
近日,加密數據查詢網站Dune宣布更新其LLM( 大型語言模型,Large language model)路線圖,首期上線GPT-4支持的查詢解釋(Query Explanations)功能,後期將會逐漸增加更多功能,比如自然語言查詢(Natural Language Querying)、SQL語句轉義(Query Translations)和優化搜索等。
不同於其他數據分析網站付費查詢商業化路線,Dune在上線後始終對普通用戶免費開放,因此在上輪的牛市週期沉澱了足夠多的用戶量,而LLM的加入,則有望使其沉澱的數據查詢語句、看板轉化為實際的殺手鐧,並且引導普通用戶加入創作者行列。
Dune的數據查詢鴻溝
得益於區塊鏈數據的公開性和透明度,任何人都可直接訪問區塊鏈數據,但是原始數據(Raw Data)往往難以辨認,非專業程序員很難看懂其含義,但是其上的數據蘊藏著巨大的經濟價值,因此各類數據分析工具便應運而生,為各類分析師、研究員和普通散戶提供間接訪問和深度分析的工具。

Dune在其中最為引人注目,因為其提供了真正自由且強大的分析工具,任何人都可通過SQL語句進行對數據的查詢、分享和展示,甚至部分項目直接選擇Dune作為官方信息展示平台。
但是Dune的SQL查詢功能,表面看是UGC模式,平等的賦予每一個用戶權限去執行查詢任務,但實際上Dune採納的SQL模式存在兩個問題,其一是門檻過高,SQL是(結構化查詢語言,Structured Query Language)的簡寫,比如查詢Uniswap上以DAI作為交易對的數量,僅僅需要5行代碼即可完成。