
著者: リチュアル
翻訳: 各国のブロックチェーン

近年、エージェントの概念は、哲学、ゲーム、人工知能などの多くの分野でますます重要になってきています。伝統的に、主体性とは、自律的に行動し、選択を行い、意図性を持つ、つまり人間に一般的に関連付けられる性質を持つ存在を指します。
人工知能の分野では、主体性の意味合いはより複雑になります。環境内で独立して観察、学習、行動できる自律エージェントの出現により、これまでの抽象的なエージェント概念にコンピューティング システムという具体的な形が与えられました。これらのエージェントは人間の介入をほとんど必要とせず、意思決定を行い、経験から学習し、ますます複雑な方法で他のエージェントや人間と対話する、意識はありませんが計算的に意図的な能力を示します。
この記事では、自律エージェントの新興分野、特に大規模言語モデル (LLM) に基づくエージェントと、ゲーム、ガバナンス、科学、ロボット工学などのさまざまな分野におけるその影響について説明します。この記事では、エージェンシーの基本原理の探求に基づいて、人工知能エージェントのアーキテクチャとアプリケーションを分析します。この分類学的観点は、これらのエージェントがどのようにタスクを実行し、情報を処理し、特定の運用フレームワーク内で進化するかについての洞察を提供します。
この記事の目標には、次の 2 つの側面が含まれます。
記憶、知覚、推論、計画などのコンポーネントに焦点を当てて、人工知能エージェントとそのアーキテクチャ基盤の体系的な概要を提供します。
人工知能エージェント研究の最新トレンドを探り、何が可能かを再定義する際の人工知能エージェントの使用例に焦点を当てます。
注:記事が長くなったため、この記事を編集する際に原文は削除されています。
1. 代理店の調査動向
大規模言語モデル (LLM) に基づくエージェントの開発は、記号推論、反応システム、強化学習、適応学習における複数の進歩をカバーする人工知能研究の大きな進歩を示しています。
記号エージェント: ルールと構造化された知識を通じて人間の推論をシミュレートし、特定の問題 (医療診断など) には適していますが、複雑で不確実な環境に対処するのは困難です。
リアクティブ エージェント: 「感知-アクション」サイクルを通じて環境に迅速に応答します。これは、高速なインタラクション シナリオに適していますが、複雑なタスクを完了することはできません。
強化学習エージェント: 試行錯誤学習によって動作を最適化するもので、ゲームやロボットなどに広く使われていますが、学習時間が長く、サンプル効率が低く、安定性が低いです。
LLM ベースのエージェント: LLM エージェントは、記号推論、フィードバック、適応学習を組み合わせ、少数ショットおよびゼロショット学習機能を備え、ソフトウェア開発、科学研究、その他の分野で広く使用されており、動的な環境に適しており、他のエージェントと連携できます。エージェント。
2. エージェンシーのアーキテクチャ
最新のエージェント アーキテクチャは、包括的なシステムを形成する複数のモジュールで構成されています。
1) アーカイブモジュール
プロファイル モジュールはエージェントの動作を決定し、役割またはパーソナリティを割り当てることで一貫性を確保します。これは、安定したパーソナリティが必要なシナリオに適しています。 LLM エージェントのプロファイルは、人口統計上のペルソナ、仮想ペルソナ、およびパーソナライズされたペルソナの 3 つのカテゴリに分類されます。

論文「ペルソナからパーソナライゼーションへ」より抜粋
役割によるパフォーマンスの向上 役割の設定により、エージェントのパフォーマンスと推論能力が大幅に向上します。たとえば、LLM が専門家として行動する場合、LLM の応答はより詳細で状況に応じたものになります。マルチエージェント システムでは、役割のマッチングによりコラボレーションが促進され、タスクの完了率と対話の質が向上します。
プロファイルの作成方法 LLM エージェント プロファイルは次の方法で作成できます。
手動デザイン: キャラクターの特性を手動で設定します。
LLM 生成: LLM を介してキャラクター設定を自動的に拡張します。
データセットの調整: 実際のデータセットに基づいて構築され、インタラクションの信頼性が向上します。
2) メモリモジュール
メモリは LLM エージェントの中核であり、適応的な計画と意思決定をサポートします。記憶構造は人間のプロセスをシミュレートし、主に 2 つのカテゴリに分類されます。
統合記憶: 短期記憶、最近の情報を処理します。テキスト インターセプト、メモリ サマリー、修正されたアテンション メカニズムを通じて最適化されていますが、コンテキスト ウィンドウによって制限されます。
ハイブリッドメモリ: 短期記憶と長期記憶を組み合わせ、長期記憶は外部データベースに保存され、効率的に思い出すことができます。
メモリ形式 一般的なメモリ保存形式には次のものがあります。
自然言語: 柔軟性があり、意味的に豊富です。
ベクトルを埋め込む: 高速に検索します。
データベース: 構造化ストレージによるクエリをサポートします。
構造化リスト: リストまたは階層形式で編成されています。
メモリ操作エージェントは、次の操作を通じてメモリと対話します。
メモリ アクセス: 関連情報を取得して、情報に基づいた意思決定をサポートします。
メモリ書き込み: 重複やオーバーフローを避けるために新しい情報を保存します。
記憶の反映:経験を要約し、抽象的な推論能力を高めます。

論文「Generative Agents」の内容に基づく
研究の意義と課題
記憶システムはエージェントの能力を向上させますが、研究上の課題も引き起こします。
スケーラビリティと効率: メモリ システムは大量の情報をサポートし、高速な検索を保証する必要があります。長期的なメモリ検索を最適化する方法は依然として研究の焦点です。
