
By: Tia, Techub News
Blockchain sacrifices efficiency due to its decentralized design, so improving execution speed has always been one of the urgent problems to be solved. The "execution layer" of blockchain is the key part that processes each transaction and adds it to the chain. In order to speed up processing power, improving the execution layer has become one of the core strategies, and parallel execution is an important breakthrough in this regard.
Traditional blockchains usually process transactions one by one in a serial manner, which greatly limits the transaction speed and causes congestion, especially in transaction-intensive networks. However, through parallel execution, multiple transactions can be processed at the same time, greatly improving execution efficiency and reducing pressure on the chain.
To better understand what parallelism is, we will start with execution and take Ethereum in PBS mode after Merge as an example to explain what execution is and show where execution occupies the entire transaction lifecycle.
Specific aspects of transaction execution
- Transactions enter the memory pool and are filtered and sorted: This is the preprocessing stage after the transaction is submitted, which includes the interaction of Mempool, Searcher and Builder to complete the filtering and sorting of transactions.
- Builder builds blocks (but does not execute): The Builder arranges profitable transactions into a block to complete the packaging and sorting of transactions.
- Proposer verifies and submits the block: After the block is built, the Builder will send the block proposal to the Proposer. The Proposer verifies the structure and transaction content of the block, and then formally submits the block to the network to start execution.
- Execute transactions: After the block is submitted, the node executes the transactions in the block one by one. This is a critical stage of state update. Each transaction will trigger a smart contract call, account balance change or state change.
- Witness witness: The validator witnesses the execution result and state root of the block and takes it as the final confirmation. This ensures the authenticity and validity of the block at the execution layer and prevents inconsistency.
- State synchronization: Each node will synchronize the execution results of the block (such as account balance, contract status update, etc.) to its own local state. After executing each transaction, the node calculates and stores a new state root to be used as the initial state in the next block.
Of course, this is only the state synchronization of transactions in blocks. In order to keep the latest on-chain status, nodes usually synchronize data block by block and continue to verify blocks and status. However, if you want to achieve finality under the POS mechanism, the aggregator needs to aggregate the witness signatures in each slot into a complete signature and pass it to the proposer of the next slot. And the validator needs to confirm the status of all blocks in the Epoch based on the number of votes after an Epoch, forming a temporary consensus status checkpoint. When two consecutive Epochs obtain the witness support of the majority of validators, the blocks and transactions will reach finality.
From the perspective of the entire life cycle of a transaction, execution occurs after the Proposer verifies the structure and transaction content of the block sent by the Builder. The actual execution process requires processing each transaction one by one and updating the corresponding account or contract status. After all transactions are executed, the Proposer will calculate a new state root (Merkle root), which is a summary of the execution results and final global state of all transactions in the current block. In layman's terms, the complete block execution process includes a series of calculations that need to be completed in the process of changing Ethereum from the previous state to the next state, from the execution of each transaction to the calculation of the Merkle root.
Sequential execution
The opposite of parallel execution is sequential execution, which is the more common execution method of blockchain at present. Usually, transactions are executed step by step in sequence. When a transaction is executed, Ethereum will update the account status and related information (such as balance, contract storage data) to the account status tree, and a new account status hash will be generated. After all account status trees are updated, the root node hash of the state tree called the state Merkle root will be formed. After the state Merkle root, transaction Merkle root and receipt Merkle root are completed, the block header will be hashed to generate the block hash of the block.
Among them, the execution order of transactions is crucial. Since the Merkle tree is a binary tree of hash values, the Merkle root values formed in different orders will be different.
Parallel execution
In a parallel execution environment, nodes will try to process transactions in a block in parallel. Instead of executing transactions one by one in sequence, transactions are assigned to different "execution paths" so that they can be executed simultaneously. Through parallel execution, the system can process transactions in a block more efficiently and improve throughput.
After all transactions are executed, the node will summarize the execution results (i.e. the status updates affected by the transactions) to form a new block state. This state will be added to the blockchain, representing the latest global state on the chain.
Status Conflict
Since parallelism processes transactions on different paths at the same time, a major difficulty with parallelism is state conflict. That is, there may be multiple transactions reading or writing the same part of data (state) on the blockchain in the same time period. If this situation is not handled properly, it will lead to uncertain execution results. Because the order of state update is different, the final calculation result will also be different. For example,
Suppose there are two transactions, transaction A and transaction B, both of which attempt to update the balance of the same account:
- Transaction A: Increase account balance by 10.