但是一旦執行查詢的邏輯變得複雜,其代碼量可能會大幅增加,非專業程序員很難自行寫出,這導致大量用戶只能成為看客。

例如,官方進行簡化後的"nft.trades "查詢流程,包含了近20萬行的SQL語句轉換、10萬行的測試代碼,並且由55個社區成員參與其中,單個用戶無法處理如此大規模的任務。

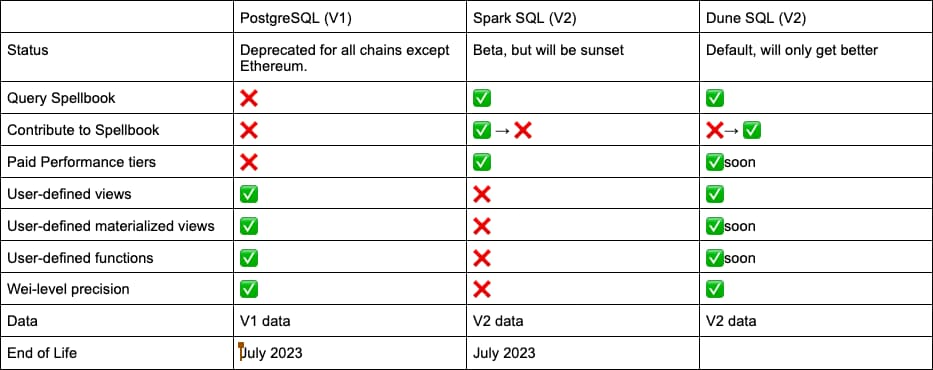
其二是Dune的V1和V2版本的之間支持的SQL標準並不統一,V1和V2分別使用的Po stgreSQL和Spark SQL,後續計劃由Dune SQL完成統一。
在本次升級LLM功能之前,Dune已經在準備統一查詢引擎,計劃在今年7月份之後全部遷移至Dune SQL,以保證產品邏輯的統一性。更新後的Dune SQL是基於開源查詢引擎Trino的實現,Dune對其進行優化,以適配Dune自身的需求,與流行的Spark SQL並無本質上的差異,更多是在具體函數和語法上的改進。比如Dune SQL提供了更多的運算符,方便快速對日期和時間進行計算,以及對管理權限進行限制,所有涉及對原始數據本身的刪除、更新等操作均無法執行,以保證數據的安全性。
但是SQL查詢門檻過高的問題,依舊無法通過更改SQL範式得到解決,這意味著大多數用戶和程序員都要去適應新的語法格式,比如說針對具體的查詢語句,新用戶和程序員都要去適應。而對自動化工具的需求,不僅對於普通用戶具備現實意義,對不熟悉新語法的程序員也大有裨益。
