
原文:《區塊鏈創造信任解決Web2囚徒困境,使Permissionless數據層成為可能,可徹底解決Web2數據孤島問題》
作者:Billy
筆者一直在尋找邊際上區塊鏈到底解決了什麼實際問題,也就是說,什麼具體的事情是區塊鏈出現之前不能做的,而出現之後能做的。這種邊際上可行性的改變不易察覺,卻可能產生巨大的商業機會。下文是筆者的答案之一。我相信,順著博弈論的思路,或許還能想到其他可用區塊鏈解決的實際應用場景,並想出新的商業模式,歡迎討論~
在本文筆者更多使用的是博弈論中的理性人模型解釋實然現象,並不再敘述關於“用戶應該擁有自己的數據”等Web3 native的應然敘事,因為應然敘事已經被討論的很充分,無需筆者再作分析。
摘要
- 區塊鏈的一大敘事就是模塊化:任何人都可以在現有的區塊鏈代碼積木上無需許可地增加新的功能,但事實上,世上無新事,傳統互聯網許多環節也是模塊化的,如操作系統。
- permissionless的操作系統幫所有軟件工程師解決了每個軟件都要重複造輪子,編寫與計算機硬件交互的代碼的問題,極大的提升了代碼編寫的效率,使在其上的生態茁壯成長。
- 與前操作系統時代類似,現互聯網數據割裂,每個應用都需重新蒐集數據,有嚴重的重複造輪子問題。 Web2巨頭開放數據,建立自身permissionless的生態,解決重複造輪子問題,理論上是對其本身和生態都有收益的事情,但卻因為類囚徒困境問題(博弈論經典問題)無法達到帕累托最優的結果。
- 具體來說,在區塊鏈誕生之前,沒有方法能同時防止數據使用者白嫖和數據提供者反悔這兩個問題,從而導致類囚徒困境。本質是,在此序貫博弈中,理性的後行動者總是會選擇“欺騙”而不是“合作”。
- 區塊鏈作為信任機器,解決了“不可置信承諾”問題,保證了後行動者的“合作”,使博弈雙方可以達到“(合作,合作)”局面,從而使用戶數據被開放,成為公用數據層,從而使互聯網軟件無需重複造輪子成為可能。
序言
區塊鏈的一大敘事就是模塊化:任何人都可以在現有的區塊鏈代碼積木上無需許可地增加新的功能,減少了大量重複造輪子的浪費,提升了效率。世上無新事,模塊化的本質就是在軟件領域的permissionless的產業鏈分工。一個典型的例子是,計算機行業發展早期,計算機的硬件和軟件由一家企業製作,後續才產生了permissionless的操作系統層,大大降低了軟件的編寫門檻,激發了軟件業的活力,誕生了互聯網這個萬億級別的市場。
然而,互聯網演化到了現在,各種各樣的模塊化工具使得代碼級別的重複造輪子問題已經小了很多。例如,模塊化的雲數據庫讓人無需重複設計、搭建、部署複雜的數據管理系統。然而,數據層面的重複造輪子問題卻很嚴重:每個互聯網軟件都需要重新獲得用戶數據,這使得用戶轉換成本巨大,從而使得軟件公司的獲客成本大大提高,這與當年操作系統還沒出現時一樣,大大抑制了互聯網軟件的創新。
明明開放的數據層生態大概率會遠遠好於封閉的數據層生態,為什麼掌握用戶數據的Web2巨頭不願意開放其數據,作為其他應用軟件的數據層呢?原因是,數據提供公司無法防止應用公司白嫖其數據,或者應用公司無法防止數據提供公司反悔收回其數據使用權。抽象來看,本質上是在動態博弈中,因為信任問題而導致在每個個體選擇了對自己最有利的決策下,整體利益無法達至最優的問題,類似我們常聽的囚徒困境問題。若用博弈論的術語來說,那就是精煉納什均衡並非帕累托最優解的問題。
區塊鏈作為信任機器,令原本“不可置信的承諾”變得可信,解決了此博弈問題,使得模塊化的permissionless數據層成為可能。這會大大降低互聯網軟件的創新門檻,為現在停滯的互聯網注入新的活力,為前所未有的創新提供土壤。同時,permissionless的數據層,也會創造像permissionless的操作系統層一樣巨大的價值,在其生態茁壯成長的同時,成為下一代互聯網的基石。