- Transaction B: Increase account balance by 20.
The initial account balance is 100.
If we execute serially, the results of the execution order are determined:
1. Execute transaction A first, then execute transaction B:
- The account balance first increases by 10 and becomes 110.
- Add another 20, and it ends up being 130.
2. Execute transaction B first, then execute transaction A:
- The account balance first increases by 20 and becomes 120.
- Add another 10, and it ends up being 130.
In both sequences, the final balance is 130 because the system ensures sequential consistency of transaction execution.
However, in a parallel execution environment, transaction A and transaction B may read the initial balance 100 at the same time and perform their own operations:
- Transaction A reads the balance as 100 and updates the balance to 110 after calculation.
- Transaction B also reads the balance as 100 and updates the balance to 120 after calculation.
In this case, since the transactions are executed at the same time, the final balance is only updated to 120 instead of 130, because the operations of transaction A and transaction B "overwrite" each other's results, resulting in a state conflict.
This type of state conflict problem is usually called "data overwrite", that is, when transactions try to modify the same data at the same time, they may overwrite each other's calculation results, resulting in an incorrect final state. Another problem that state conflicts may cause is that the execution order cannot be guaranteed. Because multiple transactions complete operations in different time periods, different execution orders will be caused. Different orders may lead to different calculation results, making the results uncertain.
To avoid this uncertainty, blockchain parallel execution systems usually introduce some conflict detection and rollback mechanisms, or perform dependency analysis on transactions in advance to ensure that they are executed in parallel without affecting the consistency of the final state.
Optimistic and Deterministic Parallelism
There are two ways to deal with the possible state conflict problem: deterministic parallelism and optimistic parallelism. These two modes have their own trade-offs in efficiency and design complexity.
Deterministic parallelism requires advance declaration of state access. The validator or sequencer will check the declared state access when sorting transactions. If multiple transactions attempt to write to the same state, these transactions will be marked as conflicting to avoid simultaneous execution. Different chains implement different forms of advance declaration of state access, but generally include the following methods:
- Through contract specification constraints: developers directly specify the scope of state access in the smart contract. For example, ERC-20 token transfers require access to the balance fields of the sender and receiver.
- Structured data declaration via transactions: Add dedicated fields to transactions to mark state access.
- Through compiler analysis: The compiler of a high-level language can statically analyze the contract code and automatically generate a state access set.
- Enforced declarations by the framework: Some frameworks require developers to explicitly specify the state they need to access when calling a function
Optimistic parallelism will optimistically process transactions first, and when conflicts occur, the affected transactions will be re-executed in order. In order to avoid conflicts as much as possible, the core of optimistic parallelism design is to quickly predict and assume the status through historical data, static analysis, etc. That is, the system assumes that certain operations or status updates are valid without complete verification, and tries to avoid waiting for all verification processes, so as to improve performance and throughput.
Although optimistic parallelism can avoid conflicts as much as possible through some quick predictions and assumptions about the status, there are still some unavoidable challenges, especially when it comes to contract execution or cross-chain transactions. If conflicts occur frequently, re-execution may significantly slow down system performance and increase computing resource consumption.
Deterministic parallelism avoids conflicts that may arise from optimistic parallelism by checking state dependencies before transactions. However, since state dependencies need to be accurately declared before transactions are submitted, this places higher demands on developers and increases the complexity of implementation.
EVM Parallel Dilemma
There are not only deterministic and optimistic ways to deal with state conflicts, but also the chain database architecture needs to be considered in the specific process of achieving parallelism. The state conflict problem in parallel is particularly difficult in the EVM under the Merkle tree architecture. The Merkle tree is a hierarchical hash structure. After each transaction modifies a certain state data, the root hash value of the Merkle tree also needs to be updated. This update process is recursive, from the leaf node to the root node. Since the hash is irreversible, that is, the upper layer can only be calculated after the data change of the lower layer is completed, this feature makes it difficult to update in parallel.
If two transactions are executed in parallel and access the same state (such as account balance), it will cause a conflict in the Merkle tree nodes. Resolving such conflicts usually requires additional transaction management mechanisms to ensure that consistent root hash values can be obtained in multiple branches. This is not easy to achieve for the EVM because it requires a trade-off between parallelization and state consistency.
