Web3 Explorer
Web3 Explorer
|2021-11-16 5:58
使用Substrate实现基于存储共识的链下计算范式
前言
一款大众意义上成功的 Web2.0 To C 应用,至少应该在百万月活量级。我们熟知的顶级的 Web2.0 应用 Twitter, Google, Facebook, WeChat, Tiktok 等,月活都在 10 亿量级以上。也就是说,面向 C 端的应用,必需搞定高并发及大数据量存储和检索,以及其它一些东西。而我们来看看目前基于区块链的明星应用,截止目前(成文时:2021.10.15):● Audius,目前月活 400 万用户,号称建立在以太坊和 Solana 之上,具体其使用链的方式,对区块链的依赖有多大,信息并不透明● Axie Infinity,有 170 万游戏用户,运行在其以太坊独立链 Ronin 上,不过这个 Ronin 的信息同样公开得较少● 以太坊上的头部 24 个DeFi 应用,用户地址数加起来有 300 万[1]造成这种现状,除了用户本身关注度较少之外,还有两个重要的基础层面的原因:1.现有的大部分 Dapp 的 UX 体验,普通互联网用户难以理解和操作2.现有区块链的计算性能太低、数据存储成本太高,使得使用成本太高也就是说,现在这些区块链(公链)的基础设计,其实承载不了互联网级别的用户量,这里面有结构性机制性的问题。我们本篇尝试讨论如何才能让区块链适用于大规模应用场景。月活百万用户应用的基本要求
我们这里仅对 Web2.0 月活百万用户入门级应用稍作分析。Web App 和手机 App 的 UX 体验要平滑,流程要顺畅,前置要求不能过多(比如需要某个钱包账号,安装某个浏览器插件),用户上来就能用。并且账号不一定需要自己的重新注册,能方便地使用现有的第三方登录是最好的。能支撑大量用户的同时访问,不能出现卡壳的情况,延迟也不能过高(超过数秒)。这些都会体现在产品的 UX 用户体验上面。面对大量的请求,不能出现服务崩溃,中断的情况。计算成本与计算性能这个指标是相关的,服务端系统的计算性能不能太低,不然无法承载高并发的请求。计算成本不能太高,不然云服务器的成本会急剧攀升。用户在使用 App 的过程中会产生大量的数据。这些数据不仅包含用户直接创造的 UGC 数据,还有很多服务中间状态数据,各个层级的日志数据。这些数据最后都会存储下来,存放在 SQL 数据库或、NoSQL 数据库、对象存储服务、或者文件存储服务等等。一些索引服务如 ElasticSearch 也需要单独存储被索引的数据。这些存储要占用大量的存储空间。考虑到数据的可靠性,还需要做冗余处理。做冗余处理,相当于数据占用的空间要大几倍。这些都要求存储成本要保持比较低的水平,不然会导致服务整体的成本过高,App 难以运维下去。Web3.0的要求
其实,Web3.0 的目标只有一个:开放性(Openness)。开放性是 Web3.0 的唯一核心目标。那么,开放性这个词有哪些内涵呢?本文在这里不打算展开论述,详细讨论可参见拙作:《对Web3.0概念的梳理》[2]和《为什么Web3.0需要区块链》[3]。目前区块链计算方式的瓶颈
我们这里讨论一下主流区块链以太坊 Ethereum 的技术方案存在主要问题。全世界所有以太坊的节点都在 evm 中以单线程的形式运行一个合约序列。从合约程序的角度来看,每个对合约函数的调用按排队执行,一个执行完再执行另一个,相当于分时复用同一个 CPU。这种计算模型,决定了节点的计算能力受限于节点单个 CPU 的计算能力,其性能限制非常大。目前以太坊的处理能力 TPS 为 13 左右。据计算,目前(发文时)在以太坊上每存储 1k 字节数据的费用超过:$100(一次性付费)。而传统云存储服务存储 1 G 数据的成本大概是:$0.02 每月。如果按10年来算,以太坊上的存储费用比云存储高 41,666,666 倍。为了防止过度占用计算资源和存储资源,以太坊设计了 Gas 费机制。由于以太坊的计算能力和存储能力都非常有限,其它的公链项目便有了出头的机会。不同的公链在不同的方向上做出了一定程度的创新。