
什麼是 FHE
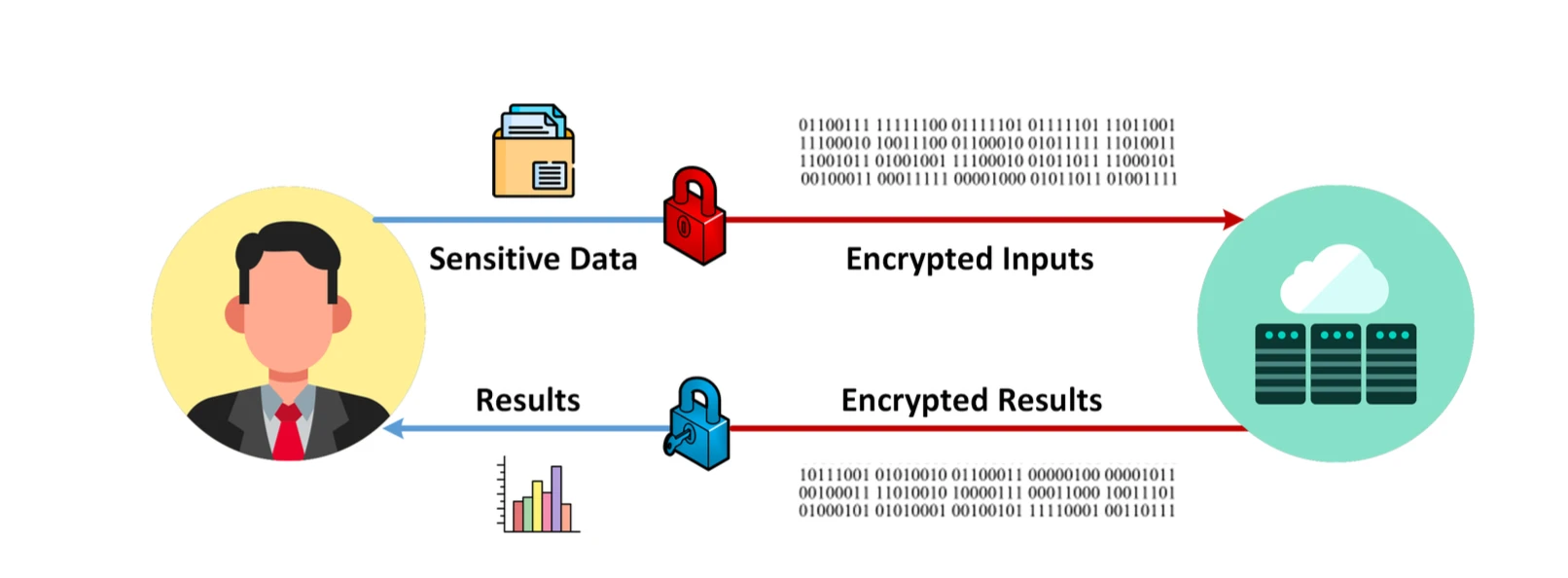
FHE 流程,圖源:Data Privacy Made Easy
FHE(Fully homomorphic encryption)是一項先進的加密技術,可以支援在加密的資料上進行直接計算。這意味著可以在保護隱私的同時對資料進行處理。 FHE 有多個可落地的場景,特別是在隱私保護下的資料處理與分析,如金融、醫療健康、雲端運算、機器學習、投票系統、物聯網、區塊鏈隱私保護等領域。但是商業化仍然需要一定的時間,主要問題在於其演算法帶來的運算與記憶體開銷極為龐大,可拓展性較差。接下來我們將簡要 walk through 整個演算法基本原理以及著重講述該密碼學演算法面臨的問題。
基本原理
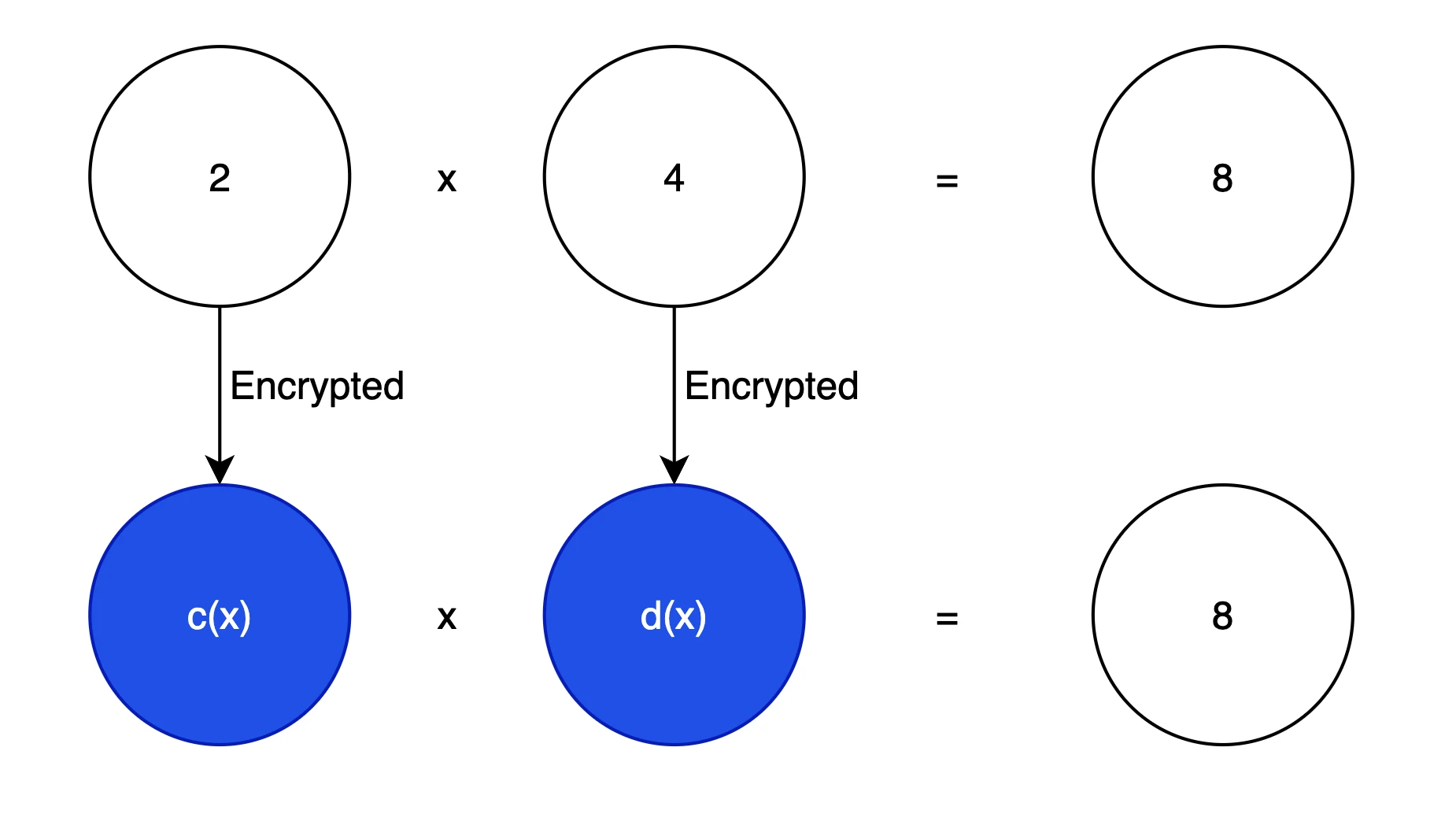
同態加密圖示
首先,我們要實現加密的資料進行計算然後還能得到相同的結果,我們可視化如上圖所示。這是我們的基本目標。在密碼學中,通常使用多項式,來隱藏原文的信息,因為多項式能夠轉換為線性代數的問題,也可以轉換為向量的計算問題,這便於為向量進行高度優化的現代計算機進行運算(如並行計算),例如, 3 x 2 + 2 x + 1 可以表示為向量[ 1, 2, 3 ]。
假設,我們要加密 2 ,在一個簡化的 HE 系統中,我們可能會:
- 選擇一個密鑰多項式,例如 s(x) = 3 x 2 + 2 x + 1
- 產生一個隨機多項式,例如 a(x) = 2 x 2 + 5 x + 3
- 產生一個小的「錯誤」多項式,例如 e(x) = -1 x + 2
- 加密 2 -> c(x) = 2 + a(x)*s(x) + e(x)
我們講一下為什麼需要這樣做,我們現在假設拿到了密文c(x),如果想要得到明文m,則公式為c(x) - e(x) - a(x)*s(x) = 2 ,這裡我們隨機多項式假設a(x)是公開的,那麼只要保證我們的密鑰s(x)是保密的即可,我們如果知道了s(x),再加上c(x)作為一個很小的誤差,那麼理論上可以忽略,就能得到明文m。