計算機產業分工發展史:permission操作系統模塊化
1960年代,大多數主機仍沒有交互式界面,整個計算機行業還處於非常原始的狀態。當時,硬件和軟件都由同一公司製作,不同公司的硬件與軟件都不兼容。若是在硬件上編寫軟件,代碼工程師需要用機器語言/彙編語言進行編寫,甚至連乘法函數都要自己寫一遍。
突破發生在1969年:面對美國司法部的反壟斷壓力和內部軟件開發成本的不斷增長,IBM改變了計算機行業原有的商業模式:它將停止發送免費軟件,未來將開始分別為硬件和軟件定價。緊接著,IBM推出了IBM/360計算機,將操作系統進行了標準化。在20世紀70年代,軟件公司第一次可以寫出能在全球80%大型機上使用的軟件。至此,計算機產業鏈的硬件和軟件就成功解耦了。任何軟件廠商都可以在OS/360操作系統上permissionless地編寫軟件並將之賣給用戶。
1981年,IBM要求比爾蓋茨幫其新計算機編寫操作系統,且答應比爾蓋茨可以將其操作系統脫離IBM的硬件單獨進行營銷,很快Windows操作系統就誕生了。從此以後,操作系統徹底從計算機產業鏈分離成為單獨的一層,緊接著permissionless的操作系統催化了這場轟轟烈烈的互聯網革命。

操作系統在整個產業鏈扮演者什麼樣的角色呢? permissionless的操作系統層幫軟件廠商們解決了與計算機硬件進行交互的問題,從而無需讓軟件工程師從零開始與硬件交互寫軟件,而只需要面對操作系統將硬件抽像後的接口編程即可,大大減少了軟件的開發成本。否則,每個軟件都需要寫一套與硬件交互的代碼,這將會大大提升軟件編寫的成本。同時,這種重複造輪子的行為將是極大的效率浪費。這和區塊鏈世界的“模塊化”其實是一回事:我們製作了模塊化的軟件,並permissionless地允許任何人在這些模塊化軟件之上搭建新的軟件,從而無需重複造輪子,大大減少成本。
互聯網數據層成為了抑制創新的新“輪子”
互聯網發展到了現在,軟件的編寫已經不是最大的成本與阻礙,被壟斷的用戶數據成為了互聯網軟件重複造的最大的輪子。對於社交軟件,每個軟件都需要重新建立用戶社交圖譜網絡;對於內容平台,每個平台都要重新累積用戶生產的內容;用戶雖然想去使用更有趣好用的新軟件,但想想自己的社交關係和過往沉澱內容都還存在原軟件之中,於是只能罷手。新軟件也因為用戶數據被壟斷,獲客成本太高,從而難以存活。用戶數據的被壟斷嚴重影響了互聯網軟件的創新,新軟件只能花大代價忙著拉新用戶累積數據,而不是專注於自己的軟件創新,就如同在沒有操作系統之前,需要使用機器語言編寫軟件的公司一樣。
另一方面,開放的數據層生態會遠遠好於封閉的數據層生態,就好像開放的操作系統生態(如Windows)顯然會遠遠好於所有應用軟件只由原公司編寫的操作系統生態,從而在競爭中勝出。假設騰訊開放了微信的用戶數據,那必然有無數創業者蜂擁而至,在其上構建新的軟件。若是如此,或許抖音、快手、拼多多等新一代的移動互聯網創新應用恐怕都會出現在騰訊的數據層上,而不是讓用戶重複造輪子,每個軟件各自為戰。如此,看上去壟斷了用戶數據的Web2巨頭將其數據開放出來似乎也有好處。
為什麼互聯網的數據層沒法像操作系統一樣分離出來,供所有軟件使用,減少重複造輪子問題?能否直接將數據開源?很可惜,答案是不能。使得數據層成為互聯網發展的一個開放的分工模塊需要做到兩點:
1)防止使用者白嫖:設計好的交易結構,防止搭便車問題,讓擁有數據的公司有激勵開放其數據;