Solana 思路是把 Layer1 性能做到最好,号称目前 TPS 最高的公链。其 PoH 共识辅助机制,使得一些共识子流程可以使用 GPU 来做并行验证。目前 Solana 的 TPS 大概在 2000 左右。Solana 一定程度上放弃了部分去中心化特性,并且其节点配置要求特别高。这些都是追求高 TPS 的代价。●Ethereum 2.0,NEAR, Polkadot这仨都是走的分片(Sharding)之路。分片非常难,可能是最难的扩容方案了。以太坊 2.0 节奏缓慢,遥遥无期。NEAR 据说 2021 年底发布 6 个分片的网络,目前还不清楚分片后的网络实际效果如何,带来多大优势,交易成本会不会增加。Polkadot 的平行链现在在稳步推进,其先行网已经上了几个平行链了,但还没经过真正应用的验证。分片的难,难在原理上,详见 NEAR 的《夜影协议白皮书》[4]。现在尚无一个真正的稳定运行的分片网络,分片网络后面会不会遇到什么新的问题,是否具有实用性,这些都需要时间来验证。●L2 群雄:Polygon, Arbitrum, Optimistic Rollup, ZK RollupL2 对以太坊的扩容是目前的主流扩容方向。详见:《以太坊的Layer2扩容之路》[5]。这俩兄弟项目走的是多链跨链之路。基本出发点是认为支撑应用的最小单位是应用链(Appchain),而不是合约。每个应用一条链,然后所有应用链都可以通过 IBC 协议直接互联互通。上述提到的这些项目,到目前为止,都已产生可观的影响。扩容之路不是那么容易,最后只能靠时间来检验,谁才能够走到最后。面向 Web3.0 应用的计算范式
前面提到,Web3.0 的核心在于开放性,而不是以下名词中的任何一个(虽然每个都很重要):安全性是延伸属性,密码学和区块链是工具,去中心化是手段,开放性才是目的(目标)。而对区块链来讲,我们前面提到的所有主流的区块链,其实都是面向资产而设计,而非应用。回顾历史,如果从2008年比特币诞生开始算起,这十多年,所有主流区块链项目其实只做了一件事情:处理资产。12年的一个成果,刚刚好就是 2020 年之夏的 DeFi 热潮。即便只是资产这么一个东西,要处理好也是一件了不起的事情(试想想,全球的金融业本身就是一个特别大的产业)。也就是说,即使只处理资产、金融相关的业务,以太坊已经不够用了,还要出现那么多的L2、侧链、新型公链等项目来分担处理。这么多选手一起上也还差得远,离解决好金融业务这个目标还有太远的距离。也就是说,到目前为止,在区块链上做的那些努力,连基本盘金融领域都尚未处理得过来,更遑论面向 Web3.0 进行应用这一层次的创新了。链上逻辑只适合处理资产业务
在拙作《为什么区块链需要 Web3.0》[6] 中提出:合约型公链仅适合于处理 DeFi(资产、金融)相关业务。而在本篇中,我们将进一步提出:所有链上逻辑都只适合处理 DeFi(资产、金融)相关业务。既然本篇我们讨论的是大规模的应用,那出发点就是大规模应用的标准,而不是做 Demo,演示其可能性。对于合约型公链来说,可以把所有合约应用,组合起来看作一个大的应用,皆为链上逻辑。这是由基础的账户模型决定的。而对于由 Substrate 这种框架开发的应用链 Appchain 来说,其链上逻辑仍然只适合处理资产相关业务。区块链的链上逻辑,无法用于处理通用型大规模的应用。理由如下:1.链上逻辑的计算量受限于节点性能和出块间隔的限制2.链上逻辑必须在虚拟机体系内完成,不能有任何副作用3.链上状态的存储使用 MPT 实现,具有一系列优异的特性(比如方便校对内容,方便做增量hash,方便访问历史版本),但是也增大了中间存储量和计算量4.链上数据结构受限于存储特性和Gas费等,种类比较少,形式比较初级,要注意的细节点很多,在处理业务时很受限5.由于区块链的安全性要求(加密,编码解码),链上无法内置一个 SQL 这种 Web2.0 中最基础而又强大的检索引擎,这让写业务代码的时候,需要人为手动在数据插入的时候建立更新索引对象,非常别扭由于以上的这些问题,我们认为传统的区块链链上计算范式无法承载 Web3.0 应用的大规模实践。面向 Web3.0 应用,我们需要寻找另外的计算和存储范式。基于 Arweave 的存储共识范式