這裡有第一個問題,多項式那麼多,要如何選擇多項式呢?多項式的度多大比較好呢?實際上多項式的度是由實現 HE 的演算法決定的。通常是 2 的冪次,如 1024 / 2048 等。多項式的係數由一個有限域q 中隨機選擇,如mod 10000 ,則在 0-9999 中隨機選擇,係數隨機選擇有很多演算法遵循,如均勻分佈、離散高斯分佈等等。不同的方案也有不同的係數選擇要求,通常是為了滿足該方案下的快速解原則。
第二個問題,噪音是什麼?雜訊是用來迷惑攻擊者的,因為假設我們的所有數字都是採用s(x),並且隨機多項式處於一個有域中,那麼就存在一定的規律,只要輸入足夠多次的明文m,根據輸出的c(x),就能判斷這兩個s(x)與c(x)的資訊。如果引入了雜訊 e(x),就能確保無法透過簡單的重複列舉來獲得 s(x)與 c(x),因為這有一個完全隨機的小誤差存在。這個參數也被稱為噪音預算(Noise Budget)。假設 q = 2 ^ 32 ,初始雜訊可能在 2 ^ 3 左右。經過一些操作後,雜訊可能會成長到 2 ^ 20 。此時仍有足夠空間進行解密,因為 2 ^ 20 << 2 ^ 32 。
我們得到了多項式以後,我們現在要把c(x) * d(x)操作轉換為“電路”,這個在ZKP 中也經常出現,主要是因為電路這個抽象概念提供了一個通用的計算模型表示任何計算,且電路模型允許精確追蹤和管理每個操作引入的噪聲,也方便後續引入到專業硬體中如ASIC、FPGA 進行加速計算,如SIMD 模型。任何複雜的操作都可以映射成簡單的模組化的電路元素,如加法和乘法。

算術電路表示
加法和乘法就能夠表達減法以及除法,因此就能夠表達任意計算。多項式的係數以二進位表示,稱為電路的輸入。每個電路的節點代表了執行一次加法或乘法。每個(*)代表乘法門,每個(+)代表加法門。這個就是演算法電路。