實際上,在遷移Dune SQL路線圖中,Dune已經在嘗試實驗自動化工具,可以將不同的語法格式統一轉化為Dune SQL語句,而在GPT-4 使用LLM顯示人機交互方面的威力後,Dune也順勢推出自己的LLM計劃。
LLM:解鎖普通用戶的參與感
Dune的典型流程是解構鏈上數據,專業用戶通過SQL執行查詢,隨後將看板(Dashboard)分享給有需要的用戶。在這個流程中,最關鍵的是執行查詢,而大多數用戶因為缺乏代碼知識而無法使用查詢功能。
而在引入查詢解釋功能後,上述流程發生一些微調,在專業用戶寫的SQL查詢界面,會出現解釋頁面,以自然語言的格式直觀地告訴查看用戶代碼的具體作用,相當於給SQL查詢添加一個解釋說明的補丁,並不會改變當前的工作流程,這也是團隊在吸取合併SQL語句時的教訓,即降低對用戶既有習慣的干擾,而是盡可能在現有流程優化體驗。
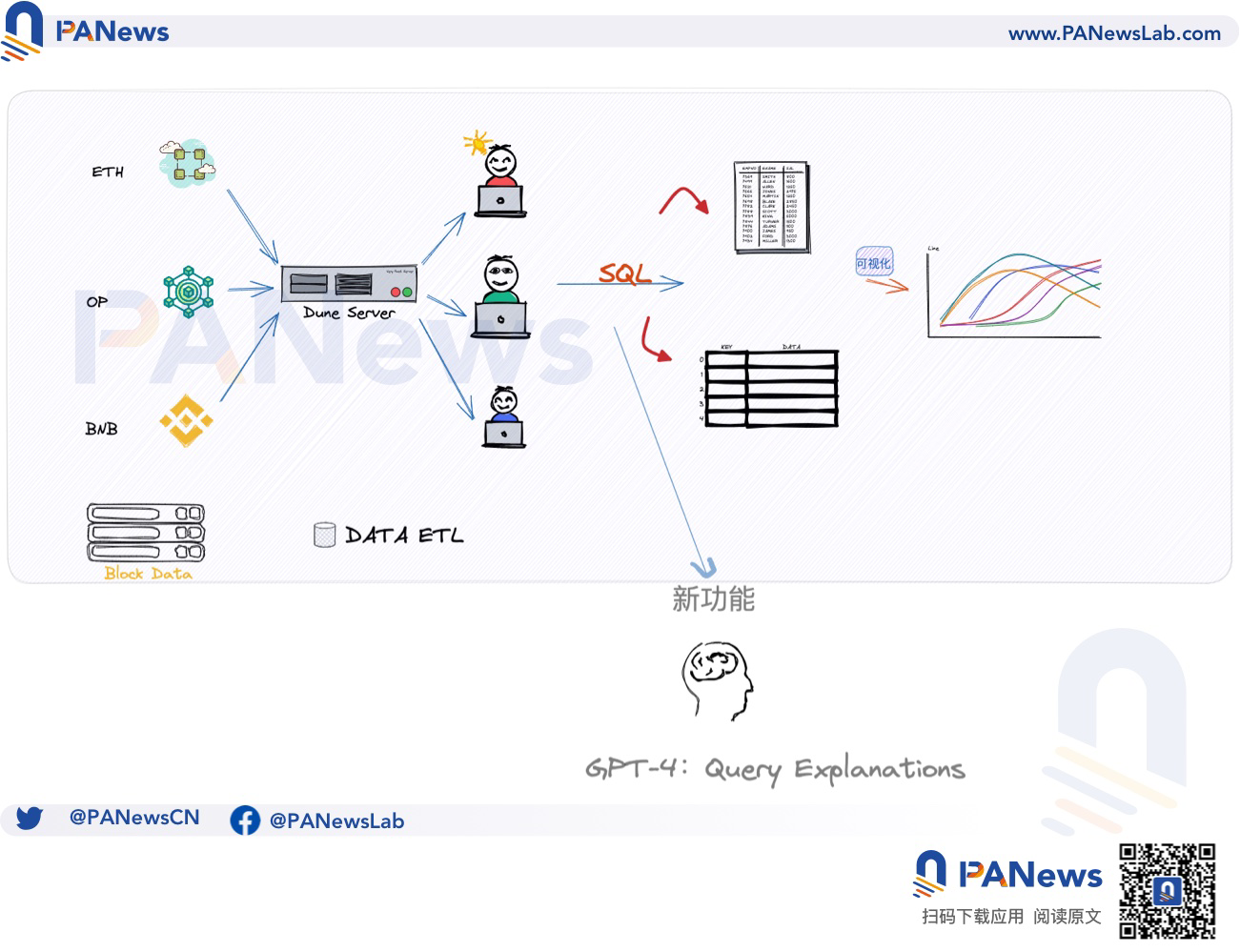
在LLM加入後,一定程度上抹去了專業用戶和普通用戶的能力差異。借助GPT-4對代碼的理解能力,可以讓普通用戶直觀的理解查詢語句的作用,而無需掌握SQL知識。在此功能引入前,用戶只能被動的在看板頁面閱讀圖表,而在引入查詢解釋功能後,普通用戶也可以理解SQL代碼是發揮作用的具體含義。
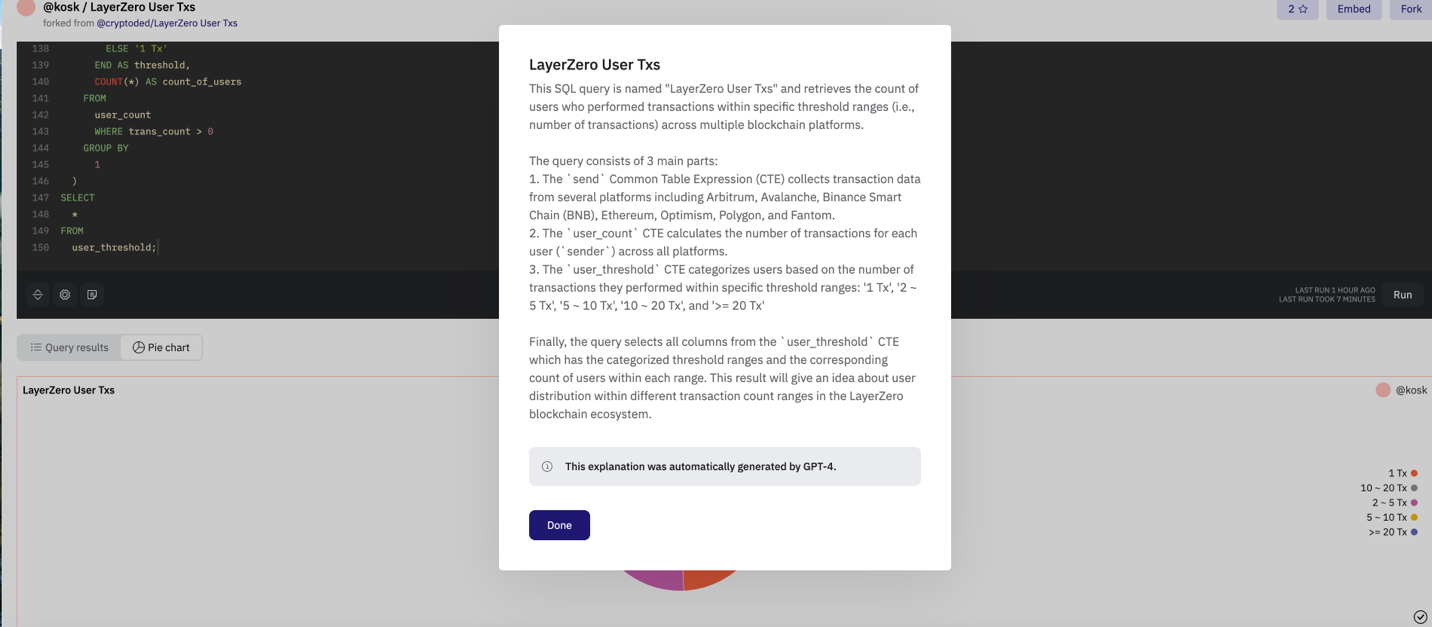