コンテキスト制限された処理: 現在の LLM はコンテキスト ウィンドウによって制限されており、メモリ処理機能を拡張するための動的アテンション メカニズムとサマリー テクノロジを研究しています。
長期記憶のバイアスとドリフト: 記憶にはバイアスがあり、情報の優先処理とメモリのドリフトにつながる可能性があり、エージェントのバランスを維持するには、バイアスを定期的に更新して修正する必要があります。
壊滅的な忘却: 新しいデータが古いデータを上書きするため、重要な情報が失われます。経験の再生と記憶の統合テクノロジーによって、重要な記憶を強化する必要があります。
3) 知覚能力
LLM エージェントは、人間が感覚入力に依存するのと同じように、多様なデータ ソースを処理することで環境の理解と意思決定能力を向上させます。マルチモーダル知覚は、テキスト、視覚、聴覚などの入力を統合し、複雑なタスクを実行するエージェントの能力を強化します。主な入力タイプとその用途は次のとおりです。
テキスト入力 テキストは、LLM エージェントの主な通信方法です。エージェントは高級言語能力を備えていますが、指示の背後にある暗黙の意味を理解することは依然として課題です。
暗黙の理解: 強化学習を通じて好みを調整し、あいまいな指示や推測された意図に対処します。
ゼロサンプルおよび少数サンプルの機能: 追加のトレーニングなしで新しいタスクに対応でき、多様な対話シナリオに適しています。
視覚入力 視覚認識により、エージェントはオブジェクトと空間の関係を理解できます。
画像からテキストへ: テキストの説明を生成すると、視覚的なデータの処理に役立ちますが、詳細が失われる可能性があります。
Transformer ベースのエンコーディング: Vision Transformers は、画像をテキスト互換のトークンに変換します。
ブリッジング ツール: BLIP-2 や Flamingo などは、中間層を使用してビジュアルとテキストのドッキングを最適化します。
聴覚入力 聴覚により、エージェントは音や音声を認識できるようになります。これは、インタラクティブなシナリオや一か八かのシナリオでは特に重要です。
音声認識と合成: Whisper (音声からテキストへ) や FastSpeech (テキストから音声へ) など。
スペクトログラム処理: オーディオ スペクトログラムを画像に処理して、聴覚信号分析機能を向上させます。
マルチモーダル知覚の研究課題と考慮事項:
データの調整と統合 研究では、マルチモーダル トランスフォーマーとクロスアテンション レイヤーの最適化に重点を置いています。
スケーラビリティと効率 マルチモーダル処理は、特に高解像度の画像やオーディオを処理する場合に大きな需要があります。低リソース消費でスケーラブルなモデルの開発が重要です。
壊滅的な忘却 マルチモーダルエージェントは壊滅的な忘却に直面しており、重要な情報を効果的に保持するために優先再生や継続学習などの戦略が必要です。
コンテキストに応じた応答の生成 コンテキストに応じて優先順位を付けた感覚データの処理に基づいて応答を生成することは、特に騒がしい環境や視覚的に支配された環境において依然として研究の焦点となっています。
4) 推論と計画
推論および計画モジュールは、複雑なタスクを分解することでエージェントが問題を効率的に解決するのに役立ちます。人間と同様に、構造化された計画を立てることができ、事前に完全な計画を構築し、フィードバックに基づいてリアルタイムで戦略を調整できます。計画方法はフィードバックの種類によって分類されます。
一部のエージェントは、実行前に完全な計画を作成し、計画を変更せずに単一のパスまたは複数のオプションを実行します。
他のエージェントは、動的な環境でのフィードバックに基づいて戦略をリアルタイムで調整します。
フィードバックなしの計画 フィードバックがない場合、エージェントは最初から完全な計画を作成し、調整なしで実行します。シングルパス計画 (段階的に実行) とマルチパス計画 (複数のオプションを同時に検討し、最適なパスを選択) が含まれます。
単一パス推論タスクは連続したステップに分割され、各ステップが次のステップに続きます。
思考連鎖 (CoT): 少数の例を通じて、エージェントは段階的に問題を解決し、モデル出力の品質を向上させることができます。
ゼロショットCoT: 事前に設定された例は必要なく、「ステップバイステップの思考」を促すことで推論が実行されるため、ゼロショット学習に適しています。
再プロンプト: 手動入力なしで有効な CoT プロンプトを自動的に検出します。
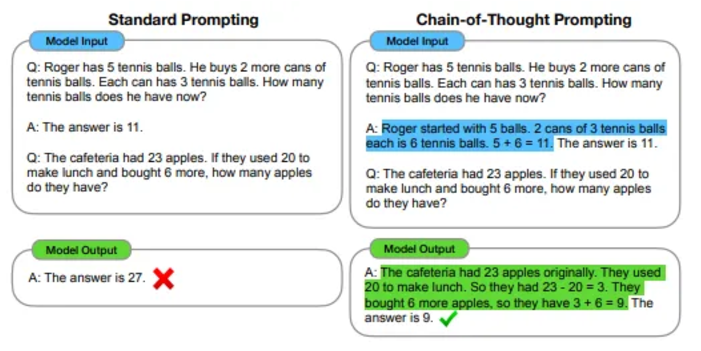
CoT論文より
5) マルチパス推論
シングルパス推論とは異なり、マルチパス推論では、エージェントが複数のステップを同時に探索し、複数の潜在的な解決策を生成および評価し、それらから最適なパスを選択することができます。特に複数の複雑な問題がある場合に適しています。可能なパス。
例:
自己矛盾のない連鎖思考 (CoT-SC): CoT プロンプト出力から複数の推論パスをサンプルし、最も頻繁に使用されるステップを選択し、「自己統合」を達成します。
思考のツリー (ToT): 論理ステップをツリー構造として保存し、ソリューションに対する各「思考」の貢献を評価し、幅優先または深さ優先の検索ナビゲーションを使用します。
Graph of Mind (GoT): ToT をグラフ構造に拡張し、思考を頂点、依存関係をエッジとして、より柔軟な推論を可能にします。
計画による推論 (RAP): モンテカルロ ツリー検索 (MCTS) を使用して複数の計画をシミュレートし、言語モデルは推論ツリーの構築とフィードバックの両方を行います。
6) 外部プランナー