存储共识范式(原名存储计算范式):通过 Arweave 永久存储和链下计算达到共识。存储共识范式是 everFinance 提出的下一代区块链应用开发范式。在 Ethereum 模型中,计算会被区块链网络中的所有节点执行,所有节点都会生成和存储全局状态以供查询。不同于 Ethereum 模型,存储共识范式分离了计算和存储,区块链仅进行数据存储不进行任何计算,所有计算由链下的客户端/服务器执行,生成的状态也由链下客户端/服务器进行保存。存储共识范式使用了链下智能合约,智能合约可以是任何语言编写的程序,这些程序的所有输入参数都来自存储型区块链。在范式中,区块链更像是计算机的硬盘,链下智能合约可以在任何具备计算能力的机器上进行。使用区块链作为硬盘,所存储的数据具备了不可篡改和可追溯的特性,区块链为数据赋予了可信的特性。链下智能合约对可信数据进行计算,能保证状态的最终一致性。存储共识范式开发的应用程序,具备区块链的透明和可信特性,同时又具备传统互联网应用的高性能和可用性。存储共识范式具备以下优势:1.可组合性:传统金融服务间进行业务对接,需要会计对账,对账过程繁复且容易出错。采用存储共识范式,将金融交易记录完全上链,把传统金融服务转化成区块链应用,实现自动化对账,达到应用间的快速协同,高效组合。2.开发门槛低:使用 Ethereum 虚拟机编写智能合约需要使用 Solidity 语言,链下计算则可以用任何的语言进行开发,开发者可以将传统的应用转化成区块链应用。3.无性能限制:链下计算,其性能跟传统应用一样,链下服务器可以承载大量的交易。TPS 取决于提供服务的机器性能和构建应用的技术架构。4.共识成本极低:100 万笔交易仅需要 1 美金。参考资料:Storage-based Consensus Paradigm[7]。Substrate 框架的 OffChain 特性
OffChain 特性是 Substrate 中提供的一套相当强大的基础设施。毕竟对区块链来说,链上的逻辑操作空间非常有限,有些事情必须通过链下来完成。在没有 OffChain Worker (OCW) 之前,这一类事情,通常是由预言机 Oracle 来完成。预言机是外部服务,通过区块链节点 RPC 接口向区块链提交交易从而把外界的信息传到链上去。这种方式虽然是可行的,但它在安全性、集成性、可扩展性和基础设施效率问题上面,仍然不够好。为了让链下数据的集成更安全和有效,Substrate 提供了 offchain 相关的特性。其架构图如下: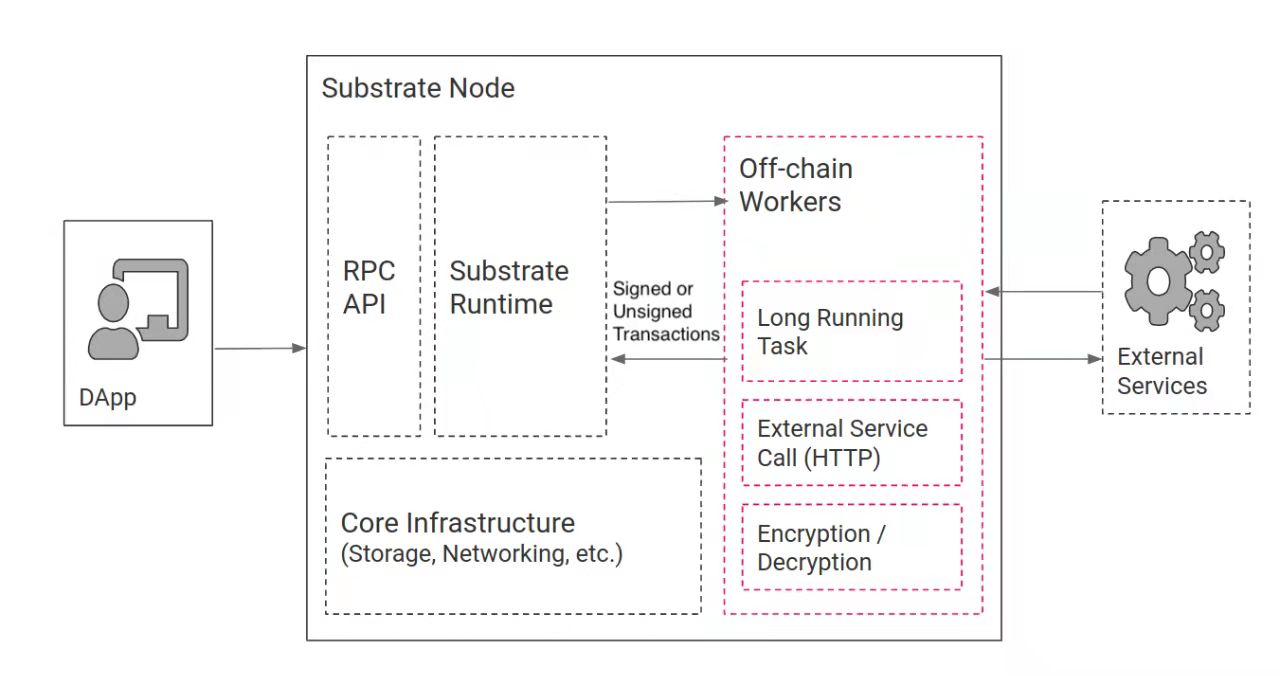
OffChain Worker 用于实现链下逻辑。其代码与 Runtime 代码写在一起,并被编译到同一个 wasm 字节码字符串中,在同一个交易中被传播到全网络。但是在执行的时候,OffChain Worker 的代码是在独立的 VM 中执行的,即与 Runtime 逻辑的执行完全隔离开。具体来说,OffChain Worker 能够实现如下功能:●包含一个全功能的 HTTP 客户端,能够访问外部服务的数据●可以访问本地 node 的 keystore,这样便可以验证和签名交易●可以访问本地的 KV 数据库,且在所有 offchain worker 中共享这个数据库OffChain Storage 是链下逻辑独立的存储空间,与链上的 Storage 是完全隔离开的。它具有如下特性:●能被 OffChain Worker 读取和写入●存储在 node 本地,不会传递到网络中其它节点去,不会参与网络共识●被所有同时运行的 OffChain Workers 共享访问(因此需要锁操作)。因此,可以利用其在不同的 Workers 之间通信●能被 Runtime 代码写入,但是不能读。因此,可基于其实现一定的链上链下交互功能●可被 wasm 环境外的 node 中的代码读取,因此能被 RPC 读取OffChain Indexing 提供了在 Runtime 环境中,向 OffChain Storage 写入数据的能力。但是不能读取 OffChain Storage 中的数据。这为一些新的编程范式提供了可能性。其它还有一些,比如,完善的OCW集成测试框架等等。Substrate 的 OffChain 特性非常强大,令人印象深刻。基于 Substrate 实现链基于存储共识的链下计算范式
