
著者: Zen、PANews
AIは現在、暗号通貨業界で最も注目されている分野です。中でも、資金調達総額5,000万米ドルのa16zが主導する分散型AIコンピューティングネットワークであるGensynは、間違いなく競争力のあるプロジェクトです。最近、Gensyn はテストネットワークを正式に立ち上げました。当初の計画より1年以上遅れではありますが、ようやくテストネットワークの立ち上げにより新たな段階に入りました。
機械学習専用に構築されたカスタマイズされた Ethereum Rollup として、Gensyn テストネットはオフチェーン実行、検証、通信フレームワークを統合し、永続的な ID、参加追跡、属性維持、支払い、リモート実行調整、トラストレス検証、トレーニング プロセスの記録、大規模なトレーニング タスクのクラウドファンディングなどの主要機能を分散型 AI システムに提供することを目指しています。
テストネットの最初のフェーズでは、RL Swarm 内の参加を追跡することに重点が置かれます。 RL Swarm は、トレーニング後の共同強化学習のためのアプリケーションであり、ノードをオンチェーン ID にバインドして、参加している各ノードの貢献が正確に記録されるようにすることができます。
RL Swarm: コア機能と共同トレーニング
Gensyn テストネットでは、コア アプリケーションとしての RL Swarm は、分散型ネットワーク上に構築されたモデル共同トレーニング システムです。従来の単一モデルの独立したトレーニングとは異なり、RL Swarm では、複数のモデルがネットワーク内で通信、批判、相互改善できるため、全体的なパフォーマンスが共同で向上します。その中核となるコンセプトは「集合知」、つまりノード モデル間のコラボレーションとフィードバックを通じてより効率的なトレーニング結果を達成することにあります。
DeepSeek-R1 などのモデルが推論トレーニングを実行するときに、自己批判を通じて推論パフォーマンスを反復的に向上できることは簡単に理解できますが、RL Swarm はこのメカニズムを複数のモデルのグループに拡張し、「多くの手で作業が楽になる」効果を実現します。
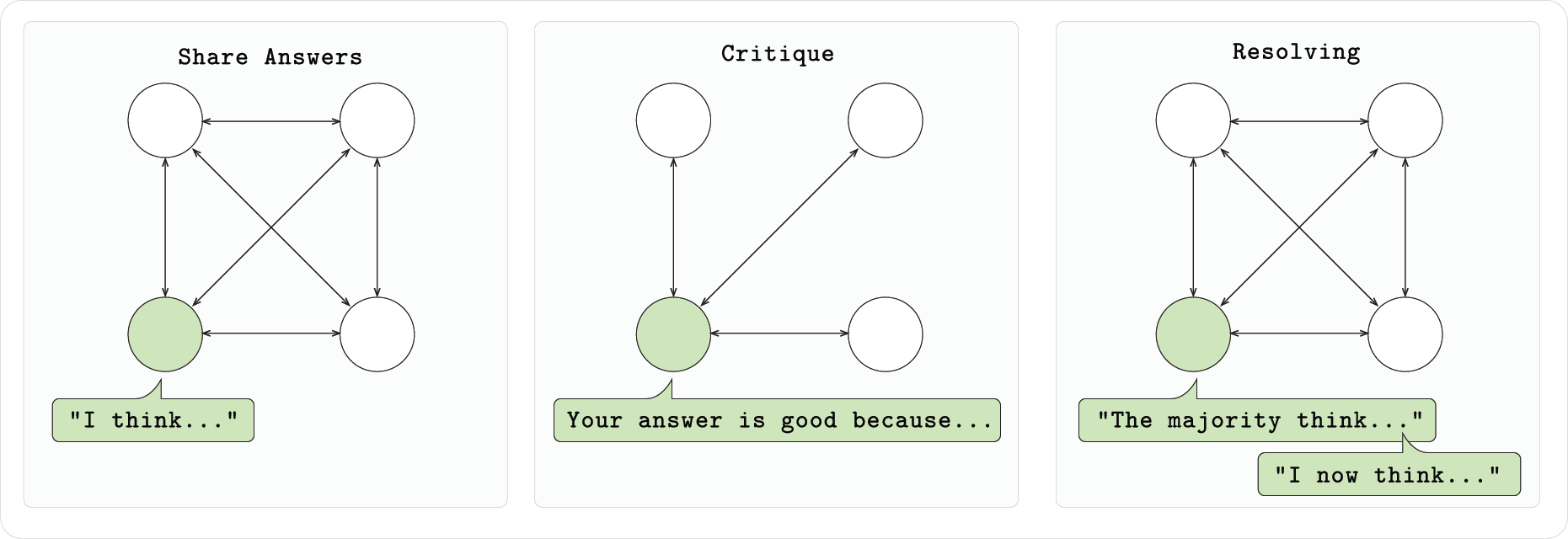
RL Swarm システムに基づくこのモデルは、独自のフィードバックに依存するだけでなく、独自の欠点を特定し、他のモデルのパフォーマンスを観察および評価することでそれらを最適化します。 Swarm に参加する各モデル ノードは、3 段階のプロセスに参加します。最初に、独立して問題を完了し、アイデアと回答を出力します。次に、他のノードの回答をチェックしてフィードバックを提供し、最後にモデルが最適なソリューションに投票し、それに応じて出力を修正します。この相乗的なメカニズムは、各モデルのパフォーマンスを向上させるだけでなく、グループモデル全体の進化を促進します。 Swarm に参加したモデルは、参加を中止した後も改善されたローカル重みを保持できるため、実際のメリットが得られます。
さらに、Gensyn は RL Swarm のコードをオープンソース化しており、誰でも許可なくノードを実行し、既存の Swarm を開始したり参加したりできるようになりました。 Swarm の基盤となる通信では、Hivemind が提供するゴシップ プロトコルが使用され、分散型のメッセージ パッシングとモデル間の学習信号の共有がサポートされます。自宅のラップトップでもクラウド GPU でも、RL Swarm ノードに参加することで共同トレーニングに参加できます。
インフラストラクチャの3つの柱:実行、コミュニケーション、検証
現在、RL Swarm はまだ実験的なデモンストレーションの段階であり、最終製品の形ではなく、大規模でスケーラブルな機械学習手法を示しています。過去 4 年間、Gensyn の主な業務は、基盤となるインフラストラクチャの構築でした。テストネットワークのリリース後、v0.1 段階に入り、実際の運用が可能になりました。公式紹介によると、Gensyn の全体的なアーキテクチャは、実行、通信、検証の 3 つの部分に分かれています。
実行: 一貫性と分散コンピューティング