比如說Alice想要查詢LayerZero交易的相關信息,那麼她可以直接找到Bob已經製作好的Dune看板,可以發現49.4%的用戶都集中在1次,那麼Alice有理由推斷說明這是為了潛在的經濟刺激而進行的虛假交易,但是無法一錘定音,因此Alice決定去翻閱代碼檢查結論是否可靠。

但是Alice發現雖然結果只有5行數據,但是查詢代碼足足有150行,Alice的SQL水平不足以確認每個語句的正確性,而此時查詢解釋功能則會“翻譯”代碼的具體說明,如圖所示,查詢分成了3個部分:收集數據涵蓋了Arbitrum、Avalanche、BNB、Ethereum、Optimism、Polygon和Fantom等多條鏈,並且第二部分是計算每個用戶(`sender`)的交易數量。第三部是針對數量設置閾值對用戶進行分類:1 Tx', '2 ~ 5 Tx', '5 ~ 10 Tx', '10 ~ 20 Tx', 和'>= 20 Tx' 。
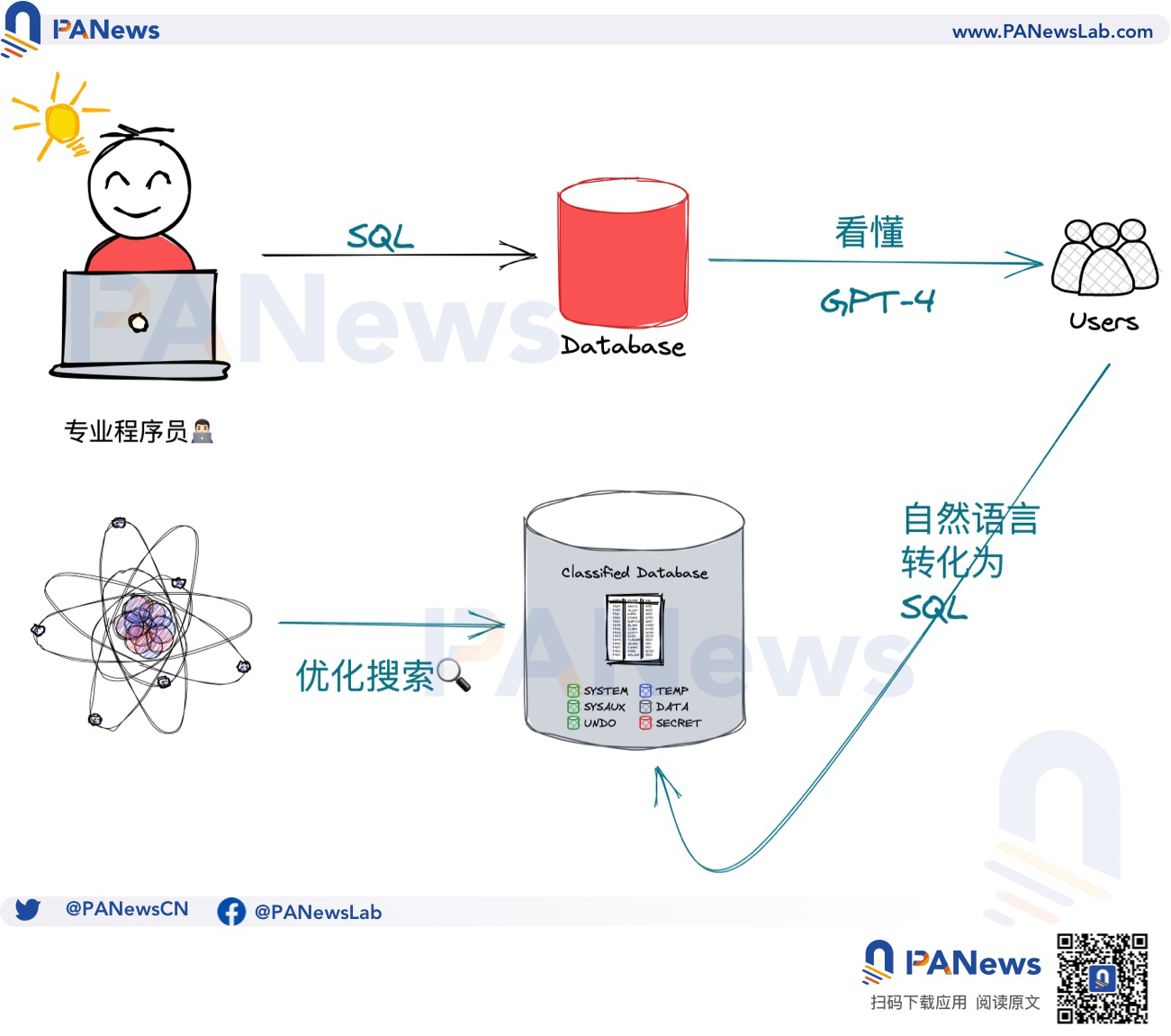
那麼此時Alice可以在不理解Bob寫的代碼含義基礎上去進行分析和判斷。本質上,查詢解釋的功能相當於給代碼和人類之間進行了一次轉義和翻譯,那麼反過來,也可以將人類語言翻譯成SQL語句,在LLM加持下,得益於Dune攢下的海量查詢語句數據,這並不難實現。
自然語言查詢(Natural Language Querying)就是Dune後續LLM改進的重要方向。自然語言查詢可以讓用戶以傳達指令的方式去執行圖表生成任務,這比使用SQL語句、拖曳生成等模式更為符合普通人的思維方式,免去對實現細節的關注。