2)防止提供者反悔:設計好的信任機制,減小數據提供商收回數據的權力,讓有雄心的創業者放心在此數據層上搭建創新應用,而不必擔心做大後權力被收回。
操作系統的permissionless模塊化則沒有以上兩種問題:
對於1),操作系統與硬件綁定銷售,可獲得大量利潤,因此它有激勵將產品開放給所有人使用,而不是只允許自己在上面編寫軟件;
對於2),操作系統是一串本地代碼,並不存在將已發出的操作系統遠程刪除的可能,因此軟件編寫者不必太擔心自己做大之後操作系統公司會禁止該軟件的使用,而變為自己做以謀取暴利。 (不過,操作系統公司有其他方式進行“不正當競爭”,如微軟的IE成為了Windows的預裝瀏覽器,從而在競爭中勝過了當時正紅的網景瀏覽器)
互聯網數據層則不然,因此理論上更有效率的開放式數據層並沒有在傳統互聯網出現:
對於1),如果互聯網數據巨頭直接將用戶數據開源,則使用者可以直接白嫖這些沒有排他性數據,導致互聯網數據公司(如騰訊)沒有激勵開放數據。
對於2),如果互聯網數據巨頭使用API(計算接口)向其他公司提供數據,原公司將一直有能力關閉這些API。這導致真正有創意有雄心的創業者不會在可被收回的數據層上進行建設,以防止其做大之後被數據層公司要挾。事實上,在過去,無論是微博還是推特,其API管的都比較鬆,也正因此大量圍繞著微博和推特的第三方軟件出現——它們有著更好更創新的UX,並且很好地服務了某些不被原軟件照顧到的垂類用戶。但是,在這些第三方軟件做大之後,微博和推特因為被這些較為同質化的第三方軟件影響了市佔率,微博和推特都大幅降低了其API的開放性,以摧毀這些長在自己生態上的競爭對手,重新贏回市佔率。
Web2巨頭壟斷數據不願開放是囚徒困境
前文已經敘述了傳統互聯網數據層誕生的兩個最大阻力:無法防止使用者白嫖和無法防止提供者反悔。抽象來看,本質上是在動態博弈中,因為信任問題而導致在每個個體選擇了對自己最有利的決策下,整體利益無法達至最優的問題,類似我們常聽的囚徒困境問題。若用博弈論的術語來說,那就是精煉納什均衡並非帕累托最優解的問題。我們先用博弈樹來解釋無法防止使用者白嫖而導致無法達至最優解的問題。
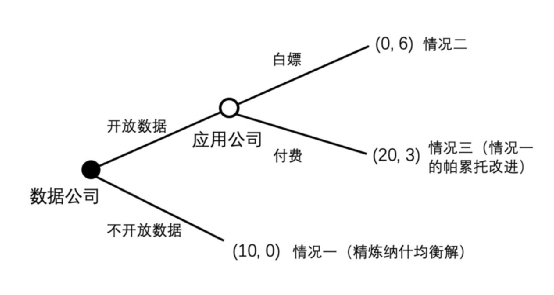
在此次動態博弈中,數據公司(也就是如騰訊等擁有數據的Web2巨頭)有開放數據和不開放數據的選擇。若其開放數據,應用公司可以選擇白嫖或者不白嫖。在博弈樹的葉子結點,括號內第一個數表示數據公司的效用,第二個數表示應用公司的效用。
這顆博弈樹描述瞭如下情況:
情況一:如果數據公司選擇不開放數據,也就是現在的Web2巨頭壟斷數據的情況,數據公司效用為10,而應用公司無法使用現有數據,只能重複造輪子,因此效用為0。
情況二:如果數據公司選擇開放數據作為互聯網應用的數據層,而應用公司選擇白嫖,因為數據公司從此沒有了壁壘且無法盈利,數據公司效用為0;而應用公司因為免費獲得了大量數據,無需重複造輪子,因此效用為6。
情況三:如果數據公司選擇開放數據作為互聯網應用的數據層,而應用公司選擇付費,那麼因為之後會有大量創新公司長在該數據層上,其生態會變得非常壯大,且其可以藉助其生態獲得更強的盈利能力(就像微軟和以太坊一樣),因此數據公司效用為20;而應用公司,雖然付出了一些金錢,但是獲得了用戶數據,無需重複造輪子,大大減小了獲客成本,因此效用為3。