从 Arweave 存储共识范式获得灵感,我们来看看在 Substrate 中如何实现类似基于存储共识的链下计算范式。整个 Substrate 框架其实分成三大块可编程逻辑: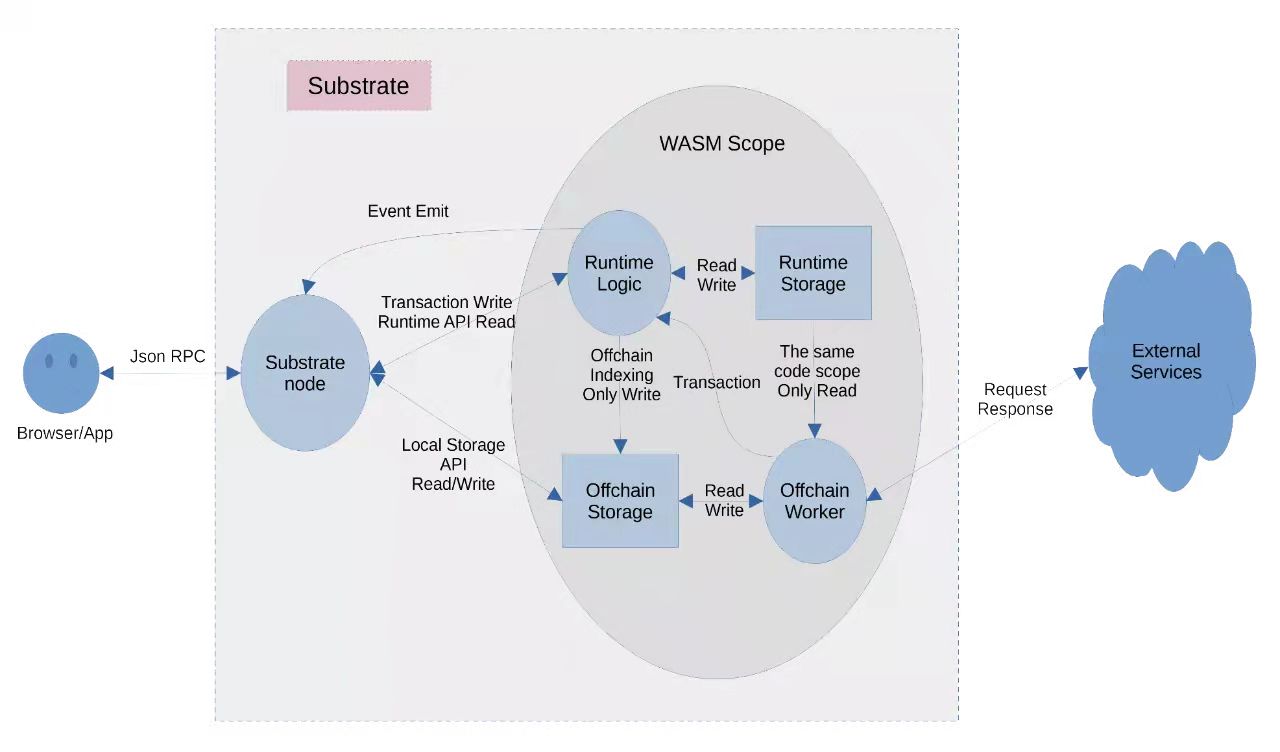
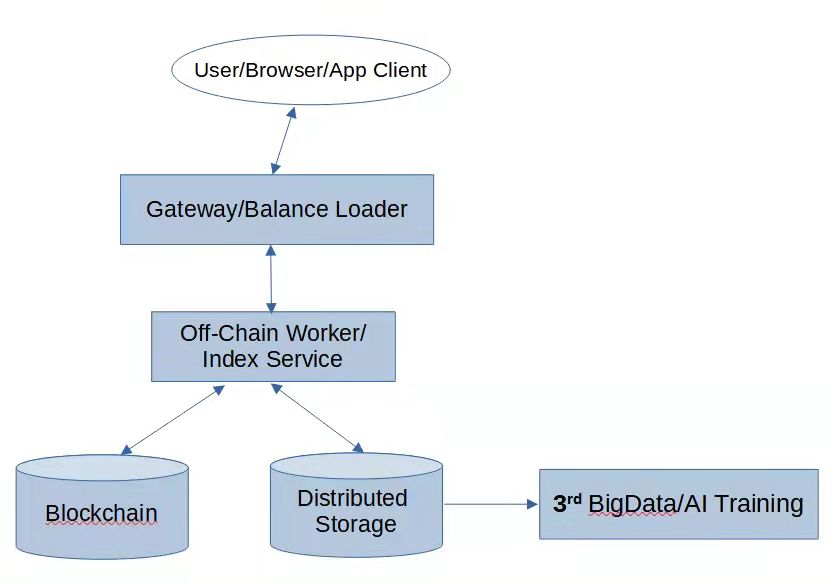
前面我们说过,Substrate 中的 Runtime 只适合处理资产类逻辑,Runtime Storage 只适合存储资产类数据,它们不适合处理和存储其它大规模应用的逻辑和数据。在《为什么Web3.0需要区块链》中,有一幅 Web3.0 应用的通用架构图:可以看到,在 Web3.0 应用中,链下计算和链下存储占据非常重要的位置。在本节,可以将这幅图针对 Substrate 做一细化,设计一套崭新的计算模式。我们理解:区块(Block)是应用的操作和输入数据的历史分段打包(注意,不是历史状态的打包)。其与数据库的SQL日志是类似的,区别在于:2.每一个分段都由多个节点参与共识确认,形成一个全网的共识,并在各自节点中敲定(finalized)。敲定的过程,也是对每个节点中的交易池中的交易定序的过程1.前面一个块的 Hash,以明确当前块是链到哪个块上的(每个块都有一个父块,因此形成链状,所以叫区块链)2.当前块中包含的交易序列的总Hash, merkle_root。用于验证,防止在网络传输途中被篡改交易3.当前节点中,全局链上状态空间的 state_root。用于不同节点间全局状态空间的同步,每一个块都校验 state_root,能让所有参与节点内部保持一个严格的同步的一致的链上全局状态。基于这些认识,我们可以基于前面的 Substrate 应用架构图,做出如下设计:将逻辑从 Runtime 中剥离。Runtime 逻辑的作用仅在于:1.作为代理函数,将外部交易的调用的方法的名称和输入数据按一定规范写入 Offchain Storage (使用前面提到的 offchain indexing 特性)3.用于升级整个 wasm 代码(其中包含应用的主要逻辑所在的 offchain worker 代码)。这个机制内建在 substrate runtime 中,不需要单独开发而链上存储不再需要了(但不是 0,Substrate默认有一些,这个我们不需要关心)。真正的逻辑在 Offchain Worker 中执行。这部分代码是 wasm 字节码,由链上发交易统一管理升级,保证所有节点的一致性。Offchain Worker 代码在块导入时执行。执行逻辑如下:2.检查 offchain storage 中是否有符合某些键值对规范的存储内容,这个内容应该包括:方法名称,参数表(入参数据)。如果有,取出方法名称和参数表(可能是序列化后的)3.在 Offchain worker 中,按方法名称进行路由,并把反序列化后的参数表传到对应的路由 handler 中去。这些路由 handler 代码可以写在不同的文件中,在 runtime 主文件中引进来(同样会被编译到 wasm 中)4.Handler 可以使用 offchain storage 中的数据,充分完成计算、聚合、重整化等工作5.Handler 执行完成后,可以通过以下方式通知网关要返回的结果:a.通过 offchain worker 中的 http 请求能力,主动将结果发送给 gateway,gateway 监听到结果后,根据结果中的 uri 对应地将数据返回给前端b.将结果缓存在 offchain storage 中。gateway 定时轮询或监听 substrate node 的 rpc 接口,通过 rpc 接口从 offchain storage 中取得相应结果,并返回给前端以上就是使用 Substrate 实现基于存储共识的链下计算范式的主要流程。