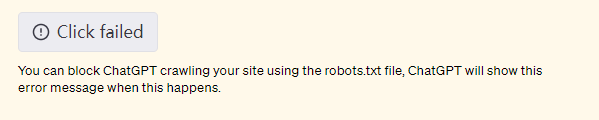
你可以使用robots.txt 文件阻止ChatGPT 爬取你的網站,這時ChatGPT 會顯示這個錯誤消息。
我們的Browsing 插件會顯示訪問過的網站,並在ChatGPT 的回復中引用其來源。這種增加的透明度有助於用戶驗證模型反應的準確性,同時也將功勞歸於內容創造者。我們認為這是一種與網絡交互的新方法,並歡迎對其他方法的反饋,以推動流量回到源頭,並增加生態系統的整體健康。
一個實驗性的ChatGPT 模型,可以使用Python,處理上傳和下載。
我們為我們的模型提供了一個在沙箱、防火牆執行環境中運作的Python 解釋器,以及一些臨時的磁盤空間。由我們的解釋器插件運行的代碼在一個持久的會話中被評估,該會話在聊天對話期間是有效的(設有上限時間),隨後的調用可以建立在彼此之上。我們支持將文件上傳到當前的對話工作區並下載你的工作結果。
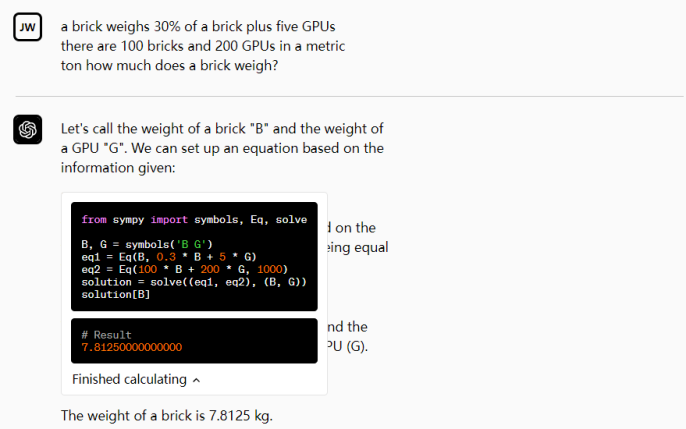
我們希望我們的模型能夠使用它們的編程技能,為我們的計算機的最基本功能提供一個更自然的接口。讓一個非常熱心的初級程序員以指尖的速度工作,可以使全新的工作流程變得輕鬆和高效,並向新受眾開放編程的好處。
從我們最初的用戶研究中,我們已經確定了使用代碼解釋器特別有用的用例:
解決數學問題,包括定量和定性的數學問題
進行數據分析和可視化
在不同格式之間轉換文件
我們邀請用戶嘗試代碼解釋器集成並發現了其他有用的任務。
安全考慮
將我們的模型連接到編程語言解釋器的主要考慮因素是適當的沙盒執行,以便人工智能生成的代碼不會在現實世界中產生意想不到的副作用。我們在一個安全的環境中執行代碼,並使用嚴格的網絡控制來防止外部互聯網對已執行代碼的訪問。此外,我們還對每個會話設置了資源限制。禁用互聯網訪問限制了我們的代碼沙盒的功能,但我們相信這是正確的初始權衡。第三方插件被設計為一種安全第一的方法,將我們的模型與外部世界連接起來。
開源的檢索插件使ChatGPT 能夠訪問個人或組織的信息源(經許可)。它允許用戶通過提問或用自然語言表達需求,從他們的數據源中獲得最相關的文件片段,如文件、筆記、電子郵件或公共文檔。