這裡就引申出一個問題,我們為了語意訊息上不洩漏,因此引入了 e(x),稱為雜訊。在我們的計算中,加法會讓兩個 e(x)多項式變成,同度的多項式。在乘法中,兩個雜訊多項式相乘,會讓e(x)的度數以及文字大小指數級增加,如果雜訊過大,就會導致結果計算的過程中,雜訊無法忽略,進而導致原文m 無法恢復。這是一個限制 HE 演算法表達任意計算的主要原因,因為雜訊會呈指數級增長,導致很快就達到了不可用的閾值。在電路中,這個稱為電路的深度,乘法運算的次數也就是電路的深度數值。
同態加密 HE 的基本原理如上圖所示,為了解決限制同態加密的噪音問題,因此提出了多項解決方案:
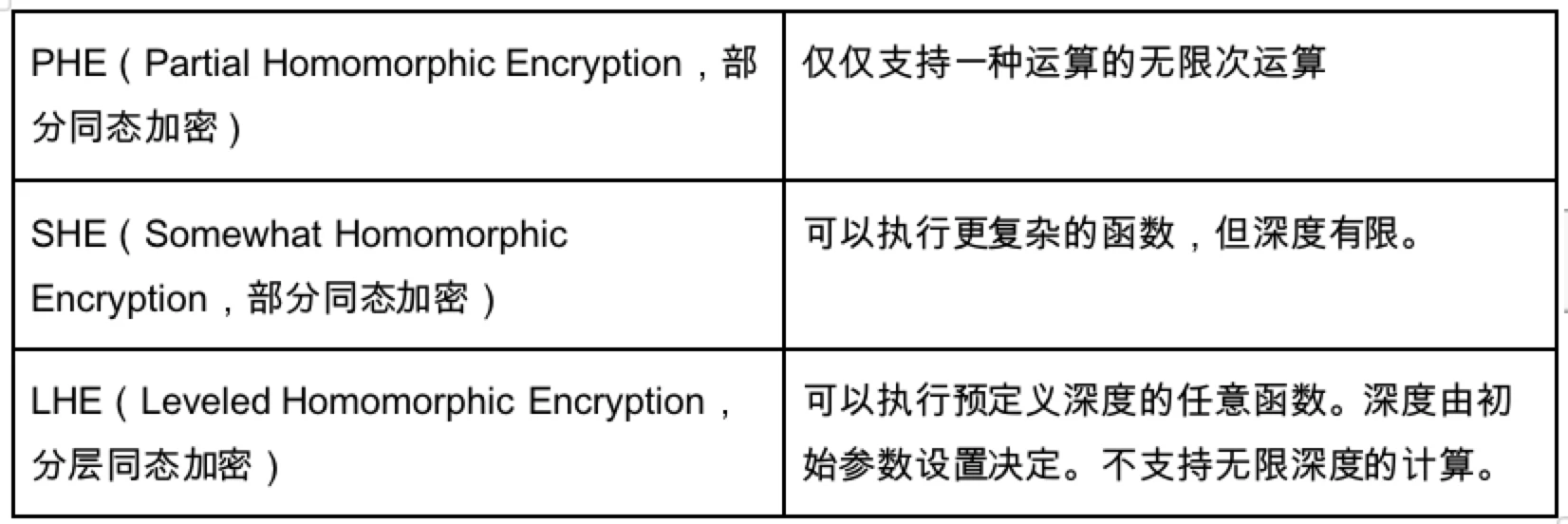
這裡面 LHE 是一個很適合的演算法,因為在這個演算法下,只要深度確定了就能在深度內執行任意函數,但是 PHE 以及 SHE 無法實現圖靈完備。因此在這個基礎上,密碼學家進行研究,提出了三個技術來建構 FHE 全同態加密,期望實現在無限深度執行任意函數的願景。
- Key switching(密鑰切換):我們在乘法後,密文的大小會呈指數級增長,這會讓後續的操作內存和計算資源提出極大的要求,因此在每次乘法後實施Key switching 就能壓縮密文,但是會引入一點噪音。
- Modulus Switching(模數切換):無論是乘法還是key switching 都會讓噪聲指數級增加,模數q 是我們前面講過的Mod 10000 ,只能在[ 0, 9999 ]裡面取參數,q 越大則噪聲經過多次計算後最後雜訊仍然在q 內,則可以解密。因此在多次操作後,為了避免噪音指數級增大超過閾值,那麼就需要使用 Modulus Switching,來減少噪音預算,這樣就可以壓低噪音。我們在這裡就可以得到一個基本的原理,如果我們的計算很複雜,電路深度很大,那麼就需要更大的模數 q 噪音預算來容納多次指數級增長後的可用性。
