
過去 1 年間、仮想通貨市場では AI ストーリーテリングが活況を呈しており、a16z、Sequoia、Lightspeed、Polychain などの大手 VC が数千万ドルの賭けに投資しています。科学研究の背景と名門学校の経歴を持つ多くの質の高いチームも Web3 に参入し、分散型 AI への移行を進めています。今後 12 か月間で、私たちはこれらの高品質のプロジェクトが段階的に実施されるのを目の当たりにすることになります。
今年10月、OpenAIはさらに66億ドルを調達し、AI分野での軍拡競争は前例のない高さに達した。個人投資家は、NVIDIA とハードウェアへの直接投資以外でお金を稼ぐ機会がほとんどありません。この熱意は、特に AI ミームに駆り立てられた最近の人々の波のように、仮想通貨にも広がり続けるでしょう。既存の上場トークンであれ、新しいスタープロジェクトであれ、暗号 x AI は依然として強い勢いを持つことが予想されます。
分散型AIのリーディングプロジェクトであるHyperbolicが、最近PolychainとLightspeedから2回目の出資を受けたことを受けて、最近大手機関から大規模融資を受けた6つのプロジェクトからスタートし、Crypto×AIインフラプロジェクトの開発文脈を整理し、 AI の将来においてテクノロジーが人間をどのように守ることができるか、分散化に期待してください。
Hyperbolic: 最近、Variant と Polychain が共同で主導した 1,200 万ドルのシリーズ A 資金調達の完了を発表しました。資金調達総額は、Bankless Ventures、Chapter One、Lightspeed Faction、IOSG、Blockchain Builders Fund、Alumni Ventures、Samsung Next などが 2,000 万ドルを超えました。有名なVC参加。
PIN AI: a16z CSX、Hack VC、Blockchain Builders Fund (Stanford Blockchain Accelerator) などの有名な VC からの投資により、1,000 万ドルのプレシードラウンドの資金調達を完了しました。
Vana: Paradigm、Polychain、Coinbase などの有名な VC からの投資により、シリーズ A 資金調達で 1,800 万米ドル、戦略的資金調達で 500 万米ドルを完了しました。
佐原: Binance Labs、Pantera Capital、Polychain などの有名な VC からの投資により、シリーズ A で 4,300 万米ドルの資金調達を完了しました。
Aethir: 2023 年に 1 億 5,000 万ドルの評価で 900 万ドルのプレ A ラウンドを完了し、2024 年に約 1 億 2,000 万ドルのノード販売を完了します。
IO.NET: Hack VC、Delphi Digital、Foresight Ventures などの有名な VC からの投資により、シリーズ A で 3,000 万米ドルの資金調達を完了しました。
AI の 3 つの要素: データ、計算能力、アルゴリズム
マルクスは『資本論』の中で、生産手段、生産性、生産関係が社会生産における重要な要素であると述べました。たとえて言えば、人工知能の世界にも 3 つの重要な要素があることがわかります。
AI 時代では、コンピューティング能力、データ、アルゴリズムが鍵となります。
AI では、データは生産手段です。たとえば、毎日携帯電話で文字を入力したり、チャットしたり、写真を撮ってモーメントに投稿したりするこれらのテキストや写真はすべてデータであり、AI が動作するための基盤となります。
このデータは、構造化された数値情報から非構造化画像、音声、ビデオ、テキストまで多岐にわたります。データがなければ、AI アルゴリズムは学習して最適化することができません。データの質、量、範囲、多様性は AI モデルのパフォーマンスに直接影響し、特定のタスクを効率的に完了できるかどうかを決定します。
AI では、コンピューティング能力が生産性を表します。コンピューティング能力は、AI アルゴリズムを実行するために必要な基盤となるコンピューティング リソースです。コンピューティング能力が強力であればあるほど、データ処理速度はより速く、より良くなります。コンピューティング能力の強さは、AI システムの効率と機能を直接決定します。
強力なコンピューティング能力により、モデルのトレーニング時間を短縮できるだけでなく、より複雑なモデル アーキテクチャもサポートできるため、AI の知能レベルが向上します。 OpenAI の ChatGPT のような大規模な言語モデルは、強力なコンピューティング クラスターでのトレーニングに数か月かかります。
AI では、アルゴリズムは生産関係です。アルゴリズムは AI の中核であり、その設計はデータとコンピューティング能力がどのように連携するかを決定し、データをインテリジェントな意思決定に変換する鍵となります。強力なコンピューティング能力のサポートにより、アルゴリズムはデータ内のパターンをより適切に学習し、実際の問題に適用できます。
この観点から見ると、データは AI の燃料に相当し、コンピューティング能力は AI のエンジンであり、アルゴリズムは AI の魂です。 AI = データ + コンピューティング能力 + アルゴリズム AI トラックで目立ちたいスタートアップは、3 つの要素をすべて備えているか、そのいずれかで独自の最先端を示す必要があります。
AI がマルチモダリティ (モデルは複数の形式の情報に基づいており、テキスト、画像、音声などを同時に処理できる) に向けて発展しているため、コンピューティング能力とデータの需要は指数関数的に増加する一方です。
コンピューティング能力が不足している時代、暗号は AI を強化します
ChatGPT の出現は、人工知能の革命を引き起こしただけでなく、意図せずしてコンピューティング能力とコンピューティング ハードウェアをテクノロジ検索の最前線に押し上げました。
2023年の「千モデル戦争」を経て、2024年、AI大型モデルに対する市場の理解が深まる中、大型モデルを巡る世界的な競争は「能力向上」と「シナリオ開発」の2つの道に分かれつつある。
大型モデルの機能向上に関して、市場の最大の期待は OpenAI が今年リリースすると噂されている GPT-5 であり、その大型モデルが真のマルチモーダルな段階に押し上げられることが期待されています。
大規模なモデル シーンの開発に関して、AI 大手は、アプリケーションの価値を生み出すために大規模なモデルを業界シナリオに迅速に統合することを推進しています。例えば、AIエージェントやAI検索などの分野における試みは、大規模なモデルを活用することで既存のユーザーエクスペリエンスの向上を常に深めています。
これら 2 つの道の背後には、間違いなくコンピューティング能力に対するより高い需要があります。大規模モデルの機能の向上は主にトレーニングに基づいており、短時間で膨大な高性能のコンピューティング能力を使用する必要があり、大規模モデルのシナリオの適用は主に推論に基づいており、コンピューティング能力に対するパフォーマンス要件は比較的低いです。ですが、安定性と低遅延時間に重点が置かれています。
OpenAI が 2018 年に推定したように、2012 年以来、大規模モデルのトレーニングに必要なコンピューティング パワーは 3.5 か月ごとに 2 倍になり、毎年 10 倍も増加しています。同時に、大規模なモデルやアプリケーションが企業の実際のビジネス シナリオに導入されることが増えているため、推論コンピューティング能力に対する需要も増加しています。
問題は、高性能 GPU の需要が世界中で急速に増加しているにもかかわらず、供給が追いついていないことです。 NVIDIA の H100 チップを例に挙げると、2023 年には深刻な供給不足に陥り、供給ギャップは 43 万ユニットを超えています。次期 B100 チップは、性能が 2.5 倍向上し、コストがわずか 25% 増加するだけですが、再び供給不足に陥る可能性があります。この需要と供給の不均衡により、コンピューティング能力のコストが再び上昇し、多くの中小企業が高いコンピューティングコストを支払うことが困難になり、AI分野での開発の可能性が制限されることになります。
OpenAI、Google、Meta などの大手テクノロジー企業は、より強力なリソース獲得能力を備えており、独自のコンピューティング インフラストラクチャを構築するための資金とリソースを持っています。しかし、AI スタートアップ、ましてやまだ資金調達を行っていないスタートアップはどうでしょうか?