我們可以很容易發現,情況三(20,3)是情況一(10,0)的帕累托改進。也就是說,無論是對於數據公司還是應用公司,情況三都要好於情況一的(20>10,3>0),為什麼情況沒有往這個方向演變呢?原因是,精煉納什均衡解就是情況一。直觀來看,假設數據公司和應用公司都是理性的情況下,情況三是不可能達成的:如果數據公司先選擇了開放數據,讓所有應用公司都可以使用數據的話,應用公司一定會選擇白嫖而不是付費,因為這樣對於應用公司效用最高(6>3),從而使博弈樹走到情況二。數據公司不是傻子,他很清楚一旦他直接開放數據,如果沒有手段使數據變成排他性資產的話,應用公司不會付費(二階理性),會導致情況二。因此,對於數據公司來說,不如一開始就不開放數據,從而進入比情況二更好的情況一。因此一開始數據公司就不會開放數據。
如果應用公司聲稱他會付費,讓數據公司開放數據,實現合作共贏,這樣可以達至集體最優的情況三嗎?答案是很難,因為應用公司聲稱他會付費是一個“不可置信承諾”,有很大的事後反悔的動機,很難令人相信,而用法律的協調成本則太高。
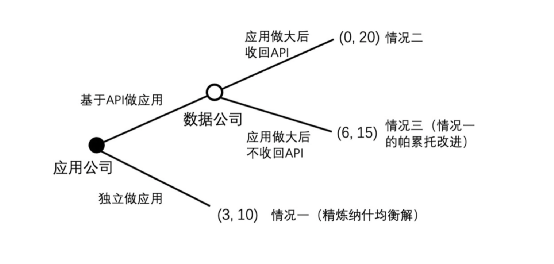
無法防止數據提供者反悔問題也同樣可以用博弈樹進行分析,是類似的問題,最後的結果則是無法達到(6,15)的帕累托最優解,而是只能被困在(3 ,10)的囚徒困境中。讀者可根據下圖自行推演。
區塊鏈有潛力解決博弈問題,使數據層模塊化成為可能
Web2巨頭不願開放其數據並非不知道成為一個開放生態的好處,而是因為以上博弈問題,從而導致沒法走向使每個人都獲益的情況三。就像囚徒困境一樣,每個人都會選擇“坦白”,而無法走向每個人都不坦白從而免去牢獄之災的(3,3)。
上文提出的一個可能的解決方案是,博弈樹中的後選擇者可以聲稱合作(如聲稱付費),誘使先選擇者也進行合作(如開放數據)。但問題在於,在傳統場景中,聲稱會合作是“不可置信承諾”,因為在先選擇者合作之後,後選擇者反悔才是利益最大化的選項。這裡的重點在於人的“不可置信”。而區塊鏈正好是解決信任問題的,寫入了區塊鏈的代碼將無法被更改,無法反悔,因此區塊鏈正是解決此類問題的關鍵!
對於無法防止使用者白嫖的問題,數據公司可以把數據放進區塊鏈中,並且編寫合適的代碼使得需要付出token才能調用相應數據(也許需要一定隱私加密技術),甚至就直接學以太坊,讓使用者需要付出token才能儲存數據。這樣一來,應用公司就可以permissionless地付費調用/儲存數據(這裡可以設置成只有用戶使用私鑰才能調用自己數據,以做到用戶擁有自己的數據,然後應用公司幫用戶付費),而數據公司也可以不必擔心應用公司直接複製數據而不付錢了。
對於無法防止提供者反悔的問題,數據公司可以把數據放進區塊鏈中,並且編寫合適的只要付錢才可以調用數據的代碼就可以解決。因為區塊鍊是不可篡改而且permissionless的,應用公司無需擔心數據公司有一天會將權限收回,因為數據公司無法收回。
注意,這裡的收費可以按多種模式,如按次收費,按DAU/MAU收費,按license收費等。每次收費也可以很低以減小應用公司負擔,如每天每個DAU 0.1美分。
如此一來,博弈樹將會走到情況三,數據公司和應用公司都將大量獲利。
至此,建立數據層將會成為互聯網的一種新的商業模式,無數創新應用將會建立在此數據層之上。對於數據公司來說,無數應用公司給數據層公司付費的同時還會不斷豐富數據層的數據,壯大其生態,成為互聯網下一個操作系統級別的機會。對於應用公司來說,它們的獲客成本大大降低(因為用戶的轉換成本降低),無需重複造輪子,可以專注在產品創新之上,大大增加互聯網應用層的活力。邊際來看,這種互聯網數據層以前無法發生,而現在有機會出現的原因就是區塊鏈解決了信任問題,從而使上述博弈問題得到解決,從而使人們能真的達到囚徒困境中的(3 ,3)。
如有與本文觀點相同/相異的非常歡迎聯繫筆者本人討論交流!