- Bootstrap:但想要實現無限深度的運算,Modulus 只能限制雜訊的成長,但每次切換會讓 q 範圍變小,我們知道一旦減少,代表計算的複雜度就需要降低。 Bootstrap 是一項刷新技術,就是將噪聲重置到原始水平,而不是減少噪聲,bootstrap 不需要減少模數,因此可以維持系統的運算能力。但是其弊端就是需要消耗大量的算力資源。
總的來說,針對有限步驟下的計算,使用 Modulus Switching 能夠降低噪音,但同時也會降低模數,也就是噪音預算,導致壓縮運算能力。因此這僅僅針對有限步驟下的計算。對於 Bootstrap 能夠實現噪音重置,因此在基於 LHE 演算法之上,能夠實現真正意義上的 FHE,也就是任意函數的無限計算,而這也是 FHE 的 Fully 的意義。
但缺點也很明顯就是需要消耗大量的算力資源,因此一般情況下,這兩種降噪技術會結合使用,Modulus switching 用於日常的噪音管理,延遲需要 bootstrap 的時間。當 modulus switching 無法進一步有效控制噪音時,才使用計算成本較高的 bootstrap。
目前 FHE 的方案有以下具體的實現,都使用的 Bootstrap 核心技術:
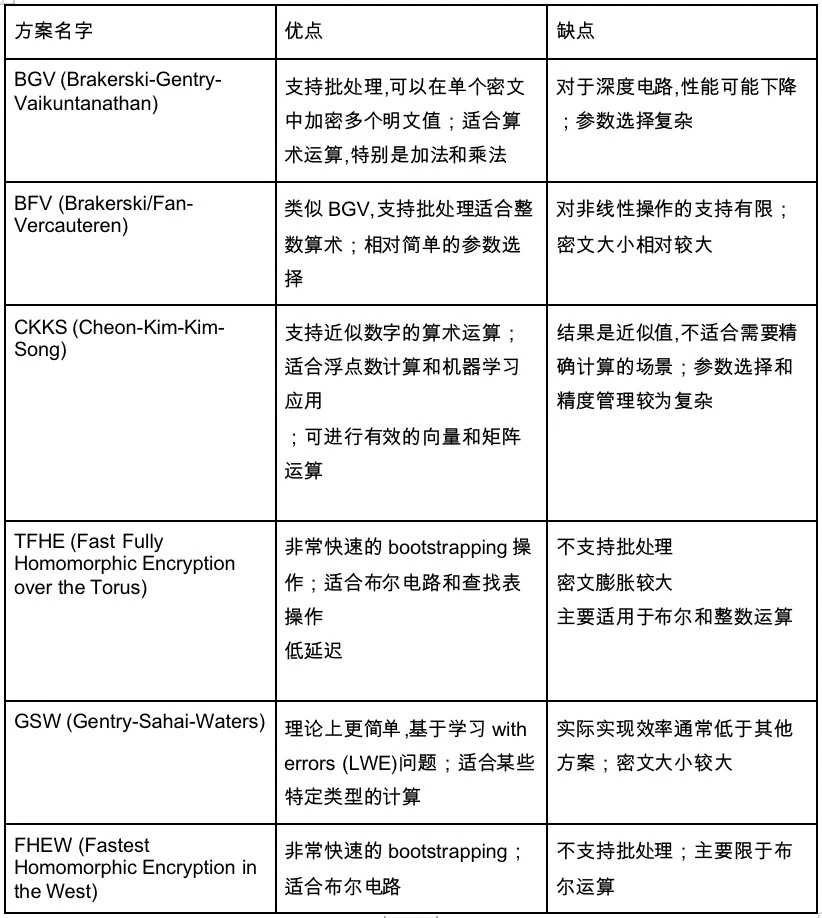
這裡也引出了我們一直未談及的電路類型,上面我們介紹的主要是算術電路。但是還有另外一個電路類型——布林電路。算術電路是1+ 1 這種比較抽象的,節點也是加法或除法,而布林電路所有的數字轉換為01 進制,所有的節點是bool 運算,包括NOT、OR、AND 運算,類似我們的計算機的電路實現。而算術電路更是抽像上的電路。
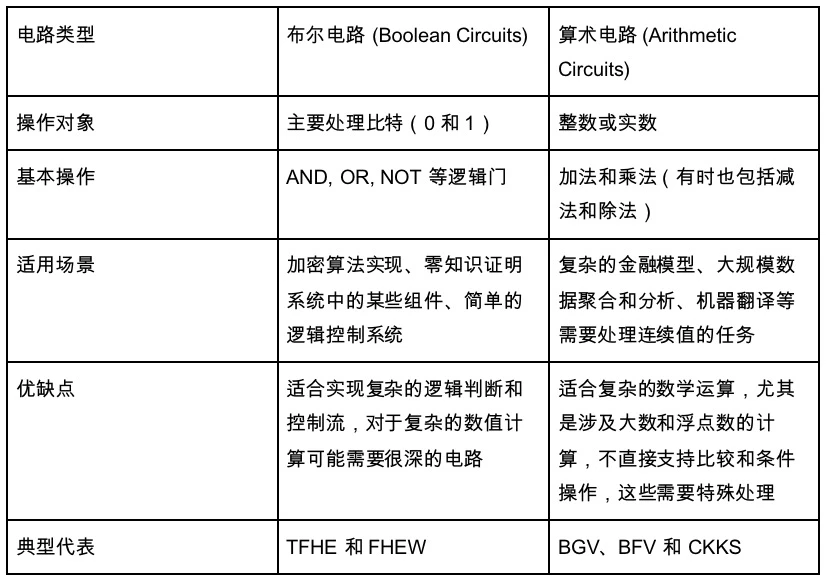
因此,我們可以非常粗略的將布林運算視為沒有那麼資料密集的靈活的處理,而算術運算是針對資料密集型應用的方案。
FHE 面臨的問題