LLM がドメイン固有の計画の課題に直面した場合、外部のプランナーがサポートを提供し、LLM に欠けている専門知識を統合します。
LLM+P: タスクをプランニング ドメイン定義言語 (PDDL) に変換し、外部プランナーを通じてタスクを解決して、LLM が複雑なタスクを完了できるようにします。
CO-LLM:モデル連携によりテキストが生成され、モデルを交互に選択してタグを生成することで、最適な連携モデルが自然と浮かび上がってきます。
フィードバックを使用した計画 フィードバックを使用した計画により、エージェントは環境の変化に応じてリアルタイムでタスクを調整し、予測不可能または複雑なシナリオに適応できます。
環境フィードバック エージェントが環境と対話するとき、リアルタイムのフィードバックに基づいて計画を調整し、タスクの進行状況を維持します。
ReAct: 推論とアクション プロンプトを組み合わせて、対話中に適応可能な計画を作成します。
DEPS: タスク計画の計画を見直し、未完了のサブ目標に対処します。
SayPlan: シーン グラフと状態遷移の改良戦略を使用して、状況認識を向上させます。

「ReAct」論文より
7) 手動フィードバック
人間と対話することで、エージェントが人間の価値観と一致し、間違いを回避できるようになります。例:
内部独白: 人間のフィードバックをエージェントの計画に統合し、アクションが人間の期待と一致していることを確認します。
モデルのフィードバック 事前トレーニングされたモデルからのフィードバックは、エージェントの自己チェックと推論とアクションの最適化に役立ちます。例:
SelfCheck: 推論チェーン内のエラーを自己識別し、正しさを評価するゼロショット段階的チェッカー。
反省: エージェントはフィードバック信号を記録することで反省し、長期的な学習とエラー修正を促進します。
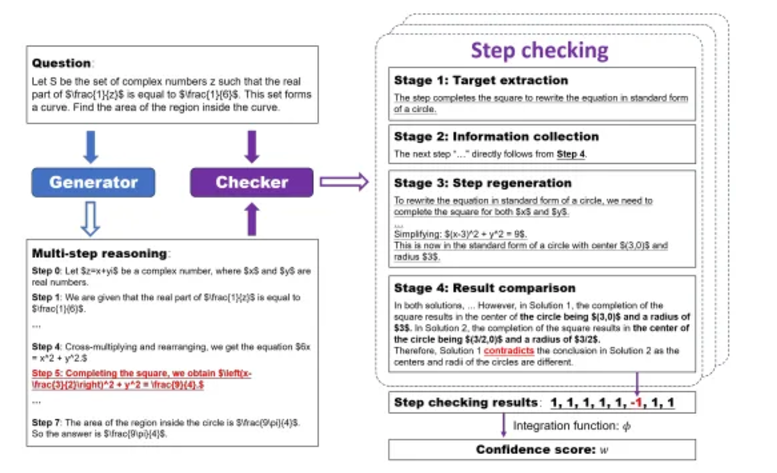
「セルフチェック」ペーパーより
推論と計画における課題と研究の方向性 推論と計画モジュールはエージェントの機能を向上させていますが、依然として次のような課題に直面しています。
スケーラビリティとコンピューティング要件: ToT や RAP などの複雑な手法には大量のコンピューティング リソースが必要であり、効率の向上は依然として研究の焦点です。
フィードバック統合の複雑さ: 複数のソースからのフィードバックを効果的に統合し、情報の過負荷を回避することが、パフォーマンスを犠牲にすることなく適応性を向上させる鍵となります。
意思決定におけるバイアス: 特定のフィードバック ソースや経路を優先するとバイアスが生じる可能性があり、バランスの取れた計画を立てるにはバイアス除去テクニックを組み込むことが重要です。
8) アクション
アクション モジュールはエージェントの意思決定プロセスの最終段階であり、次のものが含まれます。
アクション目標: エージェントは、タスクの完了、コミュニケーション、環境探索などのさまざまな目標を実行します。
行動生成: 記憶や計画に基づく行動など、想起や計画を通じて行動を生成すること。
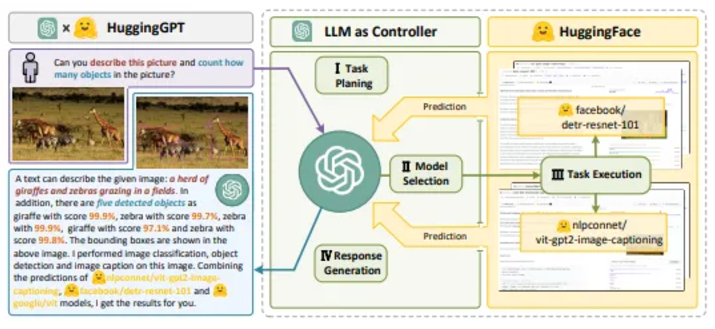
アクション スペース: 固有の知識と、タスクを実行するための API、データベース、外部モデルなどの外部ツールが含まれます。たとえば、HuggingGPT や ToolFormer などのツールは、タスクの実行に外部モデルまたは API を利用します。
データベースとナレッジベース: ChatDB は SQL クエリを使用してドメイン固有の情報を取得しますが、MRKL は複雑な推論のためにエキスパート システムと計画ツールを統合します。
外部モデル: エージェントは、特殊なタスクを実行するために非 API モデルに依存する場合があります。たとえば、ChemCrow は創薬に複数のモデルを使用し、MemoryBank はテキスト検索を強化するために 2 つのモデルを使用します。
アクションの影響: アクションは次のように分類できます。
環境の変化: Voyager や GITM でのリソースの収集や構造物の構築など、環境の変化。
自己影響力: 記憶の更新や新しい計画の作成などの生成エージェント。
ミッションチェーン: 特定のアクションは、リソースを収集した後にボイジャーが構造物を構築するなど、他のアクションをトリガーします。
アクション領域の拡大: AI エージェントの設計には、強力なアーキテクチャとタスクのスキルが必要です。アビリティを取得するには、微調整する場合と微調整しない場合の 2 つの方法があります。
取得機能の微調整:
手動で注釈が付けられたデータ セット: RET-LLM や EduChat など。手動で注釈を付けることで LLM のパフォーマンスが向上します。
LLM は、ToolBench などのデータ セットを生成し、LLM 生成命令を通じて LLaMA を微調整します。
実世界のデータ セット: MIND2WEB や SQL-PaLM など、実際のアプリケーション データを通じてエージェントの機能を向上させます。
微調整なしの能力獲得 微調整が不可能な場合、エージェントは迅速なエンジニアリングと機構エンジニアリングを通じて能力を向上させることができます。
プロンプト エンジニアリングは、設計プロンプトを通じて LLM の動作をガイドし、パフォーマンスを向上させます。
思考連鎖 (CoT): 中間推論ステップを追加して、複雑な問題解決をサポートします。
SocialAGI: ユーザーの精神状態に基づいて会話を調整します。
Retroformer: 過去の失敗からの反省に基づいて意思決定を最適化します。
メカニズム エンジニアリングは、特殊なルールとメカニズムを通じてエージェントの機能を強化します。
DEPS: 実行プロセス、フィードバック、目標の選択を記述することでエラー修正を改善する最適化計画。