実際、eBay、Amazon、その他のプラットフォームで中古の GPU を購入することも実行可能な方法です。コストは削減されますが、パフォーマンスの問題や長期にわたる修理費用が発生する可能性があります。 GPU が不足しているこの時代、インフラストラクチャの構築はスタートアップにとって決して最適なソリューションではない可能性があります。
オンデマンドでレンタルできる GPU クラウド プロバイダーがあったとしても、価格が高いことも大きな課題です。たとえば、25 個の GPU を実行するために 50 個の GPU が必要な場合、1 日あたり約 80 ドルかかります。現在、コンピューティング能力のコストだけで、月額 80 x 50 x 25 = 100,000 米ドルにも上ります。
これにより、DePIN に基づく分散型コンピューティング パワー ネットワークにこの状況を利用する機会が与えられ、順調に進んでいると言えます。 IO.NET、Aethir、Hyperbolic が行ったように、彼らは AI スタートアップのコンピューティング インフラストラクチャのコストをネットワーク自体に転嫁しています。また、世界中の誰でも自宅の未使用の GPU に接続できるため、コンピューティング コストが大幅に削減されます。
Aethir: グローバル GPU 共有ネットワークにより、コンピューティング能力をユニバーサルに
Aethirは2023年9月に1億5000万ドルの評価額で900万ドルのPre-Aラウンドを完了し、今年3月から5月にかけて約1億2000万ドルのChecker Nodeノードの販売を完了した。 Aethir は、Checker Node の販売からわずか 30 分で 6,000 万ドルの収益を上げました。これは、このプロジェクトに対する市場の認識と期待を示しています。
Aethir の核心は、誰もがアイドル状態の GPU リソースを貢献して利益を得る機会を得られるように、分散型 GPU ネットワークを確立することです。それは、全員のコンピュータを小さなスーパーコンピュータに変えて、全員が計算能力を共有するようなものです。この利点は、GPU 使用率を大幅に向上させ、リソースの無駄を削減できることです。また、多くのコンピューティング能力を必要とする企業や個人が、必要なリソースを低コストで入手できるようになります。
Aethir は、リソース プールのように機能する分散型 DePIN ネットワークを構築し、世界中のデータ センター、ゲーム スタジオ、テクノロジー企業、ゲーマーにアイドル状態の GPU を接続するよう促しています。これらの GPU プロバイダーは、GPU をネットワークに自由にオン/オフできるため、アイドル状態の場合よりも使用率が高くなります。これにより、Aethir はコンシューマ レベル、プロフェッショナル レベル、データ センター レベルの GPU リソースを、Web2 クラウド プロバイダーよりも 80% 以上安い価格でコンピューティング電力需要者に提供できるようになります。
Aethir の DePIN アーキテクチャは、これらの分散されたコンピューティング能力の品質と安定性を保証します。最も核となる 3 つの部分は次のとおりです。
コンテナは Aethir のコンピューティング ユニットであり、クラウド サーバーとして機能し、アプリケーションの実行とレンダリングを担当します。各タスクは、顧客のタスクを実行するための比較的独立した環境として独立したコンテナにカプセル化され、タスク間の相互干渉を回避します。
インデクサーは主に、タスクの要件に応じて利用可能なコンピューティング リソースを即座に照合し、スケジュールするために使用されます。同時に、動的リソース調整メカニズムにより、ネットワーク全体の負荷に基づいてリソースをさまざまなタスクに動的に割り当て、最高の全体的なパフォーマンスを実現できます。
Checker は、コンテナのパフォーマンスのリアルタイム監視と評価を担当し、ネットワーク全体のステータスをリアルタイムで監視および評価し、潜在的なセキュリティ問題にタイムリーに対応します。ネットワーク攻撃などのセキュリティインシデントに対応する必要がある場合、異常な動作を検知した後、速やかに警告を発し、保護措置を開始できます。同様に、ネットワーク パフォーマンスのボトルネックが発生した場合、Checker はタイムリーなリマインダーを送信して、問題を迅速に解決し、サービスの品質とセキュリティを確保することもできます。

Container、Indexer、Checker の効果的な連携により、自由にカスタマイズされたコンピューティング能力構成、安全で安定した比較的低価格のクラウド サービス エクスペリエンスを顧客に提供します。 Aethir は、AI やゲームなどの分野に適した商用グレードのソリューションです。
一般に、Aethir は DePIN を通じて GPU リソースの割り当てと使用を再構築し、コンピューティング能力をより一般的かつ経済的にします。 AIとゲームの分野で一定の成果を上げており、パートナーとビジネスラインを継続的に拡大しており、将来の発展の可能性は無限です。