Non-EVM parallel solution
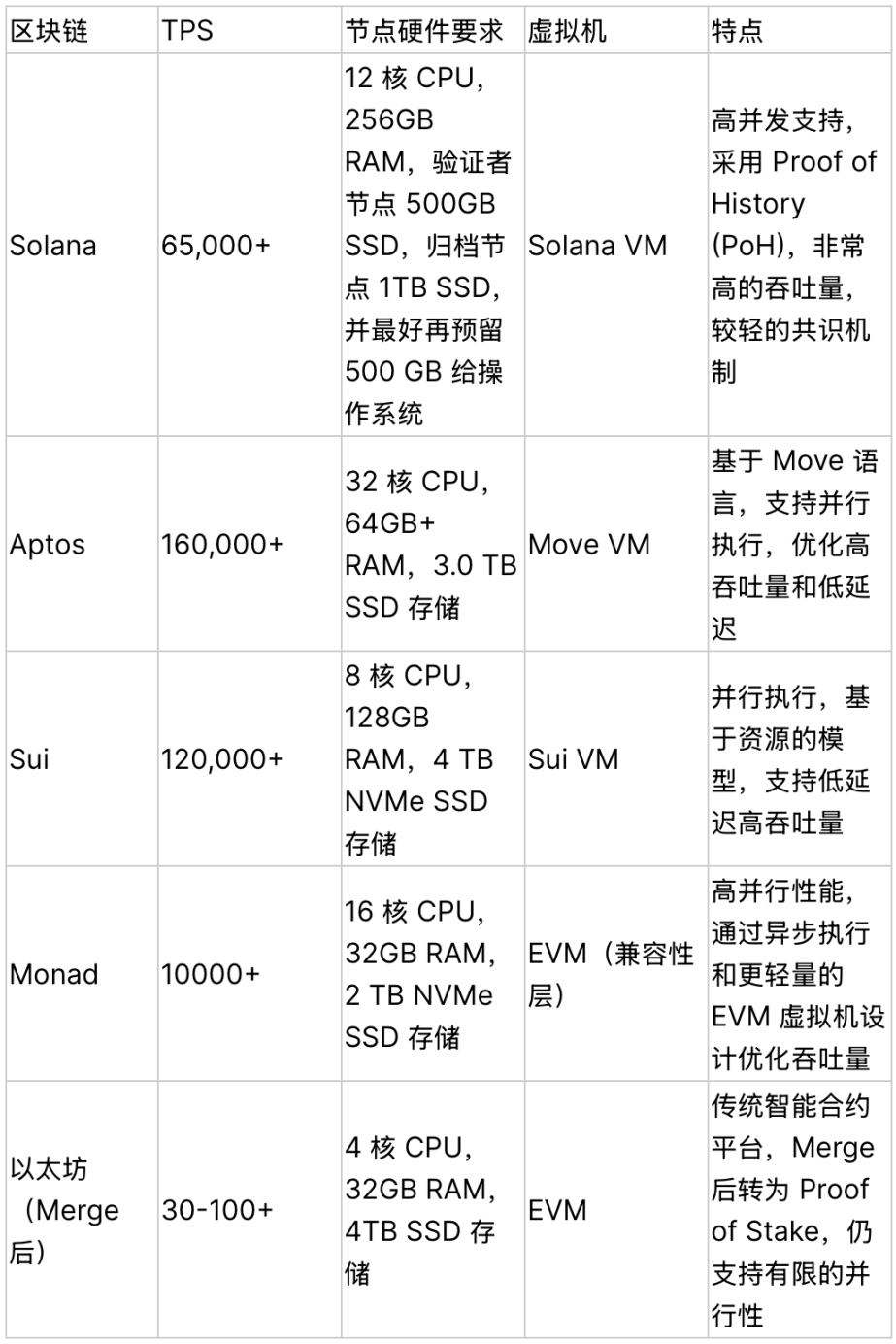
Solana
Different from Ethereum's global state tree, Solana adopts an account model. Each account is an independent storage space stored in the ledger, thus avoiding the path conflict problem.
Solana is deterministically parallel. In Solana, each transaction needs to explicitly declare the account to be accessed and the required access rights (read-only or read-write) when it is submitted. This design allows blockchain nodes to analyze the resources that each transaction needs to access in advance before the transaction is executed. Because all account dependencies are clear before the transaction begins execution, the node can determine which transactions will access the same account and which transactions can be safely executed in parallel, thereby achieving intelligent scheduling and avoiding conflicts, thus realizing the basis for parallel scheduling.