这里需要解释一下为什么这种方式就是基于存储共识的链下计算:1.执行逻辑 offchain worker 中的代码,是通过 substrate 交易提交到链上,通过 p2p 网络,在各个节点通过验证后,更新到各个节点上的。这保证了执行代码的一致性(起到了 Arweave 对应的作用)2.Substrate offchain indexing 的一大特性就是:一致性。Substrate.dev[8] 中有一段话:”Unlike OCWs, which are not executed during initial blockchain synchronization, off-chain indexing is populating the storage every time a block is processed, so the data is always consistent and will be exactly the same for every node with indexing enabled.”。有这个特性保证,就可以保证存储在 offchain storage 中的对方法的调用和传入的参数在所有节点上是一致的。也即是保证了输入数据的一致性(起到了 Arweave 对应的作用)3.一旦 Offchain worker 开始执行,其是在链下执行的,与链上逻辑和存储完全分开。这也就对应了 Arweave 存储共识范式中的链下执行部分4.计算后的结果,并不会重新上链(因为并不需要链上存储),这是非常重要的一点。在这方面,与 Arweave 存储共识范式也是相同的。好了,我们说了这么多,到底 使用 Substrate 实现基于存储共识的链下计算范式有什么优势值得我们关注呢?下面一节,我们重点与目前已有的典型计算方案做一下对比。与目前典型计算方案的对比
这里,我们说传统区块链计算范式,指的就是链上计算范式。Substrate 基于存储共识的链下计算范式的优势:1.Offchain worker 计算不再受限于出块间隔的要求,可以实现长时间的计算或等待2.Offchain worker 是独立的轻量级线程,同时可并发执行多个轻量级线程,以充分利用节点的计算能力3.Offchain worker 具有访问外部服务的能力,也具有对外部产生副作用的能力,这点在实际的业务中,非常重要4.Offchain Storage,不再受链上设计制约,可以充分利用已有的数据库领域的历史积累和前沿创新,为大规模数据存储铺平道路5.Offchain Storage 中的存储内容,可以分为三个部分。只有方法名调用和输入数据这块需要保持强一致性。逻辑运算结果需要访问(界面)一致性。在第三部分可以灵活地存取/缓存本地节点数据,以实现更灵活地编程6.用于 Substrate 链下计算的节点可以是整个区块链大网络节点中的一部分,这样可有效控制计算成本和存储成本,使得内容的处理和存储量级可以大规模的扩张Substrate 基于存储共识的链下计算范式的劣势:1.Substrate Storage 目前是简单的 kv 数据库,失去了 MPT 结构天生的一些特性(如:方便的历史版本访问,快速的增量hash,快速比对等)2.链上存储状态在每一个区块中都有 state_root 做同步,而 Substrate 链下计算范式则失去了这个特性。这样对存储状态的同步缺少强制性3.Substrate 链下计算范式对计算结果的存储和中间状态的存储需要有一套自定义的规范,这些规范只是定义在 offchain worker 代码中,而没有其它节点强制验证的过程4.在 Substrate worker 中仍然要注意,诸如随机数和外部请求这些副作用,不能对需要一致性的存储区造成影响。因此在编写代码的时候,需要人为注意,需要有约定或者最佳实践1.链的集成度更高。Substrate节点本身组成一条区块链,不再单独需要一条链作为服务2.Substrate 链的交易的验证过程比 Arweave 数据上传请求验证过程更细致。