IO.NET: コンピューティング能力のボトルネックを打破する分散型スーパーコンピューティング ネットワーク
IO.NETは、Hack VC、Delphi Digital、Foresight Venturesなどの著名なVCからの投資を受け、今年3月に3,000万ドルのシリーズA資金調達ラウンドを完了した。
Aethir と同様に、エンタープライズレベルの分散コンピューティング ネットワークを構築し、世界中の遊休コンピューティング リソース (GPU、CPU) を収集することで、AI スタートアップ企業に低価格で入手しやすく、より柔軟に適応できるコンピューティング サービスを提供します。
Aethir とは異なり、IO.NET は Ray フレームワーク (IO-SDK) を使用して、数千の GPU クラスターを全体に変換して機械学習を提供します (Ray フレームワークは、GPT-3 をトレーニングするために OpenAI によっても使用されます)。 CPU/GPU メモリの制限と逐次処理ワークフローは、単一デバイスで大規模なモデルをトレーニングする場合に重大なボトルネックになります。 Ray フレームワークは、並列コンピューティング タスクを実現するためのオーケストレーションとバッチ処理に使用されます。
これを行うために、IO.NET はマルチレイヤー アーキテクチャを使用します。
ユーザー インターフェイス レイヤー: 直感的でフレンドリーなユーザー エクスペリエンスを提供することを目的として、公開 Web サイト、顧客エリア、GPU サプライヤー エリアなどの視覚的なフロントエンド インターフェイスをユーザーに提供します。
セキュリティ層: ネットワーク保護、ユーザー認証、アクティビティ ログ、その他のメカニズムを統合して、システムの整合性とセキュリティを保証します。
API レイヤー: Web サイト、サプライヤー、内部管理の通信ハブとして、データ交換とさまざまな操作の実行を容易にします。
バックエンド層: システムの中核を形成し、クラスター/GPU 管理、顧客との対話、自動拡張などの運用タスクを担当します。
データベース層: データのストレージと管理を担当し、メイン ストレージは構造化データを担当し、キャッシュは一時的なデータ処理に使用されます。
タスク層: 非同期通信とタスクの実行を管理し、データの処理と流通の効率を確保します。
インフラストラクチャ層: GPU リソース プール、オーケストレーション ツール、実行/ML タスクなどのシステムの基礎を形成し、強力な監視ソリューションを備えています。
技術的な観点から見ると、分散コンピューティング能力が直面する問題を解決するために、IO.NET は、コア テクノロジー IO-SDK のレイヤード アーキテクチャに加え、安全な接続と安全な接続を解決するためのリバース トンネル テクノロジーとメッシュ VPN アーキテクチャを立ち上げました。データプライバシーの問題。 Web3 で人気があり、次のファイルコインと呼ばれており、明るい将来性があります。
一般に、IO.NET の中心的な使命は、世界最大の DePIN インフラストラクチャを構築し、世界中のアイドル状態の GPU リソースをプールし、多くのコンピューティング能力を必要とする AI および機械学習分野のサポートを提供することです。
双曲型: 「AI 熱帯雨林」を作成し、豊かで相互支援的な分散型 AI インフラストラクチャ エコシステムを実現する
本日、Hyperbolic は、Variant と Polychain Capital が共同主導し、総額 2,000 万米ドルを超える、総額 1,200 万米ドルを超えるシリーズ A 資金調達を完了したことを再度発表しました。 Bankless Ventures、Chapter One、Lightspeed Faction、IOSG、Blockchain Builders Fund、Alumni Ventures、Samsung Next などの有名な VC 機関が投資に参加しました。その中で、シリコンバレーの大手ベンチャーキャピタル企業であるPolychainとLightSpeed Factionは、シードラウンド後に2回目の投資を増やしており、これはWeb3 AIトラックにおけるHyperbolicの主導的地位を示すのに十分です。
Hyperbolic の中心的な使命は、AI を誰もが利用できるようにすること、開発者にとって手頃な価格、クリエイターにとっても手頃な価格で AI を利用できるようにすることです。 Hyperbolic は、開発者がそのエコシステム内で革新、協力、成長するために必要なリソースを見つけられる「AI 熱帯雨林」の構築を目指しています。まさに自然の熱帯雨林と同じように、生態系は相互につながり、活気に満ち、再生可能であるため、クリエイターは無制限に探索することができます。
2 人の共同創設者である Jasper 氏と Yuchen 氏の見解では、AI モデルはオープンソースにすることができますが、オープン コンピューティング リソースがなければ十分ではありません。現在、多くの大規模データセンターが GPU リソースを制御しているため、AI を使用したいと思う多くの人が意欲を失っています。 Hyperbolic は、世界中の遊休コンピューティング リソースを統合して DePIN コンピューティング インフラストラクチャを構築し、誰もが簡単に AI を利用できるようにすることを目指しています。