Gensyn は、将来の機械学習は従来のモノリシック モデルに限定されず、世界中のデバイスに分散された断片化されたパラメーターで構成されるようになると考えています。この目標を達成するために、Gensyn チームは、デバイス間の一貫性を保証する基盤となる実行アーキテクチャを開発しました。主なテクノロジーは次のとおりです。
- 分散パラメータの保存とトレーニング: 大規模モデルを複数のパラメータ ブロックに分割し、異なるデバイスに分散させることで、Gensyn はモデルの断片化された展開を実現し、単一ノードのメモリ要件を削減します。
- RL 事後トレーニング: 研究によると、モデルがグループで共同でトレーニングされ、互いに通信し、互いの回答を批評すると、全体的な学習効率が大幅に向上することがわかっています。 Gensyn は RL Swarm を使用してこの概念を実証し、グループ ディスカッションでモデルを迅速に改善し、分散実行の有効性をさらに検証しました。
- 再現可能な演算子 (RepOps): 異なるハードウェア (Nvidia A100 や H100 など) がまったく同じ計算結果を生成できるようにするため、Gensyn は RepOps ライブラリを開発しました。このライブラリは、浮動小数点演算の実行順序を固定することで、クロスプラットフォームでのビット単位の再現を実現します。
コミュニケーション: 効率的な情報交換
大規模な分散トレーニング シナリオでは、ノード間の効率的な通信が重要です。従来のデータ並列方式では、通信オーバーヘッドをある程度削減できますが、各ノードに完全なモデルを格納する必要があるため、スケーラビリティはメモリによって制限されます。この目的のために、Gensyn は新しい解決策を提案しました。
- SkipPipe – 動的スキップ パイプライン並列処理: SkipPipe テクノロジーは、マイクロバッチが通過するコンピューティング レイヤーを動的に選択し、従来のパイプラインの一部のステージをスキップして、不要な待機時間を削減します。革新的なスケジューリング アルゴリズムにより、各パスの可用性をリアルタイムで評価できるため、ノードのアイドル時間が短縮されるだけでなく、全体的なトレーニング時間も大幅に短縮されます。テストデータによると、分散環境では、SkipPipe はトレーニング時間を約 55% 短縮でき、部分的なノード障害が発生した場合でも、モデルのパフォーマンスは約 7% しか低下しません。
- 通信規格とノード間のコラボレーション Gensyn は、TCP/IP に類似した一連の通信プロトコルを構築しました。これにより、世界中の参加者は、使用するデバイスに関係なく、効率的かつシームレスにデータを送信し、情報を交換できるようになります。このオープン スタンダードは、分散型の共同トレーニングのための強固なネットワーク基盤を提供します。
検証: 信頼とセキュリティの確保
信頼を必要としない分散型ネットワークでは、各参加者が提出した計算結果が本物で有効であることをいかに確認するかが大きな課題です。 Gensyn は、すべてのコンピューティング パワー サプライヤーが低コストで効率的なメカニズムを通じて正しい作業結果を提供できるように、専用の検証プロトコルを導入しました。
- Verde 検証プロトコル: Verde は、最新の機械学習向けに特別に設計された最初の検証システムです。その中核となるのは、軽量の紛争解決メカニズムを使用して、モデルと検証者の間で不一致が発生するトレーニング プロセスのステップを迅速に特定することです。タスク全体を再実行する必要がある従来の検証方法とは異なり、Verde では、異議のある操作を再計算するだけで済むため、検証のオーバーヘッドが大幅に削減されます。
- 審判による委任: この方法では、サプライヤーの出力に問題がある場合、バリデータは効率的な紛争解決ゲームを通じて中立的な仲裁人を説得し、少なくとも 1 つの正直なノードが存在する場合に計算結果全体の正確性が保証されるようにすることができます。
- 中間状態の保存とハッシュ化: 上記の検証プロセスをサポートするために、参加者は完全なデータではなく、いくつかの中間トレーニング チェックポイントを保存してハッシュ化するだけで済みます。これにより、リソースの使用量を削減できるだけでなく、システムのスケーラビリティとリアルタイム パフォーマンスも向上します。