Substrate Runtime 中可以写交易的自定义验证代码,这是在链上执行的,而 Arweave 只是链上存储服务,做不到这一点3.Substrate offchain indexing 是从链上主动往链下写内容,而 Arweave 需要链下的计算客户端主动从 Arweave 网络上去拉对应的数据。这个过程显得不那么自动化,至少轮询的次数会多。另外,从 Arweave 上拉数据存在网络访问,可能存在网络访问失败的问题,如果数据量较大,那么下载完成也需要可观的时间。而 Substrate offchain indexing 完全运行在一个节点内部,性能更好,集成度也更高,对开发者来说,掌控力更好4.基于 Substrate 节点,链上逻辑和链下逻辑是统一运维的,集成度更好,运维的可靠性更好(去信任,减少扯皮可能性)5.Substrate 链下逻辑强制使用 wasm 字节码来运行。在这点上,Arweave 并没有要求。Webassembly 是一套得到国际广泛支持的字节码标准,在其上有非常多的创新,生态在快速发展。从运行效率和未来生态来说,采用 wasm 来部署应用是一个优势简单来说,Substrate 基于存储共识的链下计算范式,相当于实现了 Arweave 的一部分功能,但是没有提供 Arweave 永存的特性。这点上,如果将 Substrate 链的块历史上传到 Arweave 上存储,那么就充分地利用了 Arweave 的永存优势。1.语言中不立。Substrate 目前只能使用 Rust 语言进行开发,这意味着要使用 Substrate 实现 Web3.0 应用开发,必须学习使用 Rust语言。而 Arweave 存储共识范式是语言中立的,可以用任何语言开发2.Substrate 链下计算范式对编程方式有新要求,而基于 Arweave 存储共识范式的编程开发就与 Web2.0 开发类似,只需要调用 Arweave 相关的第三方服务即可3.Arweave 实现的永存,对需要一致性共识的内容(代码和输入)具有历史可靠性更好的优势。即使区块链项目倒闭了,它的那些内容还可以从 Arweave 上查到(意义大家可以讨论)4.Arweave作为一个存储计算服务,类似于 XaaS(X as a Service),在某些场景下会很方便我们前面描述过,Substrate 链下计算范式需要人为做一些约定,在这点上,Arweave 存储共识范式一样会遇到。这点上两者一致。与 The Graph/SubQuery 的对比
Substrate 是工具套件(像当年的 LAMP 一样),The Graph/SubQuery 是服务。The Graph/SubQuery 是外部索引服务,主要用于对链上抛出的事件进行索引,并通过写 Mapping 方法实现事件信息提取,生成 schema 结构化数据存入数据库中。它们提供 GraphQL接口,其内部本身也还是传统的 SQL 或 NoSQL 数据库。Substrate 基于存储共识的链下计算范式的优势:1.集成度更高,The Graph/SubQuery 需要一个第三方外部服务才能获取数据2.Substrate 的模式能提供的接口形式更灵活。在网关上配置 RPC,Restful, GraphQL 都可以3.Substrate 更可控,更去中心化。The Graph/SubQuery 是一个服务,大家都用这个服务,对这个服务的依赖性也就更强,对其运行的稳定性也就有担忧。而 Substrate 这套工具,只需要对自己的链负责,别人出的问题不会影响到自己,自己出的问题不会影响别人。大家部署自己独立的服务,其实是更好的执行去中心化的过程(前提是尽量用同一套工具,或至少用遵循同一套协议的工具)Substrate 基于存储共识的链下计算范式的劣势:1.目前将 Offchain Storage 替换/升级 成支持 SQL 引擎的存储还没实现,索引还得自己来维护2.The Graph 能够对合约公链进行索引(用于开发 Dapp),而 Substrate 链下计算范式只适用于 Substrate 框架实现的 Appchain3.The Graph/SubQuery 是对链上抛出的信息进行索引,链上写代码的方式该怎样就怎样,不受影响,也即没有侵入式。而 Substrate 链下计算范式对使用 Substrate 框架开发代码的方式有要求,要按照新的范式来写代码,所以是侵入式的(虽然本文认为新的计算范式更适用于 Web3.0 应用)对比可见,两者各有其适用的场景。The Graph/SubQuery 更适用于传统的基于合约的 Dapp 开发,Substrate 基于存储共识的链下计算范式更适用于面向具体场景的 Web3.0 App 的开发。与传统中心化应用的对比