そこで、Hyperbolic は、パーソナル コンピューターから大規模なデータセンターまで、あらゆるものを Hyperbolic に接続してコンピューティング能力を提供できるという「オープン AI クラウド」の概念を導入しました。これに基づいて、Hyperbolic は検証可能でプライバシーを強化する AI レイヤーを作成します。これにより、開発者は推論機能を備えた AI アプリケーションを構築できるようになり、必要なコンピューティング能力は AI クラウドから直接供給されます。

Aethir や IO.NET と同様に、Hyperbolic の AI クラウドには、「Solar System Cluster」と呼ばれる独自の GPU クラスター モデルがあります。ご存知のとおり、太陽系には水星や火星などのさまざまな独立した惑星が含まれており、Hyperbolic の太陽系クラスターは、たとえば、水星クラスター、火星クラスター、木星クラスターなど、さまざまな用途とさまざまなサイズを管理します。しかし、それらは太陽系によって互いに独立して送信されます。
このようなモデルにより、GPU クラスターが次の 2 つの特性を満たし、 Aethir や IO.NET と比較して柔軟性が高まり、効率が最大化されます。
状態バランスを調整すると、GPU クラスターは需要に応じて自動的に拡張または縮小します。
クラスターで障害が発生した場合、Solar System クラスターが自動的に検出して修復します。
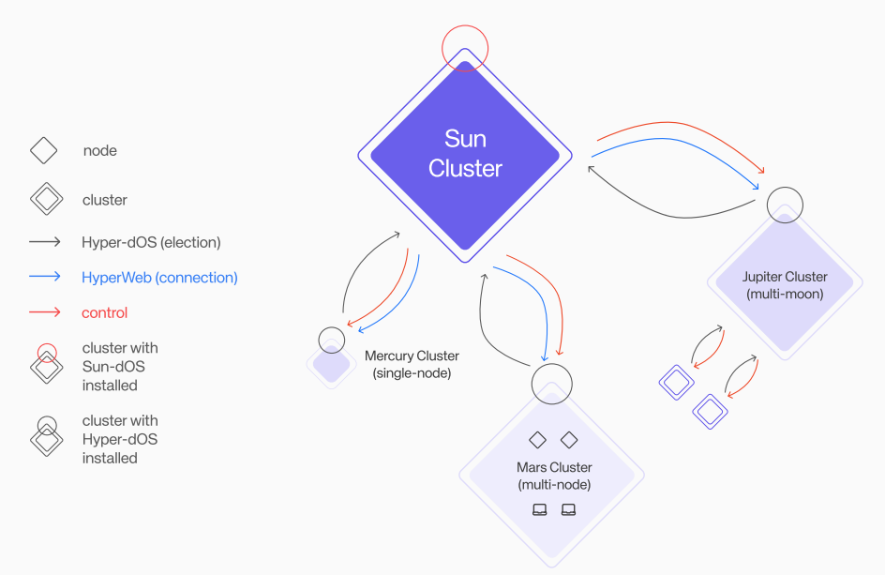
大規模言語モデル (LLM) のパフォーマンス比較実験では、Hyperbolic GPU クラスターのスループットは 43 トークン/秒と高く、この結果は 60 人の Together AI チームの 42 トークン/秒を上回っただけでなく、また、チーム メンバーが 300 名を超える HuggingFace の 27 トークン/秒よりも大幅に高くなっています。
画像生成モデルの生成速度の比較実験でも、Hyperbolic GPU クラスターの技術力を過小評価すべきではないことが実証されました。また、SOTA オープンソース イメージ生成モデルを使用する Hyperbolic は、17.6 イメージ/分の生成速度でリードしており、Togetter AI の 13.6 イメージ/分を上回るだけでなく、IO.NET の 6.5 イメージ/分よりもはるかに高速です。
これらのデータは、Hyperbolic の GPU クラスター モデルが非常に効率が高く、その優れたパフォーマンスにより、大規模な競合他社の中で際立っていることを強く証明しています。低価格という利点と組み合わせることで、Hyperbolic は高いコンピューティング能力のサポートを必要とする複雑な AI アプリケーションに非常に適しており、ほぼリアルタイムの応答を提供し、複雑なタスクを処理する際に AI モデルの精度と効率が高くなります。
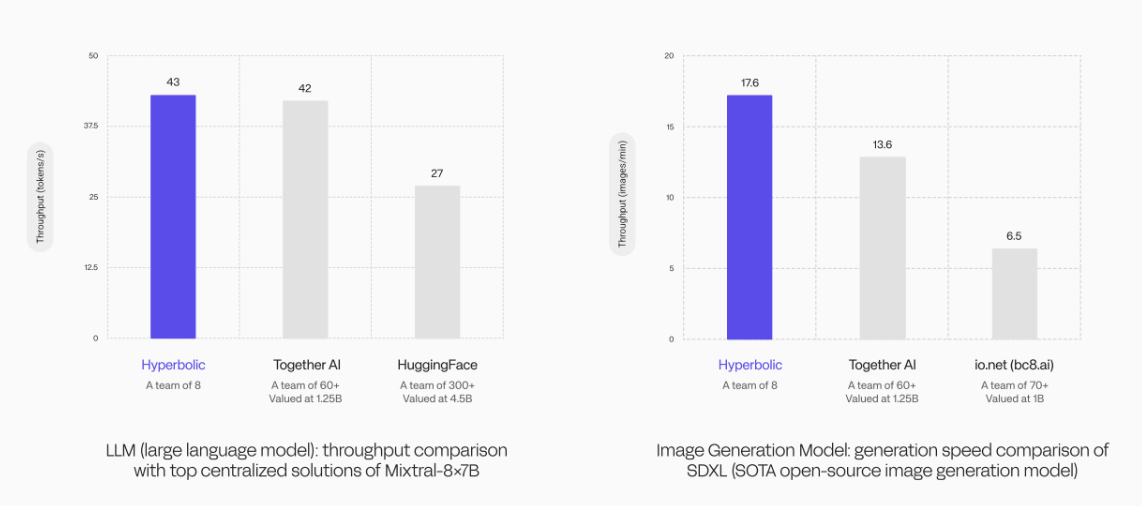
さらに、暗号化イノベーションの観点から、Hyperbolic の最も注目すべき成果は、AI における最も困難な課題の 1 つを分散型アプローチで解決する検証メカニズム PoSP (Proof of Sampling、Sampling Proof) の開発であると考えています。フィールド - 指定されたモデルからの出力が正しいかどうかを検証し、推論プロセスをコスト効率よく分散できるようにします。

PoSP 原理に基づいて、Hyperbolic チームは、AI アプリケーション用の spML メカニズム (サンプリング機械学習) を開発しました。これは、ネットワーク内のトランザクションをランダムにサンプリングし、正直な人に報酬を与え、不誠実な人を罰することで軽量の検証効果を実現し、計算の負担を軽減します。ネットワークの負荷により、ほぼすべての AI スタートアップは分散検証パラダイムで AI サービスを分散化できます。
具体的な実装プロセスは次のとおりです。
1) ノードは関数を計算し、結果を暗号化された方法でオーケストレーターに送信します。
2) この結果を信頼するかどうかはオーケストレーターが決定し、信頼する場合は計算に対してノードに報酬が与えられます。
3) 信頼がない場合、オーケストレーターはネットワーク内のバリデーターをランダムに選択し、ノードにチャレンジし、同じ関数を計算します。同様に、検証者は結果を暗号化された方法でオーケストレーターに送信します。
4) 最後に、オーケストレーターはすべての結果が一貫しているかどうかをチェックし、一貫している場合はノードと検証者の両方が報酬を受け取ります。一貫していない場合は、各結果の計算プロセスを追跡するための調停手順が開始されます。正直な人はその正確さで報われ、不正直な人はシステムを不正行為したことで罰せられます。
