熟悉Web开发流程的同学应该都清楚,开发一个完整的服务器后端,无非要弄清楚几样东西。
1.请求如何接入?是http,restful, 还是 rpc?
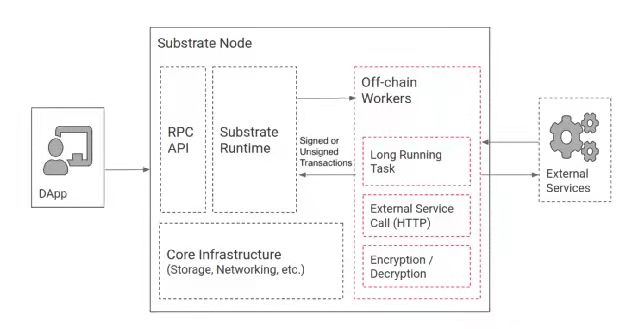
将此模式应用到 Substrate 上,官方给出了如下结构图。在这个图中,Off-chain workers 起到了非常重要的作用。笔者通过对 substrate 的深度分析,在这里给出上图的一个细化图,基于此图,采用 substrate 进行 Web3.0 的开发就就豁然开朗了。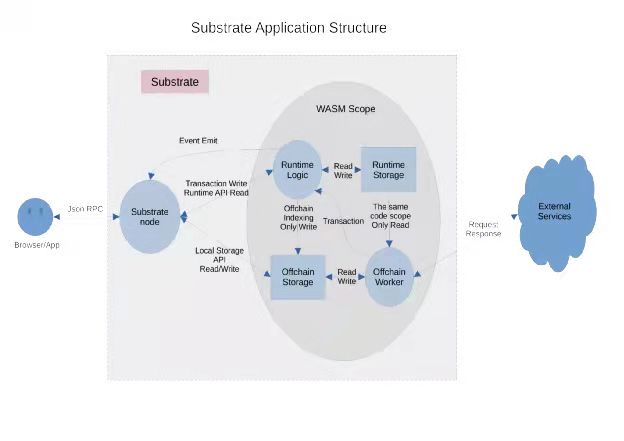
区块链应用开发更加复杂一些,因为涉及到链上链下不同部分的操作。对上图 Substrate Application Structure 的解释如下:
1.外界使用 Json RPC 与 substrate node 进行交互
2.(几乎)所有对链上状态的修改,都应该使用 transaction 提到到 Runtime logic 中进行处理
3.Runtime logic 对 Runtime 的 Storage 具有完全的读写能力。对 Offchain Storage 具有写能力4.Substrate node 能直接对 Offchain Storage 进行读写
5.Offchain Workers 能直接对 Offchain Storage 进行读写,只能读 Runtime Storage 中的东西
6.Offchain Worker 可以提交新的交易来实现对链上状态的更新
7.Offchain Worker 可以请求外部服务,获取相应的数据回来,(异步)更新链上状态或者本地存储
8.Substrate node 可以通过 Runtime API 机制对链上状态进行读取,也可以传参数进 Runtime logic 以更灵活地读状态
9.链上状态的变更,会生成 event,发送到 substrate node 中,经由 rpc 被外界监听到基于 Substrate 这种清晰的结构,我们可以设计一些不同的 Web3.0 应用的编程范式。比如其中一种是:1.所有修改状态的操作,都提交到链上处理。但是链上不一定存储所有信息,可以通过 Offchain Indexing 存一部分到 local storage (offchain storage)
2.所有查询状态的操作,可以只通过 local storage 查询 。或者链下与链上 storage 相结合的方式查询(链上存储代价较大,而链下存储代价小)。
3.Offchain 层可以作为与外界服务完全隔离的缓存层。使得链上逻辑,只需要专注于 substrate 体系本身。而不受外部接口和数据的影响● 直接使用 substrate node 和 offchain storage, offchain worker 部分,实现一个传统的应用服务。完全跟区块链没有关系
● 所有交易先提交到 offchain storage 中,由 offchain worker 监听后,来代理提交交易?:P不过现在 Offchain storage 的能力和接口还比较弱。作为 kv 数据库,功能比 redis 之类差太远。而如果能有一层 sql 数据层就更完整更好用了——能否嵌入一个 sqlite 进去呢? 第五届PANews年度评选暨 PARTY AWARD 2025 开启投票!
创历届纪录!近300个项目及个人通过数据筛选、公开报名和社区推荐,进入本次评选投票阶段。谁是推动Web3和Crypto走向主流的先锋?点击图片参与投票,为你心目中的年度最佳助力!
点击下方图片立即投票!