由於我們的計算需要加密然後轉換為“電路”,並且由於單純的計算僅僅計算2+ 4 ,但是在加密後,引入了大量的密碼學間接的計算過程,以及一些前沿技術如Bootstrap 來解決噪聲問題,進而導致了其計算開銷是普通計算的N 個數量級。
我們以一個現實世界的列子來讓讀者感受這些額外的密碼過程對計算資源的開銷。假設普通計算在一個 3 GHz 的處理器上需要 200 個時脈週期,那麼一次普通的 AES-128 解密大約需要 67 奈秒( 200/3 GHz)。 FHE 版本需要 35 秒,是普通版本的大約 522, 388, 060 倍( 35/67 e-9)。也就是,使用相同的計算資源,同一個普通演算法和 FHE 計算下的演算法,其對計算資源的要求大概是 5 億倍。

DARPA dprive 計劃,圖片來源:DARPA
美國的DARPA 為了資料安全,因此在2021 年專門建立了一個Dprive 計劃,邀請了多個研究團隊包括微軟、Intel 等,他們的目標是創建一個FHE 加速器以及配套的軟體堆疊,使FHE 計算速度更符合未加密資料的類似操作,實現FHE 計算速度大約為普通計算的1/10 的目標。 DARPA 專案經理Tom Rondeau 指出:「估計,在FHE 世界中,我們的計算速度比在純文字世界中慢約一百萬倍。
而 Dprive 主要從以下幾個面向著手:
- 增大處理器字長:現代電腦系統使用64 位的字長,也就是一個數字最多64 位,但是實際上q 往往1024 位,如果想要實現就要拆分我們的q,這樣會對內存資源和速度有損耗。因此為了實現更大的 q,需要建造一個 1024 位元或更大字長的處理器。有限域 q 非常重要,就像我們前面提到的,越大,那麼可計算的步驟就越多,對於 bootstrap 的操作就可以盡可能的往後推遲,這樣整體的計算資源消耗就會減少。 q 在 FHE 中扮演著核心角色,它影響了方案的幾乎所有方面,包括安全性、性能、能夠進行的計算量以及所需的記憶體資源。