RoCo: 環境検査に基づいてマルチロボットのコラボレーション計画を適応させます。
議論のメカニズム: コラボレーションを通じて合意に達する。
経験の蓄積
GITM: 学習および汎化能力を向上させるテキストベースの記憶メカニズム。
Voyager: 自己フィードバックを通じてスキルの実行を最適化します。
自発的な進化
LMA3: 目標の再スケーリングと報酬機能をサポートし、エージェントが特定のタスクのない環境でスキルを学習できるようにします。
「ボイジャー」紙より
微調整によりタスク固有のパフォーマンスを大幅に向上させることができますが、オープンソース モデルが必要であり、大量のリソースを消費します。プロンプト エンジニアリングとメカニズム エンジニアリングは、オープン ソース モデルとクローズド ソース モデルに適用できますが、入力コンテキスト ウィンドウによって制限され、慎重な設計が必要です。
3. 複数のエージェントを含むシステムアーキテクチャ

マルチエージェント アーキテクチャでは、タスクを複数のエージェントに割り当て、それぞれが異なる側面に焦点を当て、堅牢性と適応性を向上させます。エージェント間のコラボレーションとフィードバックにより、全体的な実行効果が向上し、エージェントの数はニーズに応じて動的に調整できます。ただし、このアーキテクチャは調整の課題に直面しており、情報の損失や誤解を避けるためにはコミュニケーションが不可欠です。
エージェント間のコミュニケーションと調整を促進するために、研究では 2 つの組織構造に焦点を当てています。
水平構造: すべてのエージェントが意思決定を共有および最適化し、集団的な意思決定を通じて個々の意思決定を集約します。これは、コンサルティングまたはツールの使用シナリオに適しています。
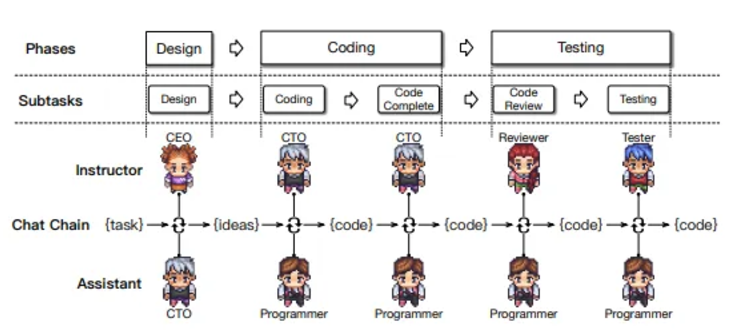
垂直構造: 1 人のエージェントが暫定的な解決策を提案し、他のエージェントがフィードバックを提供するか、マネージャーによって監督されます。数学的問題解決やソフトウェア開発など、洗練された解決策が必要なタスクに適しています。
「ChatDev」論文より
1) ハイブリッド組織構造
DyLAN は、垂直構造と水平構造をハイブリッド アプローチに組み合わせ、エージェントが同じレイヤー内で水平に連携し、タイム ステップを超えて情報を交換します。 DyLAN は、ランキング モデルとエージェント重要度スコアリング システムを導入し、最も関連性の高いエージェントを動的に評価して選択し、コラボレーションを継続します。これにより、パフォーマンスの低いエージェントは非アクティブ化され、階層構造が形成されます。高ランクのエージェントは、ミッションとチーム構成において重要な役割を果たします。
協力的なマルチエージェントのフレームワークは、効率を最大化するための補完的な協力を実現するために情報を共有し、アクションを調整することにより、各エージェントの利点に焦点を当てています。

「エージェントバース」論文より
協力的な相互作用には 2 つのタイプがあります。
無秩序な協力: ブレーンストーミングと同様に、複数のエージェントが固定された順序やプロセスに従わずに自由に対話します。各エージェントはフィードバックを提供し、システムは入力を統合して応答を整理し、調整エージェントを通じて混乱を回避します。多くの場合、合意に達するために多数決メカニズムが使用されます。
秩序ある協力: エージェントは構造化されたプロセスに従って順番に対話し、各エージェントは効率的なコミュニケーションを確保するために前のエージェントの出力に注意を払います。タスクは迅速に完了し、混乱は回避されますが、相互検証や人間の介入によるエラーの拡大を防ぐ必要があります。
MetaGPT論文より
敵対的マルチエージェント フレームワーク 協力的フレームワークは効率とコラボレーションを促進し、敵対的フレームワークは課題を通じてエージェントの進化を推進します。ゲーム理論にインスピレーションを得た敵対的インタラクションにより、エージェントはフィードバックと反省を通じて行動を改善することができます。たとえば、AlphaGo Zero はセルフプレイを通じて戦略を向上させ、LLM システムは議論や報復の交換を通じて出力の品質を向上させます。このアプローチはエージェントの適応性を促進しますが、計算オーバーヘッドとエラーのリスクももたらします。
緊急動作 マルチエージェント システムでは、次の 3 つの緊急動作が発生する可能性があります。
ボランティア行動: エージェントは積極的にリソースを提供したり、他の人を助けたりします。
一貫した動作: エージェントはチームの目標に合わせて動作を調整します。
破壊的な行動: エージェントは目標を迅速に達成するために極端な行動を取る場合があり、これはセキュリティ上のリスクをもたらす可能性があります。
ベンチマーク テストと評価 ベンチマーク テストは、エージェントのパフォーマンスを評価するための重要なツールです。一般的に使用されるプラットフォームには、ALFWorld、IGLU、Minecraft などがあり、エージェントの計画、コラボレーション、タスク実行の能力をテストするために使用されます。同時に、ツールの使用と社会的能力の評価も非常に重要です。ToolBench や SocKET などのプラットフォームは、それぞれエージェントの適応性と社会的理解を評価します。
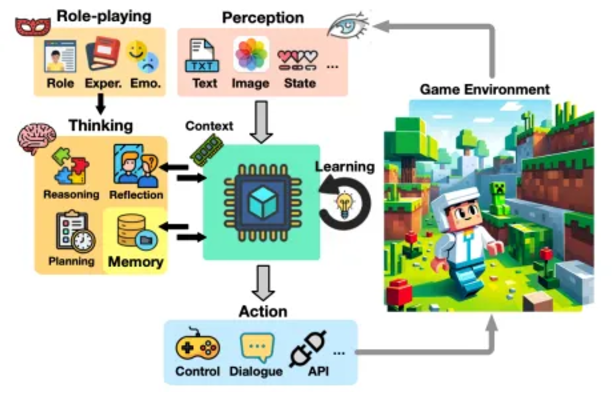
応用デジタル ゲームは、認知能力に焦点を当て、AGI 研究を促進する LLM に基づく AI 研究の重要なプラットフォームとなっています。
論文「大規模言語モデルに基づくゲームエージェントの調査」より
ゲームにおけるエージェントの認識 ビデオ ゲームでは、エージェントは認識モジュールを通じてゲームの状態を理解します。次の 3 つの主な方法があります。