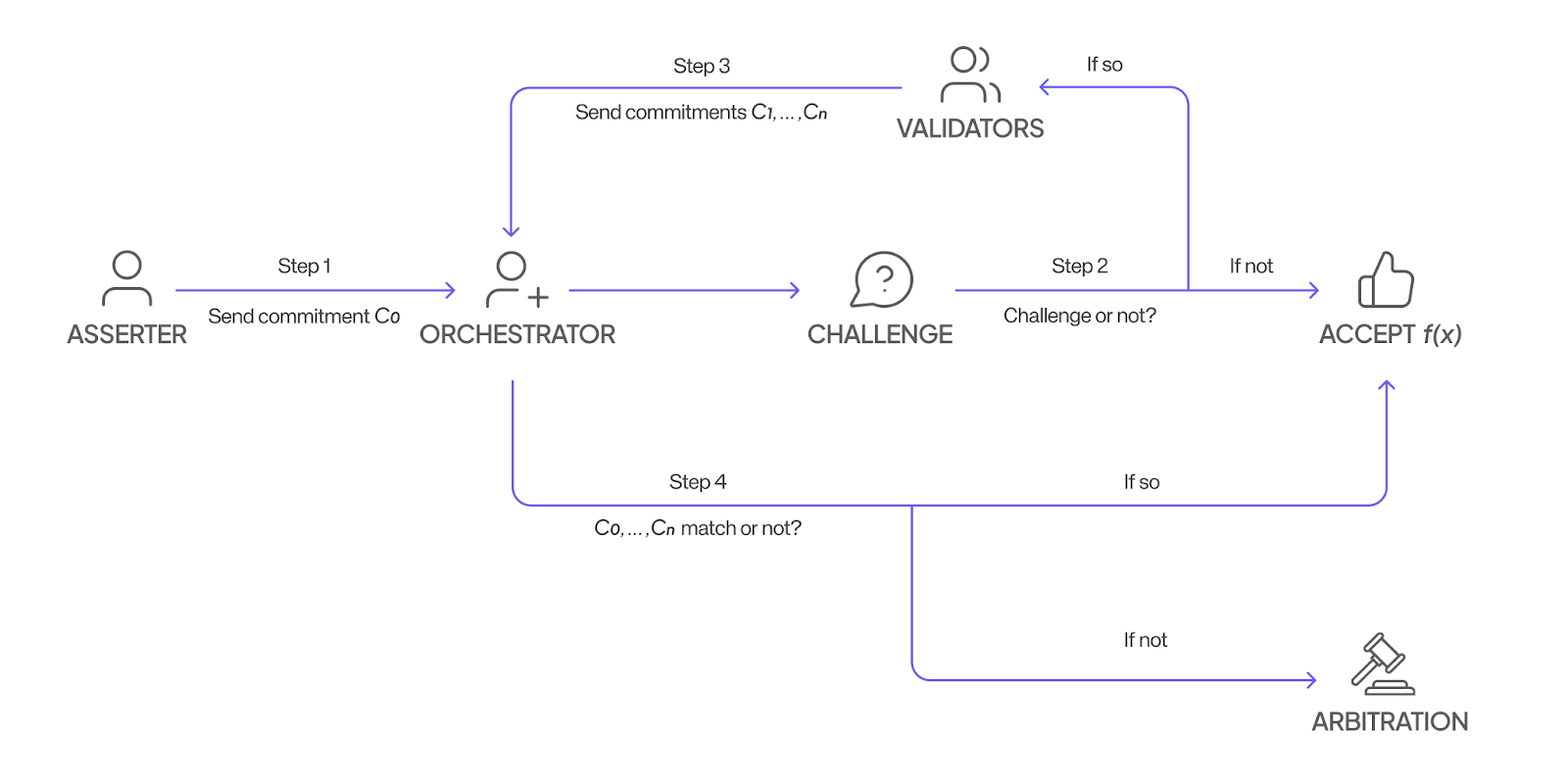
ノードには、送信した結果が異議を申し立てられるかどうかはわかりません。また、検証の公平性を確保するために、オーケストレーターがどのバリデーターに異議を申し立てることを選択するかもわかりません。不正行為のコストは、潜在的な利益をはるかに上回ります。
将来 spML がテストされれば、AI アプリケーションのゲームのルールを変更し、トラストレス推論検証を実現するだけで十分です。さらに、Hyperbolic は、モデル推論に BF16 アルゴリズムを適用する業界で独自の能力を備えており (競合他社はまだ FP8 に留まっています)、これにより推論の精度を効果的に向上させることができ、Hyperbolic の分散推論サービスのコスト効率が非常に高くなります。
さらに、Hyperbolic のイノベーションは、AI クラウド コンピューティング電源と AI アプリケーションの統合にも反映されています。分散型コンピューティング能力市場自体の需要は比較的稀であり、Hyperbolic は、検証可能な AI インフラストラクチャを構築することで、パフォーマンスとセキュリティを犠牲にすることなく AI アプリケーションを構築する開発者を惹きつけています。自給自足でき、需要と供給のバランスが取れます。
開発者は、コンピューティング能力、Hyperbolic 上の Web2 および Web3 を中心に、次のような革新的な AI アプリケーションを構築できます。
GPU Exchange は、GPU ネットワーク (オーケストレーション層) 上に構築された GPU 取引プラットフォームであり、無料取引のために「GPU リソース」を商用化し、コンピューティング能力のコスト効率を高めます。
IAO、つまり AI エージェントのトークン化により、貢献者はトークンを獲得でき、AI エージェントの収益はトークン所有者に分配されます。
AI-driven DAO は、人工知能を通じてガバナンスの意思決定と財務管理を支援する DAO です。
GPU 再ステーキングを使用すると、ユーザーは GPU を Hyperbolic に接続し、それを AI アプリケーションにステーキングできます。
全体として、Hyperbolic は、誰もが AI を簡単に使用できるオープン AI エコシステムを確立しました。 Hyperbolic は、技術革新を通じて AI の普及と利用しやすさを高め、AI の未来を相互運用性と互換性に満ちたものにし、共同イノベーションを促進します。
データはユーザーに戻り、私たちは AI の波に加わります
今日、データは宝の山であり、個人データはテクノロジー大手によって無料で取得され、商品化されています。
データは AI の食料です。高品質のデータがなければ、最先端のアルゴリズムもその役割を果たせません。データの量、質、多様性は AI モデルのパフォーマンスに直接影響します。
前述したように、業界は GPT-5 の発売を心待ちにしています。しかし、データ量がまだ十分ではないためか、長らく公開されていませんでした。論文出版段階の GPT-3 だけでも 2 兆トークンのデータが必要です。 GPT-5 のデータ量は 200 兆トークンに達すると予想されています。既存のテキスト データに加えて、クリーンアップ後にトレーニングに使用できる、より多くのマルチモーダル データが必要です。
今日の公開インターネット データには、高品質のデータ サンプルが比較的少ないため、現実的な状況として、大規模なモデルはどの分野でも質問と回答の生成では非常に優れたパフォーマンスを発揮しますが、専門的な分野で問題に直面するとパフォーマンスが低下し、失敗することさえあります。モデルが「真面目にくだらない話をしている」かのような錯覚がある。
データの「鮮度」を確保するために、AI 大手企業は大規模なデータ ソースの所有者と契約を結ぶことがよくあります。たとえば、OpenAI は Reddit と 6,000 万ドルの契約を締結しました。
最近、一部のソーシャル ソフトウェアでは、ユーザーがサードパーティの AI モデルのトレーニングに使用するコンテンツを承認することに同意するよう、ユーザーに契約への署名を要求し始めていますが、これによってユーザーは何の報酬も受け取っていません。この略奪的な行為は、データを使用する権利に対する国民の疑念を引き起こしました。
明らかに、ブロックチェーンの分散型で追跡可能な可能性は、ユーザー データの制御と透明性を高めながら、データとリソースの取得のジレンマを改善するのに自然に適しており、AI モデルのトレーニングと最適化に参加することで利点を得ることができます。データ価値を生み出すこの新しい方法により、ユーザーの参加が大幅に増加し、エコシステム全体の繁栄が促進されます。
Web3 にはすでに、次のような AI データをターゲットとする企業がいくつかあります。
データ取得:Ocean Protocol、Vana、PIN AI、Saharaなど
データ処理:パブリックAI、Lightworksなど