Since each transaction declares the accounts and permissions it needs to access before execution, Solana can check whether there are account dependencies between transactions (Sealevel model). If there are no shared read-write accounts between transactions, the system can distribute them to different processors for parallel execution.
Aptos
Aptos' parallel execution design is very different from Ethereum. It has made some key innovations in architecture and mechanism, mainly in account model and state storage.
Ethereum needs to frequently update the global state tree (MPT) when executing transactions. The status of all accounts and contracts is stored in a shared state tree, and any transaction needs to access and update part of this state tree. Aptos divides accounts into independent state units, and each object is an independent key-value pair. Objects can exist independently and do not affect each other. They are only associated when there is a clear reference relationship. There is no common tree path between objects, there will be no lock competition, and they can be completely parallel.
The underlying data structure of Aptos is Jellyfish Merkle Tree. The state of each object is ultimately stored in JMT as an independent key-value pair. Unlike Ethereum's MPT, Jellyfish Merkle Tree is in the form of a complete binary tree structure, which simplifies the storage path and query path of the node, greatly reducing the verification time. In addition, the position of each account in the tree is fixed, and the nodes in the tree are stored independently, allowing multiple accounts to be updated and searched in parallel.
Aptos is optimistically parallel, it does not require pre-declared dependencies of all accounts. To this end, Aptos uses Block-STM, which uses a preset transaction order to estimate dependencies, thereby reducing the number of aborts.
Parallel EVM
Compared with non-EVM parallelism, parallel EVM faces greater technical difficulties in dealing with state dependencies, conflict detection, gas management, and rollback mechanisms. To better understand this, we can refer to how some parallel EVM projects (such as Sui, Monad, Canto) solve these problems.
Sui
Sui, like Aptos, uses an object model to handle states, using each object (such as an account, smart contract state) as an independent resource, which is distinguished by an object unique identifier. When transactions involve different objects, these transactions can be processed in parallel because they operate on different states and will not cause direct conflicts.
Although Sui uses an object model to manage state, in order to be compatible with EVM, Sui's architecture bridges the object model and EVM's account model through an additional adaptation layer or abstraction mechanism.
In Sui, transactions are scheduled using an optimistic parallel strategy, assuming that there are no conflicts between transactions. If a conflict occurs, the system will use a rollback mechanism to restore the state.
Sui uses an object model and state isolation technology to effectively avoid state dependency problems. Each object is an independent resource, and different transactions can be executed in parallel, thereby improving throughput and efficiency. However, the trade-off of this approach is the complexity of the object model and the overhead of the rollback mechanism. If a conflict occurs between transactions, part of the state needs to be rolled back, which increases the burden on the system and may affect the efficiency of parallel processing. Compared with non-EVM parallel systems (such as Solana), Sui requires more computing and storage resources to maintain efficient parallelism.
Monad
Like Sui, Monad also uses optimistic parallelism. However, Monad's optimistic parallelism will still predict some transactions with dependencies before the specific transaction is executed. The prediction is mainly completed through Monad's static code analyzer. Prediction requires access to the state, and the way the state is stored in the Ethereum database makes it very difficult to access the state. In order to make the parallel state reading process more efficient, Monad also reconstructs the database.
The Monad state tree is divided into partitions, and each partition maintains its own state subtree. When updating, only the relevant shards need to be modified, without rebuilding the entire state tree. The state in the partition is quickly located through the state index table to reduce the interaction between partitions.
summary
The core of parallelism is to improve the efficiency of the execution layer by multi-path execution. In order to achieve multi-path execution, the chain needs to perform a series of mechanisms such as conflict detection and rollback to ensure that they are executed in parallel without affecting the consistency of the final state, and to make certain improvements to the database.
Of course, improving the efficiency of the execution layer is not limited to parallelism. The optimization of the execution link can also be achieved by reducing the read and write operations required by a transaction on the database. The scope of improving the speed of the entire chain is even wider, including the improvement of the efficiency of the consensus layer.
Each technology has its own specific limitations. Parallelism is only one way to improve efficiency. The final decision on whether to use the technology also needs to consider whether it is developer-friendly, whether it can be completed without sacrificing decentralization, etc. The more technology stacking, the better. At least, for Ethereum, parallelism is not that attractive. If we only consider efficiency, adding parallelism is not the best solution for Ethereum, whether from the perspective of simplicity or Ethereum's current Rollup-centric roadmap.