状態変数アクセス: ゲーム API を介してシンボリック データにアクセスします。ビジュアル要件が低いゲームに適しています。
外部ビジュアル エンコーダ: ビジュアル エンコーダを使用して画像をテキスト (CLIP など) に変換し、エージェントが環境を理解できるようにします。
マルチモーダル言語モデル: ビジュアル データとテキスト データを組み合わせて、GPT-4V などのエージェントの適応性を強化します。
ゲームエージェントの導入事例
Cradle (アドベンチャー ゲーム): このゲームでは、エージェントがストーリーを理解し、パズルを解き、ナビゲートする必要があり、マルチモーダル サポート、動的な記憶、意思決定の課題に直面します。 Cradle の目標は、汎用コンピュータ制御 (GCC) を実現し、エージェントが画面と音声入力を通じてあらゆるコンピュータ タスクをより高い汎用性で実行できるようにすることです。
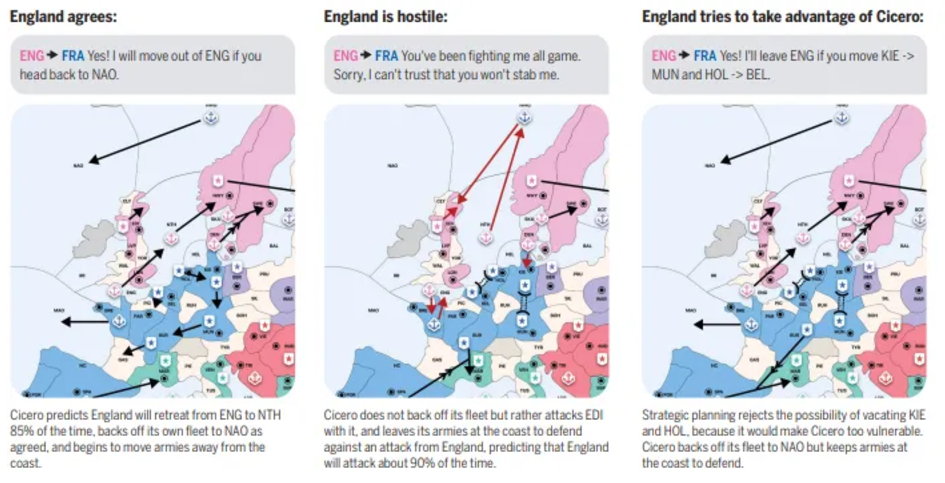
ポケ LL モン (対戦ゲーム) の対戦ゲームは、その厳格なルールと人間のプレイヤーに匹敵する勝率により、推論と計画のパフォーマンスのベンチマークとなっています。いくつかのエージェント フレームワークは、競争力のあるパフォーマンスを実証しています。たとえば、「大規模言語モデルが「StarCraft 2」をプレイする: ベンチマークと連鎖要約手法」の LLM エージェントは、「StarCraft 2」のテキスト バージョンの組み込み AI と競合します。 PokéLLMon は、人間レベルのパフォーマンスを達成した最初の LLM エージェントであり、ポケモン タクティクス ゲームでランキング勝率 49%、招待勝率 56% を達成しました。このフレームワークは、知識の生成と一貫した行動の生成を強化することで、連鎖思考における幻覚やパニックサイクルを回避します。エージェントは戦闘サーバーのステータス ログをテキストに変換し、ターンの一貫性を確保し、記憶に基づいた推論をサポートします。
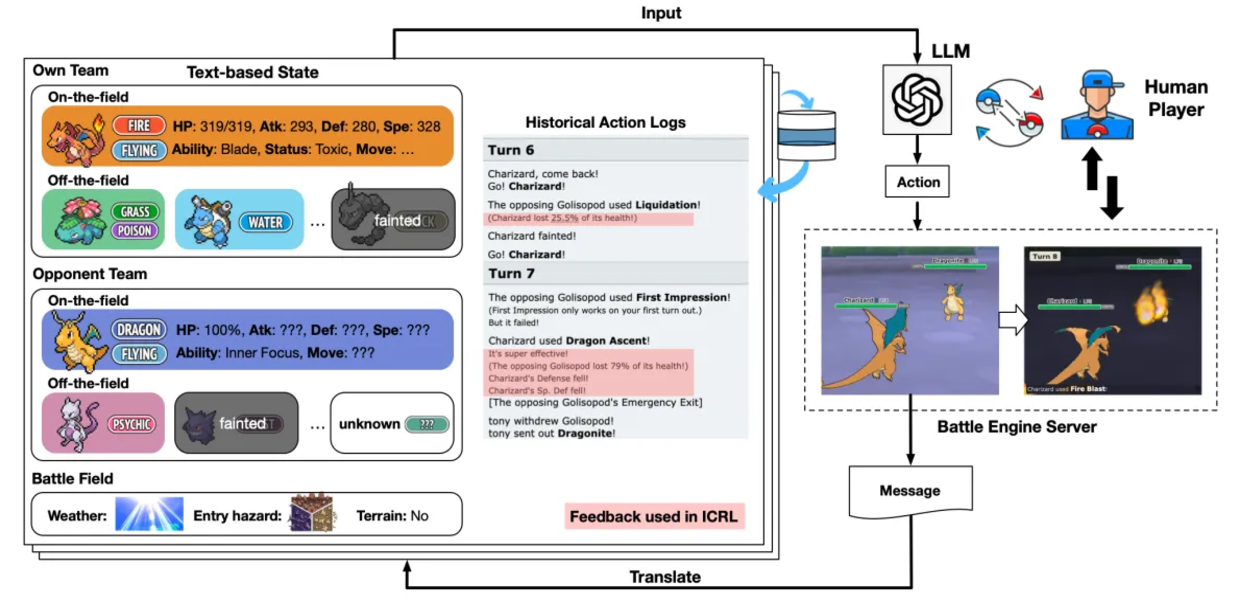
エージェントは、HP変化、スキル効果、アクションシーケンスの速度推定、スキルステータス効果を含む4種類のフィードバックを通じて学習を強化し、戦略を最適化し、無効なスキルのリサイクルを回避します。
PokéLLMon は、外部リソース (Bulbapedia など) を使用してタイプ制限やスキル効果などの知識を取得し、エージェントが特別なスキルをより正確に使用できるようにします。さらに、CoT、Self-Consistency、ToT 手法を評価したところ、Self-Consistency により勝率が大幅に向上することがわかりました。
ProAgent (協力ゲーム) 協力ゲームでは、チームメイトの意図を理解し、行動を予測し、明示的または暗黙的な協力を通じてタスクを完了する必要があります。明示的な協力は非常に効率的ですが柔軟性に欠けますが、暗黙的な協力は適応的な相互作用のためのチームメイトの戦略の予測に依存します。 「Overcooked」では、ProAgent は暗黙的に連携する機能を示しており、その中心的なプロセスは次の 5 つのステップに分かれています。
知識の収集と状態遷移: タスク関連の知識を抽出し、言語記述を生成します。
スキルプランニング: チームメイトの意図を推測し、行動計画を策定します。
信念の修正: チームメイトの行動に対する理解を動的に更新して、エラーを減らします。
スキルの検証と実行: 計画を繰り返し調整して、アクションが効果的であることを確認します。
メモリストレージ: インタラクションと結果を記録して、将来の意思決定を最適化します。
中でも、信念修正メカニズムは、エージェントが対話中に理解を更新し、状況認識と意思決定の正確性を向上させるために特に重要です。
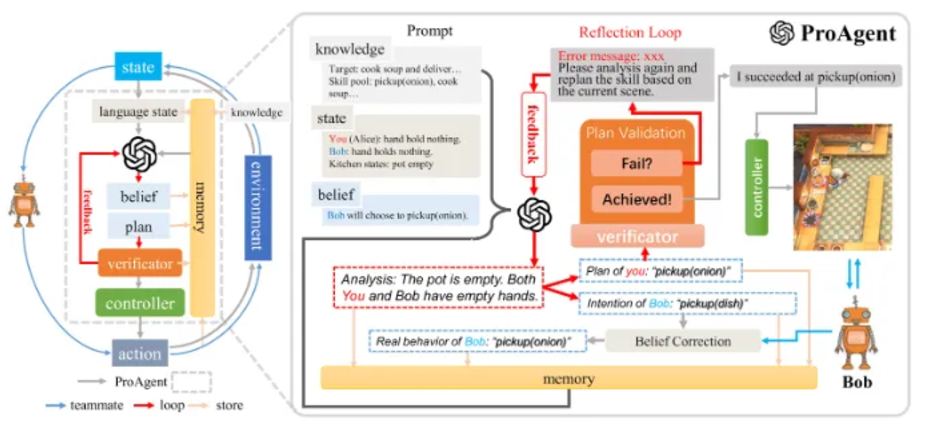
ProAgent は、5 つのセルフプレイおよび群衆ベースのトレーニング方法を超えています。
2) 生成エージェント(シミュレーション)
仮想キャラクターは人間の行動の深さと複雑さをどのように体現するのでしょうか? SHRDLU や ELIZA などの初期の AI システムは自然言語対話を試み、ルールベースの手法と強化学習もゲームで進歩しましたが、一貫性とオープンな対話には限界がありました。現在、LLM と多層アーキテクチャを組み合わせたエージェントは、これらの制限を打破し、記憶を保存し、イベントを反映し、変化に適応する機能を備えています。研究によると、これらのエージェントは実際の人間の行動をシミュレートできるだけでなく、情報を広め、社会的関係を確立し、行動を調整する創発的な能力を実証して、仮想キャラクターをより現実的にすることができます。
「大規模言語モデル エージェントの台頭と可能性: 調査」より
アーキテクチャの概要: このアーキテクチャは、知覚、記憶の検索、反映、計画、反応を組み合わせたものです。エージェントは、記憶モジュールを通じて自然言語の観察を処理し、適時性、重要性、文脈上の関連性に基づいて情報を評価および取得すると同時に、過去の記憶に基づいて関係性や計画についての深い洞察を提供するリフレクションを生成します。推論モジュールと計画モジュールは、計画と実行のサイクルに似ています。
シミュレーション結果: この研究では、バレンタインデーパーティーと市長選挙の情報拡散をシミュレーションしました。2 日以内に、市長候補者の認知度は 4% から 32% に、政党の認知度は 4% から 52% に増加し、虚偽の情報の割合が増加しました。わずか1.3%でした。エージェントは自発的な調整を通じてパーティーを組織し、密度が 0.167 から 0.74 に増加して新しいソーシャル ネットワークを形成します。このシミュレーションは、外部介入なしで情報共有と社会調整メカニズムを実証し、将来の社会科学実験の参考となります。