並且,自然語言查詢並不是對專業用戶,如分析師群體的替代功能,而是一種補強,現存的Dune有將近70萬個圖表,相當一部分的分析任務是重疊和衝突的,而使用自然語言查詢,也有助於系統去理解圖表之間的關聯,從而進一步提升整個分析工作的效率。
在LLM加入後,現存圖表、SpellBook和文檔數據也將被重新整合,效仿OpenAI的聊天機器人,Dune也會開發對話機器人,幫助用戶以更簡易的方式去理解和利用現存的知識體系,而不需要受到不相關信息的干擾。
比如,Alice可以將上述查詢LayerZero用戶交易量分佈的情況逆置,先用英語發出查詢指令,並且交代好每一步的工作流程,隨後Dune會幫助Alice寫好150行代碼,隨後生成圖表。
結語:人人都能當數據分析師
Dune的目標並不是建立一個單純的鏈上數據分析平台,而是希望打造一個可以使信息自由流動的數據管道,允許用戶抓取、轉換、管理、查詢、可視化以及利用數據去採取行動。
數據流動的前提是必須進行模塊化,可任意組合和配置,最終建造社區共享的數據集,而不是集中在復雜的SQL語句或者付費API之內,最終達到人人都可和數據進行交互的平權圖景。
概要而言,Dune的LLM計劃是“翻譯”和助手,目標是讓普通用戶讀懂數據所代表的一切,不僅是最終結果的展示,而是深入到生成過程之中,最終人人都可進行鏈上數據分析。