中でも興味深いのは、Vana、PIN AI、Saraha で、いずれも最近多額の資金調達を受け、豪華な投資家を擁しています。どちらのプロジェクトもサブ分野を超えて、データ収集と AI 開発を組み合わせて AI アプリケーションの実装を促進します。
Vana: ユーザーがデータを制御し、DAO と貢献メカニズムが AI データ エコノミーを再構築する
Vanaは2022年12月に1,800万ドルの資金調達ラウンドを完了し、今年9月には500万ドルの戦略的資金調達を完了した。 Paradigm、Polychain、Coinbase などの有名な VC からの投資。
Vanaのコアコンセプトは「ユーザー所有のデータ、ユーザー所有のAIの実現」です。データが王様であるこの時代において、Vana は大企業によるデータの独占を打ち破り、ユーザーが自分のデータを管理し、自分のデータから利益を得られるようにしたいと考えています。
Vana はプライベート データの保護に重点を置いた分散型データ ネットワークで、ユーザーのデータを金融資産と同じように柔軟に使用できるようにします。 Vana は、データ エコノミーの状況を再構築し、ユーザーを受動的データ プロバイダーから積極的に参加し、相互に利益をもたらすエコシステム構築者に変えようとしています。
このビジョンを実現するために、Vana ではユーザーがデータ DAO を通じてデータを集約してアップロードし、貢献証明メカニズムを通じてプライバシーを保護しながらデータの価値を検証できるようにします。このデータは AI トレーニングに使用でき、ユーザーはアップロードしたデータの品質に基づいてインセンティブを受け取ります。
実装に関して、Vana の技術アーキテクチャには、データ モビリティ レイヤー、データ ポータビリティ レイヤー、ユニバーサル接続グループ、アンマネージド データ ストレージ、分散型アプリケーション レイヤーの 5 つの主要コンポーネントが含まれています。
データ流動性レイヤー: これは Vana ネットワークの中核であり、データ流動性プール (DLP) を通じて貴重なデータを奨励、集約、検証します。 DLP は、「流動性プール」のデータ バージョンのようなもので、Reddit、Twitter、その他のソーシャル メディア データなど、特定の種類のデータ資産を集約するように設計されたスマート コントラクトです。
データ ポータビリティ レイヤー: このコンポーネントはユーザー データにポータビリティを提供し、ユーザーが異なるアプリケーションや AI モデル間でデータを簡単に転送して使用できるようにします。
データ エコロジー マップ: これは、エコシステム全体にわたるリアルタイムのデータ フローを追跡し、透明性を確保するマップです。
アンマネージド データ ストレージ: Vana の革新性は、ユーザーが自分のデータを常に完全に制御できるようにする独自のデータ管理アプローチにあります。ユーザーの元のデータはチェーンにアップロードされませんが、保存場所はクラウド サーバーや個人サーバーなど、ユーザーが選択します。
分散型アプリケーション層: データに基づいて、Vana はオープン アプリケーション エコシステムを構築しました。開発者は DLP によって蓄積されたデータを使用して、AI アプリケーションを含むさまざまな革新的なアプリケーションを構築でき、データ貢献者はこれらのアプリケーションから利益を得ることができます。
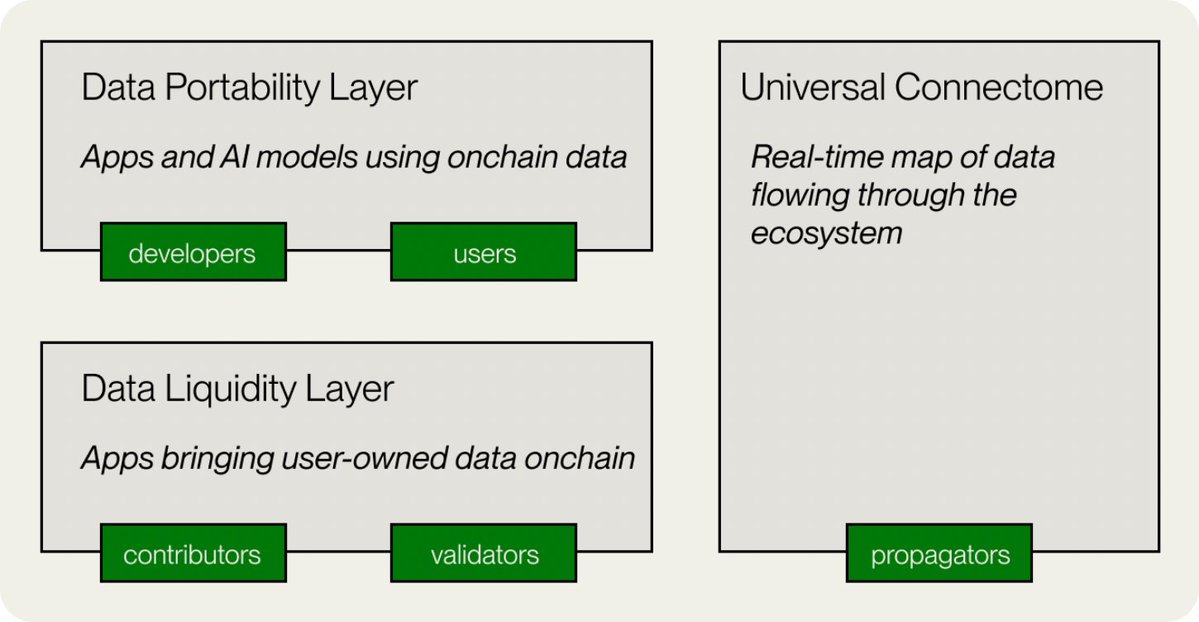
現在、Vana は、ChatGPT、Reddit、LinkedIn、Twitter などのソーシャル メディア プラットフォームと、AI や閲覧データに重点を置いた DLP を中心に構築されています。より多くの DLP が参加し、より革新的なアプリケーションがプラットフォーム上に構築されるにつれて、Vana は次のような可能性を秘めています。次世代の分散型 AI およびデータ経済インフラになります。
これは、LLM の多様性を改善するために、Meta が英国の Facebook と Instagram のユーザーからデータを収集していることを思い出させますが、ユーザーが「同意」ではなく「オプトアウト」を選択できるようにしていると批判されています。 。おそらく、Meta にとっては、Vana 上に Facebook と Instagram の DLP をそれぞれ構築する方が良い選択となるでしょう。これにより、データのプライバシーが確保されるだけでなく、より多くのユーザーが積極的にデータを投稿することが奨励されます。
PIN AI: 分散型 AI アシスタント、モバイル AI がデータと日常生活を結びつける
PIN AIは今年9月に1,000万ドルのプレシードラウンドの資金調達を完了し、a16z CSX、Hack VC、Blockchain Builders Fund (Stanford Blockchain Accelerator)などの多くの著名なVCやエンジェル投資家がこの投資に参加した。