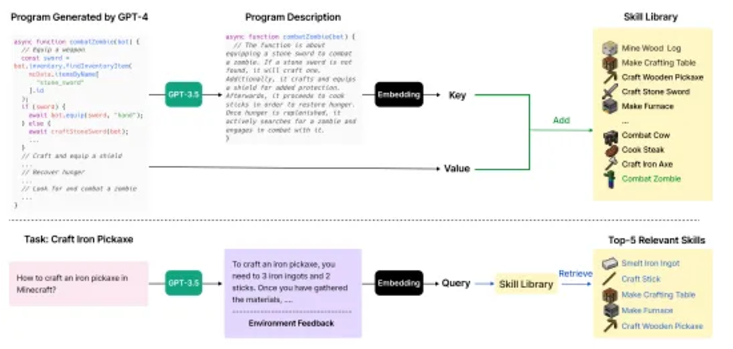
Voyager (クラフトと探索): Minecraft では、エージェントはクラフト タスクを実行したり、独立して探索したりできます。生産タスクは LLM 計画とタスク分解に依存しますが、独立した探索によりコース学習を通じてタスクが特定され、LLM が目標を生成します。 Voyager は、自動化されたコース、スキル ライブラリ、フィードバック メカニズムを組み合わせて探索と学習の可能性を実証する、具体化された生涯学習エージェントです。
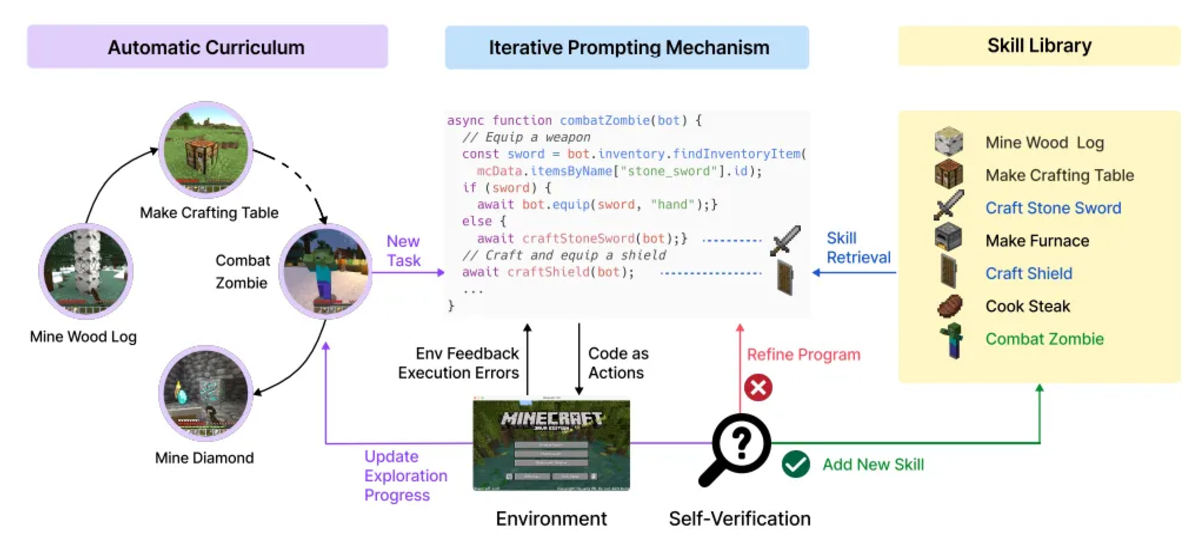
自動コースは LLM を利用してエージェントの状態と探索の進行状況に関連する目標を生成し、タスクを徐々に複雑にしていきます。エージェントはタスクを実行するためのモジュール式コードを生成し、連鎖思考プロンプトを通じてフィードバック結果を提供し、必要に応じてコードが変更されます。成功すると、コードは後で使用できるようにスキル ライブラリに保存されます。
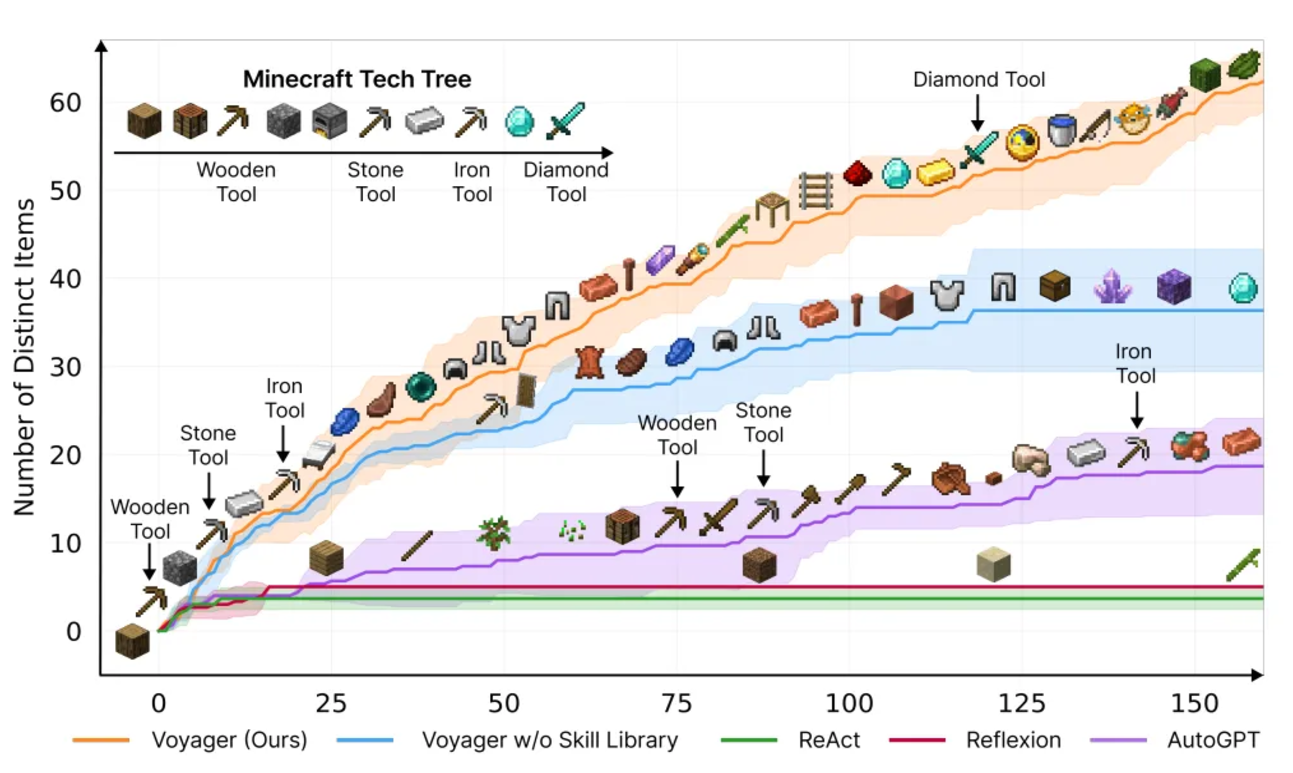
Voyager フレームワークは、テクノロジー ツリーのロック解除効率を大幅に向上させ、木材、石、鉄のロック解除速度がそれぞれ 15.3 倍、8.5 倍、6.4 倍速くなり、ダイヤモンドのロックを解除する唯一のフレームワークになります。探査距離はベースラインの2.3倍、発見数は3.3倍となり、優れた生涯学習能力を発揮します。
4. ゲーム分野での応用可能性 1) エージェント主導のゲームプレイ
マルチエージェント シミュレーション: AI キャラクターが自律的に行動し、ダイナミックなゲームプレイを促進します。
戦略ゲーム インテリジェント ユニット: エージェントは環境に適応し、プレイヤーの目標に基づいて自律的な意思決定を行います。
AI トレーニング グラウンド: プレイヤーはタスクを完了するために AI を設計およびトレーニングします。
2) AIで強化されたNPCと仮想世界
オープンワールド NPC: LLM は、NPC を駆動して経済的および社会的力学に影響を与えます。
リアルな対話: NPC の対話エクスペリエンスを向上させます。
仮想エコロジー: AI がエコシステムの進化を推進します。
動的イベント: ゲーム内のアクティビティをリアルタイムで管理します。
3) ダイナミックなナラティブとプレイヤーのサポート
適応型ストーリーテリング: エージェントは、パーソナライズされたタスクとストーリーを生成します。
プレーヤー アシスタント: ヒントとインタラクティブなサポートを提供します。
感情的に反応する AI: プレイヤーの感情に基づいて対話します。
4) 教育と創造
AI の対戦相手: 競技やシミュレーションでプレーヤーの戦略に適応します。
教育ゲーム: エージェントが個別の指導を提供します。
作成支援: ゲーム コンテンツを生成し、開発の敷居を下げます。
5) 仮想通貨・金融分野
エージェントは自律的にウォレットを操作し、ブロックチェーンを通じて取引し、DeFiプロトコルと対話します。
スマート コントラクト ウォレット: マルチ署名とアカウントの抽象化をサポートし、エージェントの自律性を強化します。
秘密キー管理: Coinbase が開発した AI エージェント ツールなど、マルチパーティ コンピューテーション (MPC) または信頼できる実行環境 (TEE) を使用してセキュリティを確保します。
これらのテクノロジーは、エージェントの自律的なオンチェーン インタラクションと暗号化エコロジカル アプリケーションに新たな機会をもたらします。
5. ブロックチェーン分野における代理申請
1) 確認エージェントの推論
オフチェーン検証はブロックチェーン研究の注目のトピックであり、主に複雑度の高い計算で使用されます。研究の方向性には、ゼロ知識証明、楽観的検証、信頼できる実行環境 (TEE)、暗号経済ゲーム理論が含まれます。
エージェントの出力検証: オンチェーンバリデーターを通じてエージェントの推論結果を確認し、分散型オラクルと同様に、エージェントを外部で実行し、信頼できる推論結果をチェーンにアップロードできるようにします。
事例: Modulus Labs の「Leela vs. the World」では、ゼロ知識回路を使用してチェスの手を検証し、予測市場と検証可能な AI 出力を組み合わせています。
2) 暗号エージェントの連携
分散ノード システムは、マルチエージェント システムを実行して合意に達することができます。
儀式のケース: 複数のノードで LLM を実行し、オンチェーン検証と投票を組み合わせてプロキシ アクションの決定を形成します。
Naptha Protocol: エージェント タスクのコラボレーションと検証のためのタスク マーケットとワークフロー検証システムを提供します。
分散型 AI オラクル: 分散エージェントの操作とコンセンサスの確立をサポートする Ora プロトコルなど。
3) イライザフレームワーク
a16z によって開発された、ブロックチェーン専用に設計されたオープンソースのマルチエージェント フレームワークで、パーソナライズされたインテリジェント エージェントの作成と管理をサポートします。
特徴: モジュール式アーキテクチャ、長期記憶、プラットフォーム統合 (Discord、X、Telegram などをサポート)。
トラスト エンジン: 自動化されたトークン トランザクションと組み合わせて、推奨の信頼スコアを評価および管理します。
4) その他のプロキシ アプリケーション