由于链下计算的特性,传统中心化应用的那些成熟的基础设施(比如分布式数据库),理论上来说都能被 Substrate 基于存储共识的链下计算范式应用所利用。Substrate 基于存储共识的链下计算范式的优势:1.相对于传统中心化应用来说,Substrate 的链下计算范式应用是去中心化应用,业务逻辑在各个节点上运行,并且通过区块链的强制特性保持了业务和运行结果的一致性。去中心化应用的一切优势,Substrate 链下计算范式的应用都自动具有2.保障了开放性。前文提到的三个层次(数据,数据的操作,组织的形式)的开放性,在这个计算范式下,都能得到有效保证,这正是我们 Web3.0 追求的目标。任何一个感兴趣的人都可以运行 Substrate 节点,同步所有历史区块,跑出所有数据来。获取数据的人不一定要参与链的共识。而传统的中心化应用,在这三个层次上,都是封闭的Substrate 基于存储共识的链下计算范式的劣势:1.同样的逻辑,需要在各个链下计算节点重复计算,并在每个节点都做存储。这在计算成本和能耗上,确实不是优势。但是由于参与链下计算的节点数量可以控制,这块的冗余性与传统中心化应用需要做的数据冗余和逻辑冗余(以防止一个节点的服务导致的服务中断),其实是类似的2.在基础设施层面,中心化应用能用到充分成熟的支撑大规模应用的基础设施,而 Substrate 链下计算范式的基础设施还不成熟。目前 Substrate Offchain 基础设施的不足
Offchain Storage 目前只是最基础的 kv 数据库实现(rocksdb)。要支撑真正面向实际的应用,基础设施还需要完善,有几个方向可以参考:1.Redis:Redis作为内存KV数据库,其内建丰富的数据结构的支持,使得其得到了各种领域大规模的应用2.Mongodb:Mongodb作为对象型数据库,特别适合某些领域3.Tikv + Tidb:作为新一代分布式数据库的代表,tikv 在 rocksdb 之上做了分布式协议层,而 tidb 进一步在 tikv 之上做了 SQL 引擎层。这是非常有效合理的层次划分,这种理念也特别适合用在 Substrate Offchain Storage 未来的改进上面。如果能够嫁接 tikv/tidb 到 Substrate 中来,那么 tikv/tidb 上面的很多生态设施都可以一并用到 Substrate 的链下计算上来,非常美好的局面另外就是代码编写的思维有些变化:Offchain Worker 是定时器思维,或流编程思维。与传统的服务器的 on_request/response 思维有不同。这块儿如何最佳实践,还需要更多研究。对 Web3.0 App 的定义
基于本篇前面章节的讨论,我们可以将区块链进一步做如下区分:用于处理链上资产的链,我们叫它 资产链(Asset Chain)。用于处理 Web3.0 应用数据的使用链下计算范式的链,我们叫它 数据链(Dataset Chain)。基于这种区分,我们可以做出如下示意图: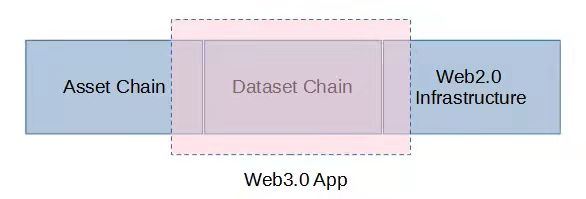
Web3.0 App = Dataset Chain + Asset Chain 的一部分 + 一部分Web2.0已有的基础设施数据链(Dataset Chain)是 Web3.0 App 的核心载体。基于存储共识的链下计算范式实现的 Web3.0 App,其位置处于区块链大生态的边界,一边连接资产区块链,一边连接已有的 Web2.0 基础设施。工具 or 服务?