作為一個開源和自我託管的解決方案,開發者可以部署自己的插件版本,並在ChatGPT 註冊。該插件利用 OpenAI 嵌入,並允許開發者選擇一個矢量數據庫(Milvus、Pinecone、Qdrant、Redis、Weaviate 或Zilliz)來索引和搜索文檔。信息源可以使用webhooks 與數據庫同步。
開始著手可先訪問檢索插件庫。
安全考慮
檢索插件允許ChatGPT 搜索一個矢量數據庫的內容,並將最佳結果添加到ChatGPT 會話中。這意味著它沒有任何外部影響,主要風險是數據授權和隱私。開發者應該只在他們的檢索插件中添加被授權使用並可以在用戶的ChatGPT 會話中分享的內容。
一個實驗性的模型,知道何時以及如何使用插件。
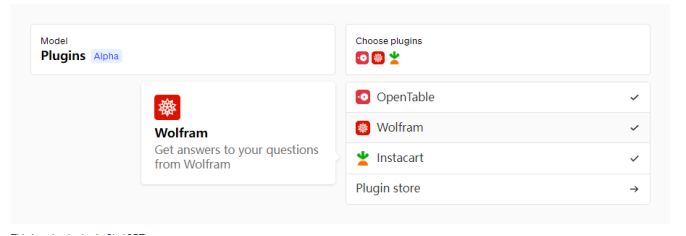
ChatGPT 中的第三方插件
第三方插件由一個清單文件描述,其中包括機器可讀的插件功能和如何調用它們的描述,以及面向用戶的文檔。
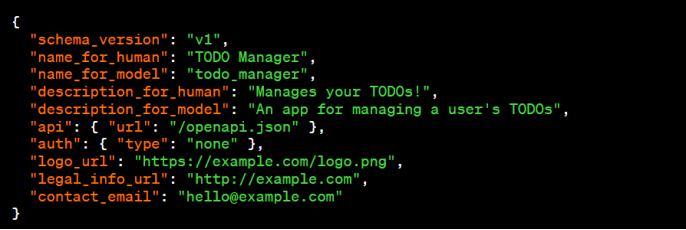
一個用於管理待辦事項的插件的清單文件示例
創建插件的步驟是:
1、 建立一個帶有你希望語言模型調用的端點的API(這可以是一個新的API,一個現有的API,或者一個專門為LLM 設計的現有API 包)。
2、創建一個記錄你的API 的OpenAPI 規範,以及一個鏈接到OpenAPI 規範並包括一些插件特定元數據的清單文件。
在 chat.openai.com 上開始對話時,用戶可以選擇他們希望啟用的第三方插件。關於啟用的插件的文檔會作為對話上下文的一部分顯示給語言模型,使模型能夠根據需要調用適當的插件API 來實現用戶的意圖。目前,插件是為調用後端API 而設計的,但我們也在探索可以調用客戶端API 的插件。
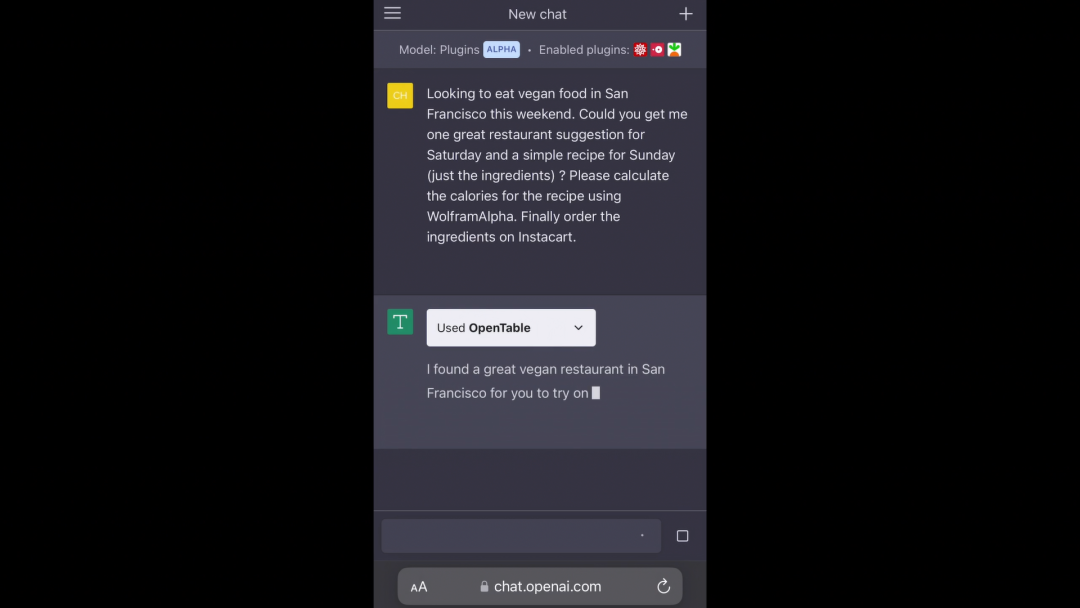
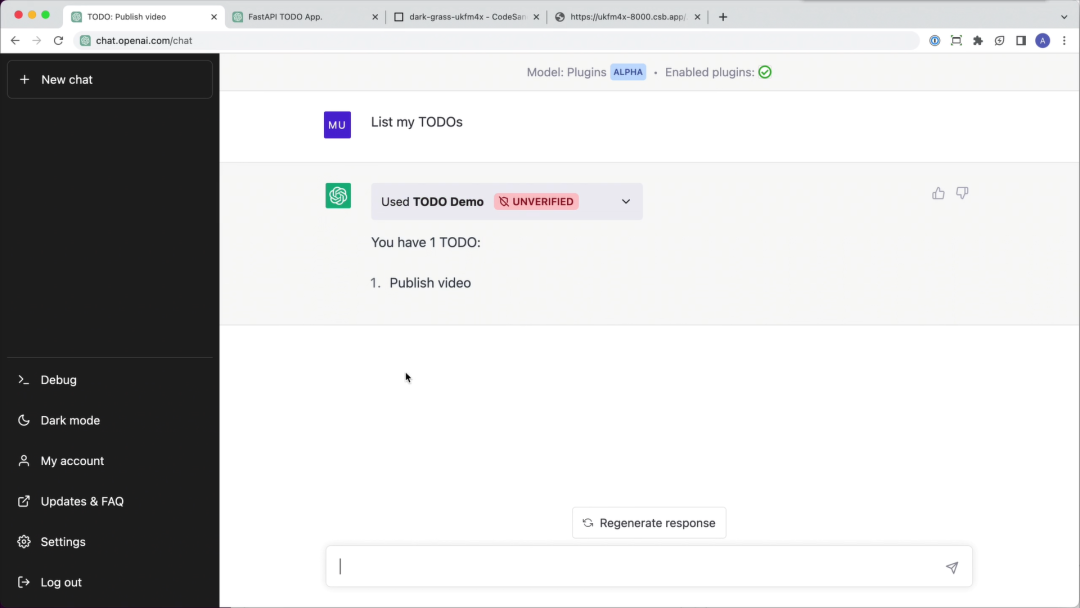
我們正在努力開發插件,並把它們帶給更多的受眾。我們有很多東西需要學習,在大家的幫助下,我們希望建立一個既有用又安全的東西。
注:文中涉及多處視頻演示,可參看原文。
巴比特園區開放合作啦!



中文推特: https://twitter.com/8BTC_OFFICIAL