PIN AI は、DePIN アーキテクチャの分散データ ストレージ ネットワークによってサポートされるオープン AI ネットワークであり、ユーザーはデバイスをネットワークに接続し、個人データ/ユーザー設定を提供し、トークン インセンティブを取得できます。この動きにより、ユーザーはデータの制御を取り戻し、収益化できるようになります。開発者はデータを使用して、有用な AI エージェントを構築できます。
そのビジョンは、Apple Intelligence に代わる分散型の代替手段となることであり、日常生活に役立つアプリケーションをユーザーグループに提供し、オンラインでの商品の購入、旅行の計画、投資行動の計画などのユーザーの意図を実現することに取り組んでいます。
PIN AIはパーソナルAIアシスタントと外部AIサービスの2種類のAIで構成されています。
パーソナル AI アシスタントは、ユーザー データにアクセスし、ユーザーのニーズを収集し、必要なときに外部サービス AI に適切なデータを提供できます。 PIN AI の最下層は、DePIN 分散データ ストレージ ネットワークで構成されており、ユーザーの個人プライバシーにアクセスすることなく、外部 AI サービスの推論のための豊富なユーザー データを提供します。
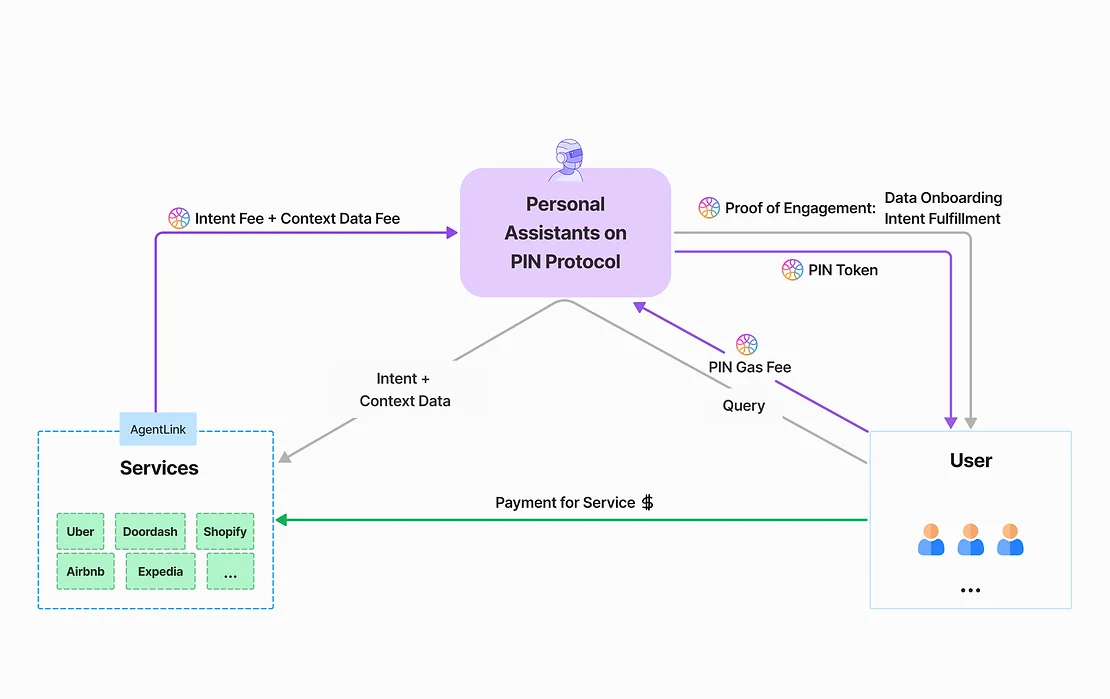
PIN AI を使用すると、ユーザーはさまざまなタスクを完了するために何千ものモバイル アプリを開く必要がなくなります。ユーザーがパーソナル AI アシスタントに「新しい服を買いたい」「どんなテイクアウトを注文しようか」「私の記事から最適な投資機会を見つけて」などの意思を表明すると、AI はユーザーの好みを理解するだけでなく、これらすべてのタスクを効率的に実行することもできます。最も関連性の高いアプリケーションとサービス プロバイダーが、競争入札プロセスの形式でユーザーの意図を実現することがわかります。
最も重要なことは、PIN AI が、ユーザーがサービスを取得するために集中型サービスプロバイダーと直接対話することに慣れている現在のジレンマの下で、より多くの価値を提供できる分散型サービスを導入する必要性を認識していることです。パーソナル AI アシスタントは、ユーザーが Web2 アプリケーションと対話するときに生成される高価値のデータをユーザーの名前で合法的に取得し、分散された方法で保存して呼び出すことができるため、同じデータがより大きな価値を発揮できるようになり、データ所有者が許可することができます。発信者にもメリットがあります。
PIN AI メインネットはまだ正式に開始されていませんが、チームはビジョンの認識を容易にするために、Telegram を通じて製品プロトタイプをユーザーにある程度デモしました。
Hi PIN Bot は、Play、Data Connectors、AI Agent の 3 つのセクションで構成されています。
Play は、PIN AI-1.5b、Gemma、Llama などの大規模モデルを搭載した AI バーチャル コンパニオンです。 PIN AI のパーソナル AI アシスタントに相当します。
データ コネクタでは、ユーザーは Google、Facebook、X、および Telegram アカウントに接続して、仮想コンパニオンをアップグレードするためのポイントを獲得できます。将来的には、ユーザーが Amazon、Ebay、Uber などのアカウントに接続することもサポートされる予定です。これは、PIN AI のDePIN データ ネットワークに相当します。
データを接続した後、ユーザーはバーチャル コンパニオン (近日公開予定) に要件を提示でき、バーチャル コンパニオンはタスク要件を満たすユーザーのデータを AI エージェントに提供します。処理。
公式はいくつかの AI エージェントのプロトタイプを開発しましたが、これらはまだテスト段階にあります。これらは PIN AI の外部 AI サービスに相当します。例えばX Insightは、Twitterアカウントを入力すると、そのアカウントの動作を分析することができます。データ コネクタが e コマース、テイクアウト、その他のプラットフォーム アカウントをサポートする場合、ショッピングやオーダー フードなどの AI エージェントも、ユーザーの注文を自律的に処理する役割を果たすことができます。
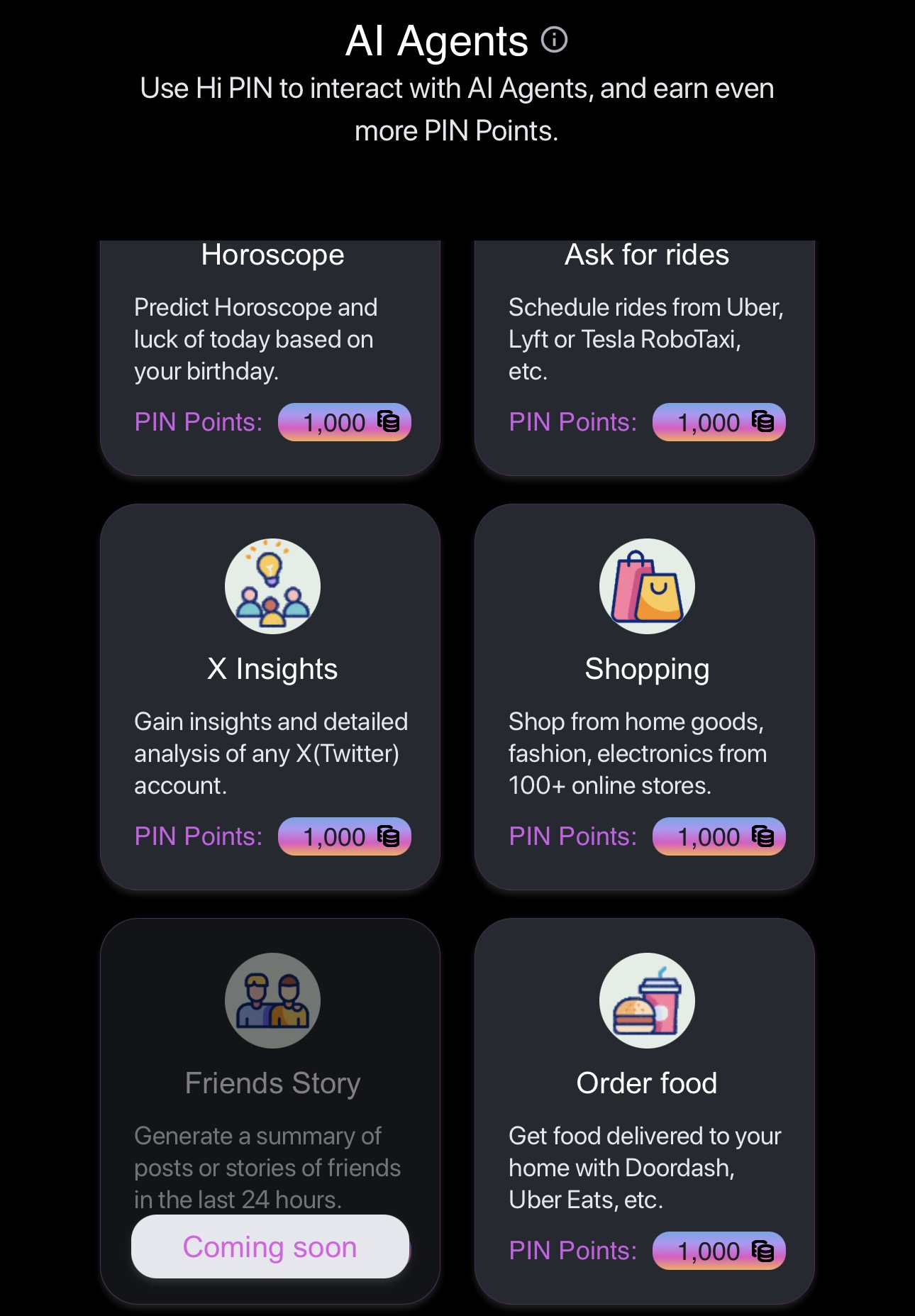
一般に、PIN AI は DePIN+AI の形式を通じてオープン AI ネットワークを確立し、開発者が真に有用な AI アプリケーションを構築できるようにし、ユーザーの生活をより便利でスマートにします。より多くの開発者が参加するにつれて、PIN AI はより革新的なアプリケーションをもたらし、AI を日常生活に真に統合することになります。
佐原氏: マルチレイヤー アーキテクチャが AI データの所有権、プライバシー、公正な取引をリードします
サハラ氏は今年8月、Binance Labs、Pantera Capital、Polychainなどの有名VCからの投資を受けて、シリーズA資金調達で4,300万米ドルを完了した。