在本文快要结束的时候,我们来简单做一下关于工具还是服务的思辨。这里的服务,指的是 To B 基础设施层面的服务,而不是 To C 业务型的服务。1.使用一个工具(从某个网站下载,或者别人给你的),在自己的电脑上运行计算,完成2.使用一个服务(通常是通过一个浏览器页面),在服务所在的服务器上运行计算,然后将结果返回给你这就是工具与服务的区别:计算,是在你自己的地盘内完成,还是在第三方的地盘上完成。云服务 IaaS 取得巨大的成功。从以前的自己买服务器托管至机房的模式,到云服务 IaaS,开启了云时代,进而到现在的 k8s,这条路目前还看不到尽头。而相对于 IaaS,更上层的 PaaS 似乎并不成功。反而 SaaS 取得了一定的成功。服务的产生总是滞后的,开始总是先用一些工具(开发框架)进行实践。我们不要忘了,开启了 Web2.0 时代的是什么?是 LAMP(Linux 操作系统,Apache 网页服务器,MariaDB 或 MySQL 数据库,PHP、Perl 或 Python 脚本语言)。而到目前为止,全世界仍然有 30% 的网站由 Wordpress (一个 PHP 建站程序)搭建(更多数据可查看这里[9])。而 Java Spring 框架、Ruby on Rails 以及 Nodejs 等技术栈框架,在整个互联网(Web2.0)的发展过程中,起到了相当重要的作用。这些框架给了你:1.在本地开发调试部署一个完整应用(Web, App)的流程和能力3.在自己申请的云服务器(集群)上运行,自己对应用数据有 100% 的掌控力2.完全无需关注运维的问题,需要的所有扩容都是自动完成的2.准确的计算成本(如果不是免费的话,免费的正式使用顾虑感会更强)对于创业团队来讲,有些场景下力求短平快的服务启动,会倾向于直接使用第三方服务实现。而当业务规模扩张到一定阶段的时候,力求对各个组件的运行实现全面掌控,这时就倾向于用开发框架的配套组件自己来搭建服务了。当然实际情况是往往混搭起来使用。如果考虑文化、地域、国家政策等更多因素,具有自主搭建的能力的需求就更加强烈。最关键的一点是,各方能够自己比较容易地搭建相对完整的的服务,对于 “去中心化” 的实现,是一个非常重要的措施。如果所有人都在用同一个服务,这个服务是不是另一种层面的中心化(不管这个服务的实现本身是中心化的还是去中心化的)?除非特别专业性的服务,一般来说,服务是可选项,开发框架(工具)才是根本立足点。结语
本文我们尝试为 Web3.0 App 设计了一种面向大规模应用的技术路线:基于存储共识的链下计算范式。本文使用 Substrate 框架作为示例来讲解。理论上来说,任何框架都可以实现此计算范式——只有集成度、成熟度的区别。大家可以尝试将此计算范式引入到自己的框架中实践。本文由 Mike Tang 和 Outprog 合作完成。我们的邮箱为:mike@oct.network,outprog@ever.finance,欢迎与我们联系。参考资料
[1]: https://cryptobriefing.com/ethereum-defi-ecosystem-has-hit-3m-users/[2]: https://mp.weixin.qq.com/s/vJM6TIZT2f-tnQ49cpMnrw[3]: https://mp.weixin.qq.com/s/h76lTnFWlvpXs72aBVs3FA[4]: https://near.org/papers/nightshade/[5]: https://www.theblockbeats.com/news/24443[6]: https://mp.weixin.qq.com/s/zXqJ0BGdEbvZypAwLWKmtQ[7]: https://mirror.xyz/0xDc19464589c1cfdD10AEdcC1d09336622b282652/KCYNKCIhFvTZ1DmD7IpXr3p8di31ecC283HgMDqasmU[8]: https://substrate.dev/docs/en/knowledgebase/learn-substrate/off-chain-features#off-chain-indexing[9]: https://techjury.net/blog/percentage-of-wordpress-websites/#gref
第五届PANews年度评选暨 PARTY AWARD 2025 开启投票!
创历届纪录!近300个项目及个人通过数据筛选、公开报名和社区推荐,进入本次评选投票阶段。谁是推动Web3和Crypto走向主流的先锋?点击图片参与投票,为你心目中的年度最佳助力!
点击下方图片立即投票!

作者 :Web3 Explorer
本文为PANews入驻专栏作者的观点,不代表PANews立场,不承担法律责任。文章及观点也不构成投资意见。
图片来源 :
Web3 Explorer
如有侵权,请联系作者删除。