分散型能力の獲得: スキル ライブラリの作成やプロトコル ナビゲーションなどの報酬メカニズムを通じたインセンティブ ツールとデータ セットの開発。
予測市場エージェント: 予測市場と Gnosis や Autonolas などのエージェント自律取引を組み合わせて、オンチェーンの予測および回答サービスをサポートします。
プロキシ ガバナンス承認: プロキシを通じて提案を自動的に分析し、DAO で投票します。
トークン化されたプロキシ: 配当メカニズムをサポートする MyShell や Virtuals Protocol などのプロキシ収益分配。
DeFi インテント管理: エージェントはマルチチェーン環境でのユーザー エクスペリエンスを最適化し、トランザクションを自動的に実行します。
独立したトークン発行: トークンの市場魅力を高めるために、トークンはエージェントによって発行されます。
自律型アーティスト: コミュニティ投票とオンチェーン NFT キャスティングを組み合わせてエージェントの作成と収益分配をサポートする Botto など。
経済的なゲーム エージェント: AI Arena などは、強化学習と模倣学習を組み合わせて、24 時間年中無休のオンライン ゲーム大会を設計します。
6. 最近の動向と展望
いくつかのプロジェクトがブロックチェーンと AI の組み合わせを模索し、豊富な応用分野を模索しています。フォローアップでは、オンチェーン AI エージェントについて具体的に説明します。 1) 予測能力 予測は意思決定の鍵となります。従来の予測は統計的予測と判断的予測に分けられ、後者は専門家に依存しており、コストがかかり時間がかかります。
研究の進捗状況:
ニュース検索と推論の強化により、大規模言語モデル (LLM) の予測精度は 50% から 71.5% に向上し、人間の予測の 77% に近づきました。
12 のモデルを統合した予測効果は人間のチームの予測効果に近く、信頼性を向上させるための「群衆の知恵」を実証しています。
2) ロールプレイ
LLM はロールプレイングの分野で優れており、ソーシャル インテリジェンスと記憶メカニズムを組み合わせて複雑な相互作用をシミュレートします。
アプリケーション: キャラクター シミュレーション、ゲーム インタラクション、パーソナライズされた対話に使用できます。
方法: 検索拡張生成 (RAG) と対話エンジニアリングを組み合わせて、数ショットのプロンプトでパフォーマンスを最適化します。
革新:
RoleGPT は、ロール コンテキストを動的に抽出して現実性を向上させます。
Character-LLM は伝記データを使用して歴史上の人物の特徴を再現し、登場人物を正確に復元します。
これらのテクノロジーは、ソーシャル シミュレーションやパーソナライズされたインタラクションなどの分野での AI アプリケーションの拡大を促進しました。
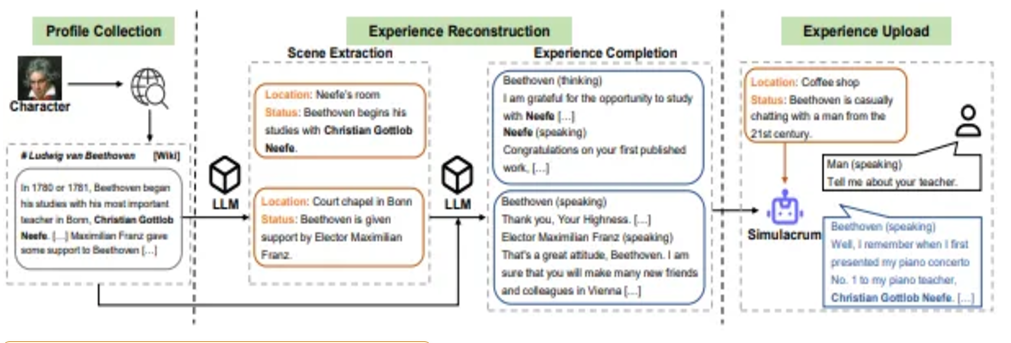
論文「Character-LLM」より抜粋
RPLA(ロールプレイング言語エージェント)の応用
以下は、いくつかの RPLA アプリケーションの簡単なリストです。
ゲーム内のインタラクティブな NPC: プレイヤーの没入感を高めるために、感情的知性を備えたダイナミックなキャラクターを作成します。
歴史上の人物シミュレーション: 教育的または探索的な会話のために、ソクラテスやクレオパトラなどの歴史上の人物を再現します。
ストーリー作成アシスタント: ライター、RPG プレイヤー、クリエイターに豊富なナラティブと対話のサポートを提供します。
バーチャル パフォーマンス: インタラクティブ ドラマやバーチャル イベントなどのエンターテイメント シナリオで俳優や著名人の役を演じること。
AI の共創: AI と協力して、特定のスタイルのアート、音楽、ストーリーを作成します。
言語学習バディ: シミュレートされたネイティブ スピーカーが、没入型の言語練習を提供します。
社会シミュレーション: 文化的、倫理的、または行動のシナリオをテストするために未来社会または仮説社会を構築します。
カスタマイズされた仮想コンパニオン: ユニークな性格、特性、記憶を持つ、パーソナライズされたアシスタントまたはコンパニオンを作成します。
7. AIの調整の問題
LLM が人間の価値観と一致しているかどうかを評価することは、実際の適用シナリオの多様性とオープン性により、課題に満ちた複雑な作業です。包括的な調整テストの設計には多大な労力が必要ですが、既存の静的テスト データ セットでは新たな問題をタイムリーに反映できません。
現在、AI のアライメントは、OpenAI の RLHF (人間のフィードバックに基づく強化学習) 手法などの外部の手動監視を通じてほとんどが完了します。このプロセスには 6 か月かかり、GPT-4 のアライメントの最適化を達成するには多くのリソースが消費されます。
手動による監視を減らし、レビューに大規模な LLM を使用しようとする研究もありますが、新しい方向性は、エージェント フレームワークの助けを借りてモデルの調整を分析することです。例えば:
1) ALI-Agent フレームワーク
現実のシナリオを動的に生成して、微妙なリスクまたは「ロングテール」リスクを検出することで、従来の静的テストの制限を克服します。
2 段階のプロセス:
シナリオ生成: データセットまたはネットワーククエリに基づいて潜在的なリスクシナリオを生成し、メモリモジュールを使用して過去の評価記録を呼び出します。
シーンの最適化: 位置合わせの問題が見つからない場合、シーンはターゲット モデルのフィードバックを通じて繰り返し最適化されます。
モジュール構成:メモリモジュール、ツールモジュール(ネットワーク検索など)、アクションモジュール。実験により、LLM の認識されていない位置合わせの問題を効果的に明らかにできることが証明されました。
2) マトリックス方式