- 建構一個 ASIC 處理器:我們前面講到過由於便於並行化以及其它原因,我們構建了多項式,通過多項式構建了電路,這個和 ZK 是相似的。目前的 CPU、GPU 不具備這個能力(算力資源以及記憶體資源)來運作電路,需要建構專門的 ASIC 處理器來允許 FHE 演算法。
- 建構平行化架構 MIMD,與 SIMD 平行架構不同,SIMD 只能在多個資料上執行單一指令,也就是資料的拆分與平行處理,但 MIMD 可以分割資料使用不同的指令進行運算。 SIMD 主要用於資料並行,這也是大多數區塊鏈專案對交易並行處理的主要架構。而 MIMD 能夠處理各種類型的平行任務。 MIMD 在技術上更複雜,需要著重處理同步與通訊問題。
距離DARPA 的DEPRIVE 計劃僅僅剩下一個月的時間就到期了,原本計劃Dprvie 是從2021 年開始, 2024 年9 月份三個階段的計劃結束,但是似乎其進展緩慢,目前仍然未達到預期的相比於普通計算1/10 效率的目標。
雖然攻破 FHE 技術進展緩慢,類似 ZK 技術一樣,面臨這硬體落地是技術落地的前提這一嚴峻問題。但是,我們仍然認為從長期來看,FHE 技術仍然有其獨特的意義,特別是我們第一部分羅列的保護部分安全資料的隱私。對於 DARPA 國防部來說,其掌握了大量的敏感數據,如果想要將 AI 泛型能力釋放到軍事上,就需要以數據安全的形式訓練 AI。不僅如此,對於醫療、金融等關鍵敏感資料也同樣適用,實際上 FHE 並不適用於所有的普通計算,更面向敏感資料下的運算需求,而這種安全性對於後量子時代尤其重要。
對於這種尖端技術,必須考慮投資週期與商業化落地的時間差。因此,我們需要非常謹慎的看待 FHE 的落地時間。
區塊鏈的結合
在區塊鏈中,FHE 也主要用於保護資料的隱私性,應用領域包括鏈上隱私、AI 訓練資料的隱私、鏈上投票隱私、鏈上隱私交易審查等方向。其中 FHE 也被稱為鏈上 MEV 方案的潛在解決方向之一。根據我們的MEV 的文章《照亮黑暗森林— 揭開MEV 神秘面紗》所述,目前的許多MEV 方案只是重新建構MEV 架構的方式,並不是解決的方式,實際上三明治攻擊帶來的UX 問題仍然沒有解決。我們一開始想到的方案也是,直接對交易加密,同時保持狀態的公開。