Sahara AI は、データに価値を帰し、ユーザーに利益を分配し、従来のプライバシーとセキュリティの問題を解決できる、AI 時代におけるより公平で透明性の高い AI 開発モデルの確立に焦点を当てた多層アーキテクチャの AI ブロックチェーン アプリケーション プラットフォームです。 AI システム、データ取得と透明性。
平たく言えば、Sahara AI は、ユーザーが自分のデータを制御し、提供したデータの品質に基づいて報酬を受け取ることができる分散型 AI ネットワークを構築したいと考えています。このようにして、ユーザーはもはや受動的なデータプロバイダーではなく、参加してメリットを共有できるエコシステム構築者となります。
ユーザーは、分散型データ マーケットプレイスにデータをアップロードし、特別なメカニズムを使用してデータの所有権を証明できます (「確認」)。このデータは AI のトレーニングに使用でき、ユーザーはデータの品質に基づいて報酬を受け取ります。
Sahara AI には、アプリケーション、トランザクション、データ、実行の 4 層アーキテクチャが含まれており、AI エコシステムの開発に強力な基盤を提供します。
アプリケーション層: 安全な保管庫、分散型 AI データ マーケット、ノーコード ツールキット、Sahara ID などのツールを提供します。これらのツールは、データのプライバシーを確保し、ユーザーへの公正な報酬を促進し、AI アプリケーションの作成と展開のプロセスをさらに簡素化します。
簡単に言えば、保管庫は高度な暗号化技術を使用して AI データの安全性を確保し、分散型 AI データ市場をデータの収集、注釈、変換に使用でき、コード不要のツールキットにより AI アプリケーションの開発が可能になります。さらにシンプルなのは、Sahara ID がユーザーの評判を管理し、信頼を確保することです。
トランザクション層: Sahara ブロックチェーンは、ネットワークの効率と安定性を確保するためにプルーフ オブ ステーク (PoS) コンセンサス メカニズムを使用しており、悪意のあるノードが存在する場合でもコンセンサスに達することができます。さらに、Sahara のネイティブ プリコンパイル機能は、AI 処理を最適化するように特別に設計されており、ブロックチェーン環境で直接効率的な計算を実行してシステム パフォーマンスを向上させることができます。
データ層: チェーン内外のデータを管理します。オンチェーン データは追跡不可能な操作と属性レコードを処理して信頼性と透明性を確保し、オフチェーン データは大規模なデータ セットを処理し、マークル ツリーとゼロ知識証明テクノロジーを使用してデータの重複と改ざんを防止するデータの整合性とセキュリティを確保します。
実行層: ボールト、AI モデル、AI アプリケーションの操作を抽象化し、さまざまな AI トレーニング、推論、サービス パラダイムをサポートします。
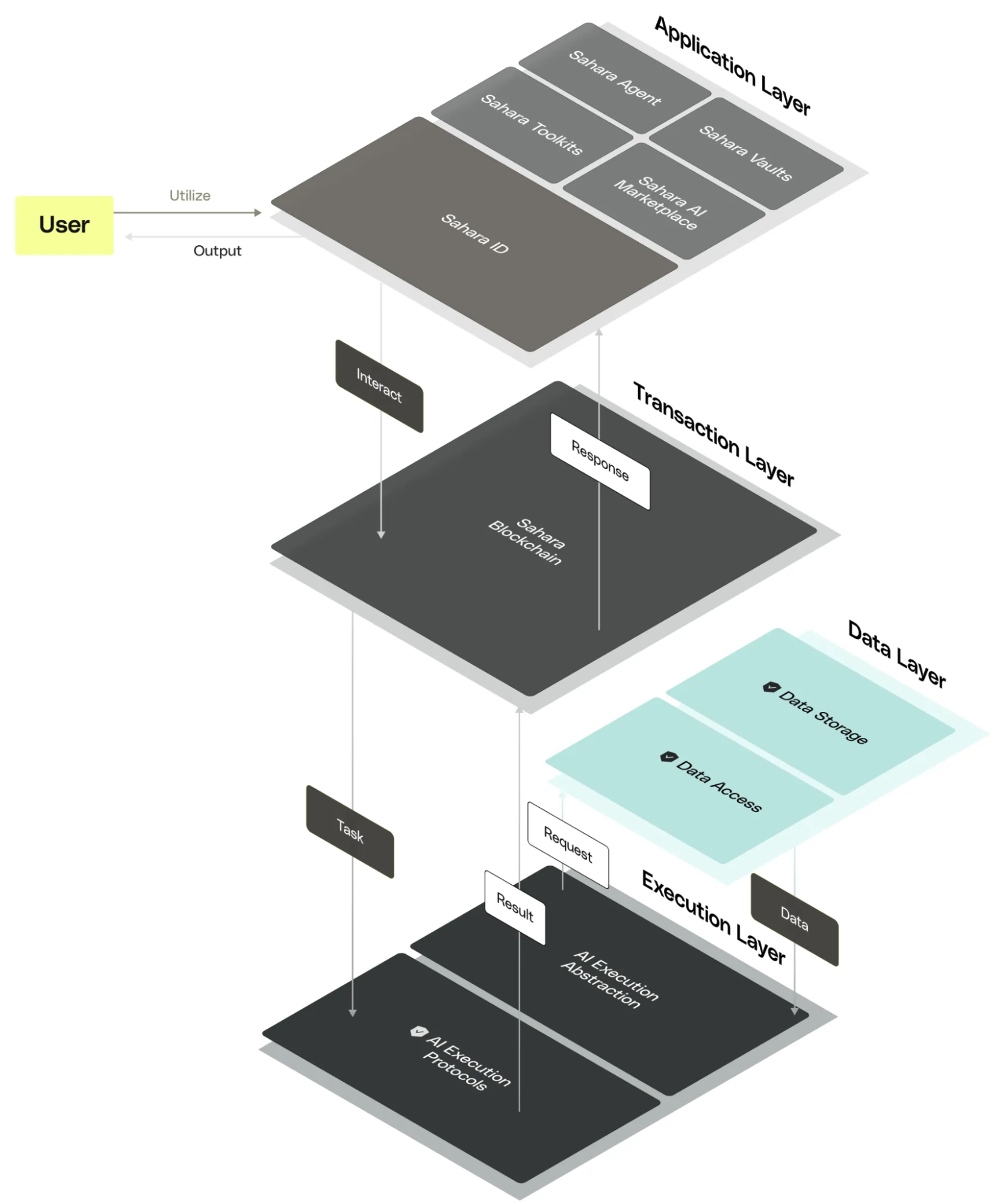
4 層アーキテクチャ全体は、システムのセキュリティとスケーラビリティを確保するだけでなく、AI テクノロジーのアプリケーション モデルを完全に変更し、より多くの革新と革新をもたらすことを目的として、コラボレーション経済と AI 開発を促進するという Sahara AI の長期ビジョンを反映しています。ユーザーへの公平性。
結論
AI テクノロジーの継続的な進歩と暗号化市場の台頭により、私たちは新たな時代の入り口に立っています。
大規模な AI モデルとアプリケーションが出現し続けるにつれて、コンピューティング能力の需要も急激に増加しています。しかし、コンピューティング能力の不足とコストの上昇は、多くの中小企業にとって大きな課題となっています。幸いなことに、分散型ソリューション、特に Hyperbolic、Aethir、IO.NET は、AI スタートアップ企業にコンピューティング能力を獲得し、コストを削減し、効率を向上させる新しい方法を提供します。
同時に、AI の開発におけるデータの重要性も認識しています。データはAIの食料であるだけでなく、AIアプリケーションの実装を促進するための鍵でもあります。 PIN AI や Sahara などのプロジェクトは、ネットワークを動機付け、ユーザーのデータ収集と共有への参加を奨励することで、AI の開発に強力なデータ サポートを提供します。
AI アプリケーションの場合、コンピューティング能力とデータは単なるトレーニング リンクではありません。データの取り込みから本番推論に至るまで、各リンクでは大量のデータを処理するためにさまざまなツールを使用する必要があり、これは常に繰り返されるプロセスです。
この AI と暗号の絡み合った世界では、将来、より革新的な AI プロジェクトの実装が目撃され、これらのプロジェクトは私たちの仕事やライフスタイルを変えるだけでなく、社会全体のよりインテリジェント化を促進すると信じる理由があります。そして分散型開発の方向性。テクノロジーが進歩し続け、市場が成熟し続けるにつれて、私たちはよりオープンで公平かつ効率的な AI 時代の到来を期待しています。