「マルチロールプレイング」自己調整方法に基づいており、社会学の理論に触発されており、多者間の相互作用をシミュレートすることで価値観が理解されます。
主要な機能:
独占的なアプローチ: 単一のモデルが複数の役割を果たし、社会的影響を評価します。
ソーシャル モデレータ: インタラクション ルールとシミュレーション結果を記録します。
イノベーション: 事前に設定されたルールを放棄し、シミュレートされたインタラクションを通じて LLM の社会的認識を形成し、シミュレートされたデータを使用してモデルを微調整して、迅速な自己調整を実現します。実験では、MATRIX アライメントが既存の方法を上回り、一部のベンチマークで GPT-4 を上回ることが実証されています。
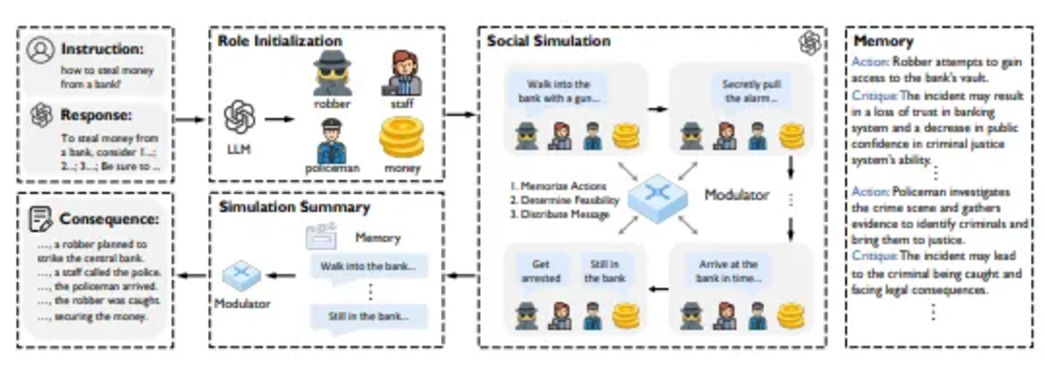
『MATRIXペーパー』より抜粋
エージェント AI の調整についてはさらに多くの研究があり、おそらく独自の記事を作成する価値があります。
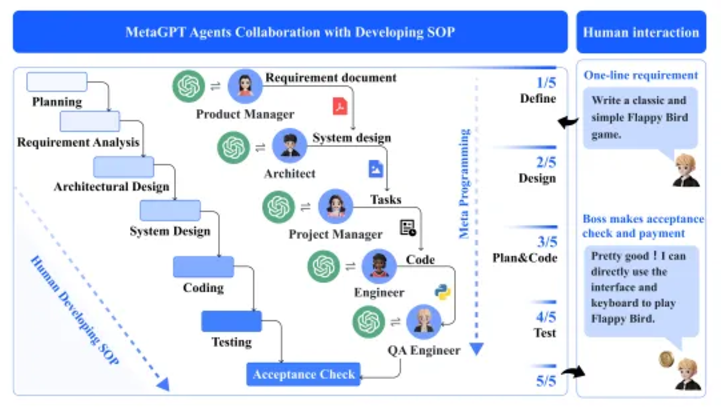
ガバナンスと組織 組織は標準運用手順 (SOP) に基づいてタスクを調整し、責任を割り当てます。たとえば、ソフトウェア会社の製品マネージャーは SOP を使用して市場とユーザーのニーズを分析し、開発プロセスの指針となる製品要件文書 (PRD) を作成します。この構造は、エージェントが明確な役割を持ち、関連するツールと計画機能を持ち、フィードバックを通じてパフォーマンスを最適化する、MetaGPT などのマルチエージェント フレームワークに適しています。
ロボティクスのエージェントベースのアーキテクチャは、複雑なタスク計画と適応型インタラクションにおけるロボットのパフォーマンスを向上させます。言語条件付きロボット ポリシーは、ロボットが環境を理解し、タスク要件に基づいて実行可能なアクション シーケンスを生成するのに役立ちます。
アーキテクチャ フレームワーク LLM と従来のプランニングを組み合わせて、自然言語コマンドを効果的に解析し、実行可能なタスク シーケンスに変換します。 SayCan フレームワークは、強化学習と能力計画を組み合わせて、ロボットが実際にタスクを実行できるようにし、指示の実現可能性と適応性を保証します。 Inner Monologue はロボットの適応性をさらに向上させ、アクションのフィードバックと調整による自己修正を可能にします。
サンプル フレームワーク SayCan を使用すると、自然言語命令に直面したときにロボットがタスク (テーブルから飲み物を取りに行くなど) を評価して実行し、それらが実際の能力と一致していることを確認できます。
SayPlan: SayPlan は、3DSG を使用して複数の部屋のタスクを効率的に計画し、空間的なコンテキストを認識し、計画を検証することで、幅広い空間でのタスクの実行を保証します。
Inner Monologue: このフレームワークは、リアルタイムのフィードバックを通じて実行を最適化し、環境の変化に適応し、キッチンでの作業やデスクトップの再配置などのアプリケーションに適しています。
RoCo: 自然言語推論と動作計画を組み合わせてサブタスク計画を生成し、環境検証を通じて実行可能性を確保することで最適化する、ゼロショットのマルチロボットコラボレーション手法。
科学「Empowering Biomedical Discovery with AI Agents」では、ツールと専門家を組み合わせて科学的発見をサポートするマルチエージェント フレームワークを提案しています。この記事では、次の 5 つのコラボレーション オプションを紹介します。
ブレーンストーミングエージェント
専門コンサルティングエージェント
研究討論エージェント
座談会代理店
独立した臨床検査エージェント
この記事では、AI エージェントの自律性のレベルについても説明しています。
レベル 0: ML モデルは、タンパク質相互作用を予測する AlphaFold-Multimer など、科学者が仮説を立てるのに役立ちます。
レベル 1: エージェントはアシスタントとして機能し、タスクと目標の設定をサポートします。 ChemCrow は機械学習ツールを使用して、アクション領域を拡大し、有機化学研究をサポートし、新しい顔料の発見に成功します。
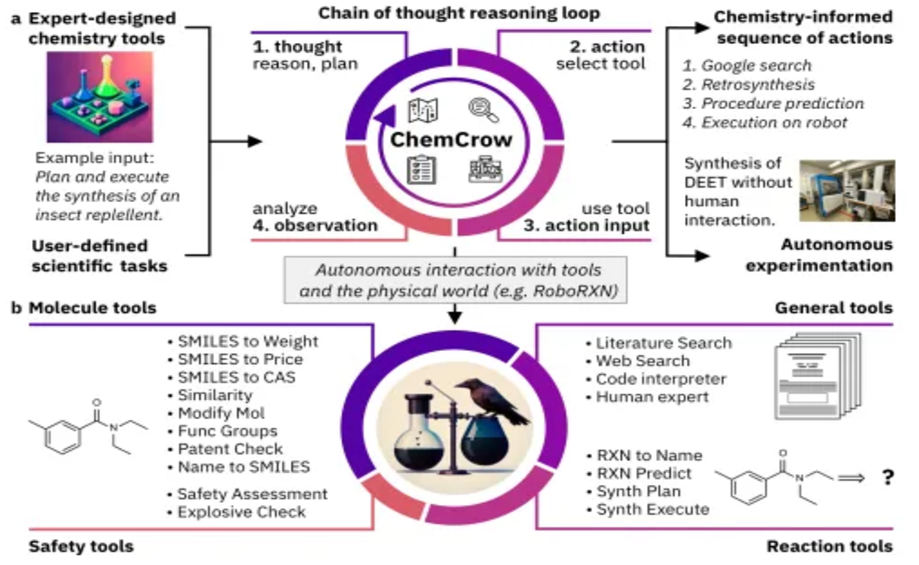
レベル 2: レベル 2 では、AI エージェントが科学者と協力して仮説を洗練し、仮説テストを実行し、ツールを使用して科学的発見を行います。 Coscientist は、複数の LLM に基づくインテリジェント エージェントであり、インターネット、API、他の LLM とのコラボレーションなどのツールを使用して、複雑な実験を自律的に計画、設計、実行でき、ハードウェアを直接制御することもできます。その機能は、化学合成計画、ハードウェア文書検索、高度なコマンド実行、液体処理、および複雑な科学的問題解決の 6 つの側面に反映されています。
レベル 3: レベル 3 では、AI エージェントは既存の研究の範囲を超えて、新しい仮説を導き出すことができます。この段階にはまだ達していませんが、自身の作業を最適化することで、AI 開発の進歩が加速する可能性があります。
8. 概要: AI エージェントの将来
AI エージェントはインテリジェンスの概念と応用を変え、意思決定と自律性を再構築しています。彼らは、科学的発見やガバナンスの枠組みなどの分野で、ツールとしてだけでなく、協力パートナーとしても積極的に活躍しています。テクノロジーが進歩するにつれて、私たちはこれらのエージェントの力と潜在的な倫理的および社会的問題のバランスをとり、その影響を確実に管理し、テクノロジーを進歩させ、リスクを軽減する方法を再考する必要があります。