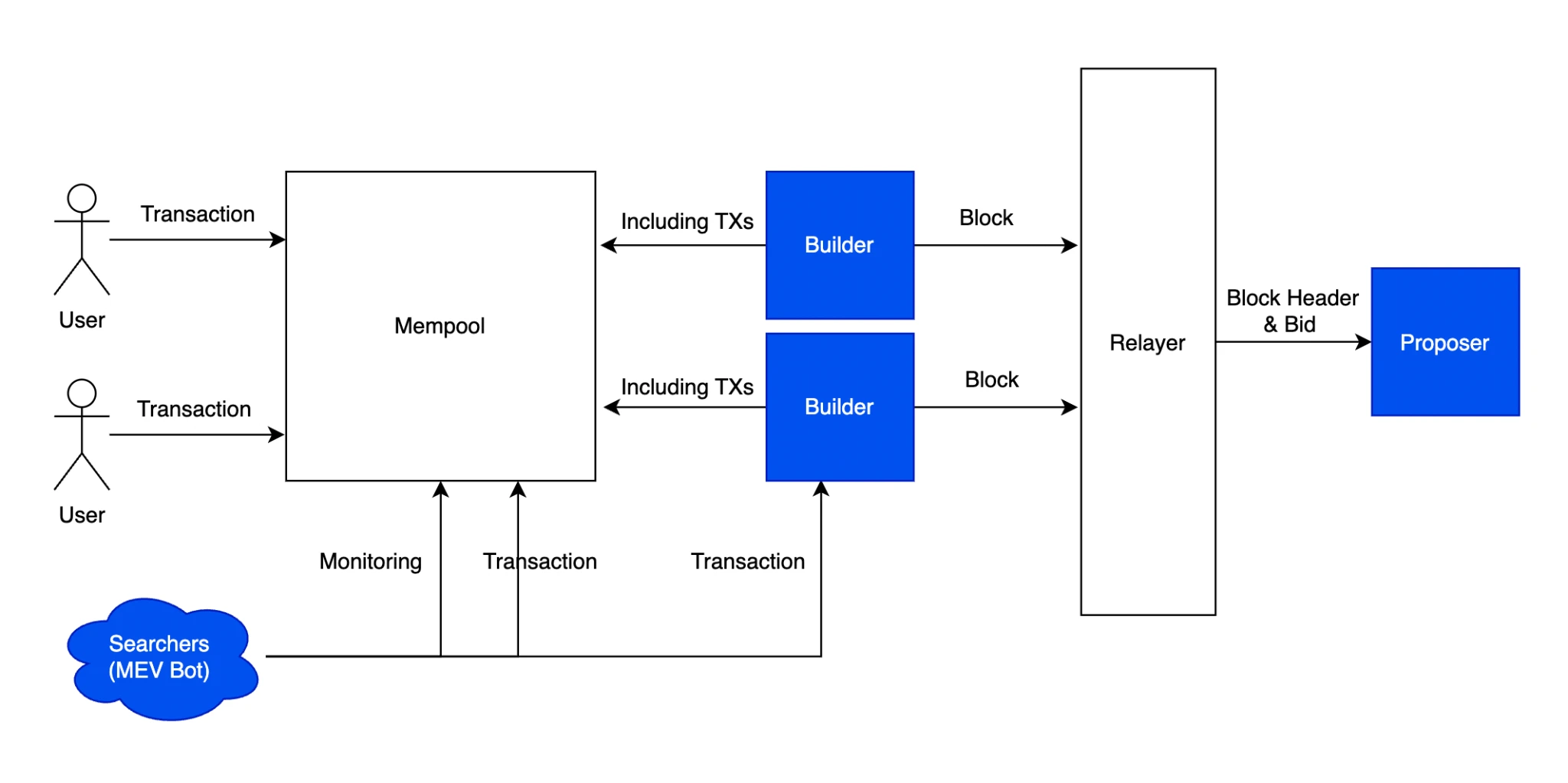
MEV PBS 流程
但是也有一個問題就是如果我們對交易進行完全的加密,就會讓MEV bots 帶來的正外部性也同時消失,驗證者Builder 需要運行在虛擬機的基礎上進行FHE,驗證者也需要驗證交易以確定最後的狀態正確性,那麼就會顯著提高運行節點的要求,讓整個網路的吞吐量放慢百萬倍。
主要項目
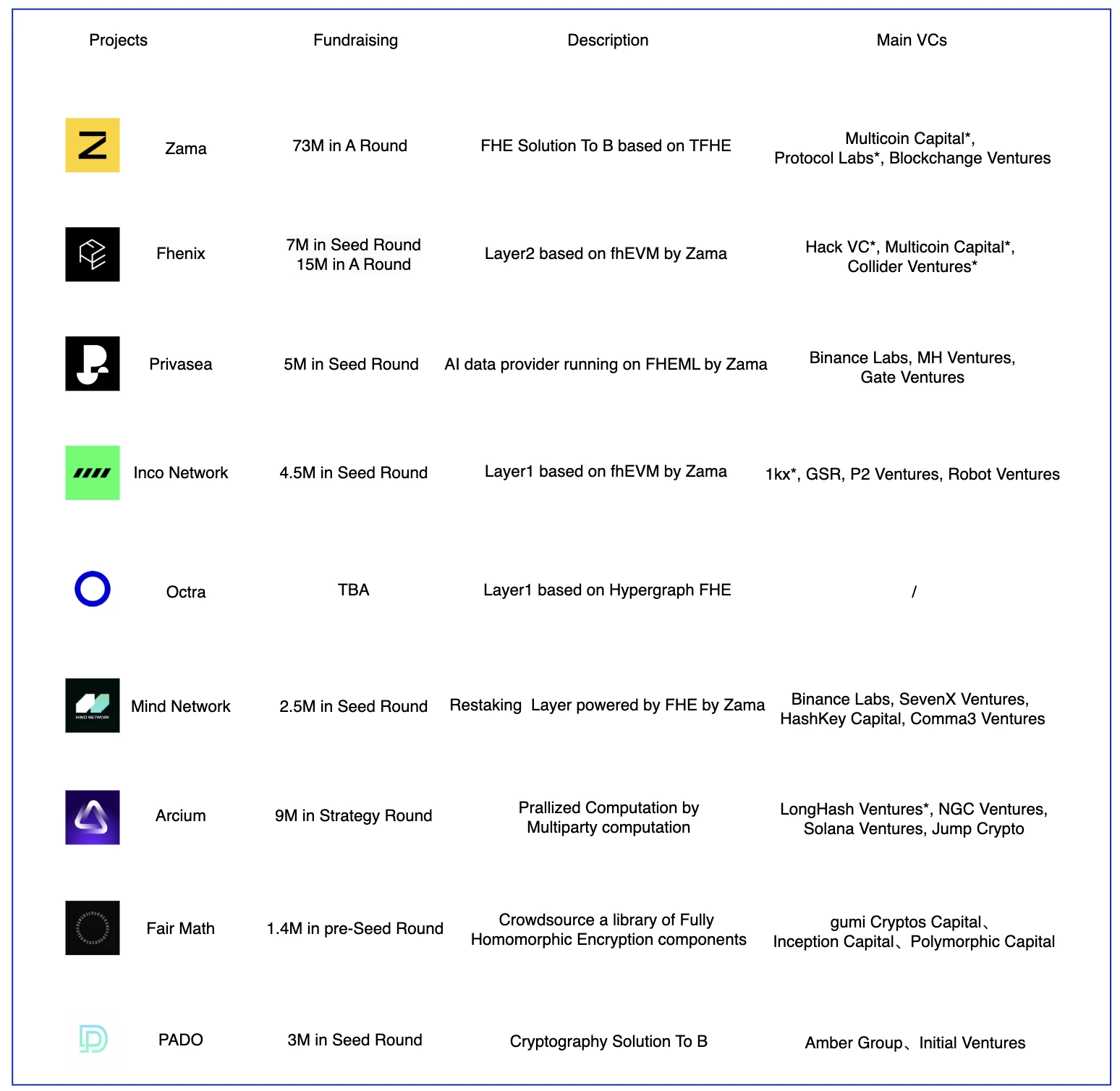
FHE Landscape
FHE 是一項較新的技術,目前大部分的專案使用的 FHE 技術都來自於 Zama 所建構的,如 Fhenix、Privasea、Inco Network、Mind Network。 Zama 的 FHE 工程實現能力獲得了這些項目的認可。以上幾個項目大部分都基於 Zama 提供的庫進行構建,主要區別在於商業模式。 Fhenix 希望建立一個隱私優先的Optimism Layer 2 ,Privasea 希望運用FHE 的能力來進行LLM 的資料運算,但是這是一項非常重資料的操作,對FHE 的技術與硬體要求都特別高,然後Zama 基於的TFHE 可能不是最優的選擇。 Inco Network 與 Fhenix 都使用 fhEVM,但一個是建構 Layer 1 一個是 Layer 2 。 Arcium 是建構了多種密碼學技術的融合,包括了 FHE、MPC 和 ZK。 Mind Network 的商業模式比較另闢蹊徑,選擇了 Restaking 賽道,透過提供流動安全性和基於 FHE 的子網路架構來解決共識層的經濟安全與投票信任的問題。
Zama
Zama 是基於TFHE 的方案,其特點是使用了Bootstrap 技術,其著重於處理布林運算和低字長的整數運算,雖然在我們實現了FHE 的方案中是一個較快的技術實現,但其相比與普通計算仍然有非常大的差距,其次也無法去實現任意計算,在面對資料密集型的任務時,這些運算會導致電路的深度過大而無法處理。其不是資料密集的方案,其只適用於某些關鍵步驟的加密處理。
TFHE 目前已經有了現成的實作程式碼,Zama 的主要工作是使用 Rust 語言重寫了 TFHE,也就是其 rs-TFHE crates。同時為了降低使用者使用 Rust 的門檻,也建構了一個轉編譯的工具 Concrate,能夠把 Python 轉換成 rs-TFHE 等價的。使用這個工具,就能把基於的 Python 的大模型語言轉譯到基於 TFHE-rs 的 rust 語言。這樣就能運行基於同態加密的大模型,但這時資料密集的任務,其實並不適合 TFHE 的場景。 Zama 的產品 fhEVM 是一種使用完全同態加密(FHE)在EVM 上實現機密智能合約的技術,能夠支援基於 Solidity 語言編譯端對端加密的智能合約。
總的來說,Zama 作為一個 To B 的產品,其建構了較為完善的基於 TFHE 的區塊鏈+AI 開發堆疊。能夠幫助web3的專案簡單的建構 FHE 的基礎設施和應用。
Octra
Octra 比較特別的一點是,使用了另闢蹊徑的技術來實現 FHE。其使用了一個稱為 hypergraphs 的技術來實作 bootstrap。也是基於布林電路,但是 Octra 認為基於 hypergraphs 的技術,能實現更有效率的 FHE。這是 Octra 實現 FHE 的原創技術,團隊具備非常強的工程、密碼學能力。
Octra 建立了新的智慧合約語言,其使用 OCaml、AST、ReasonML(一種專門用於與Octra 區塊鏈網路互動的智慧合約和應用程式的語言)等程式碼庫和C++ 進行開發。其建構的 Hyperghraph FHE 庫,能夠與任何項目相容。
其架構也是類似 Mind Network、Bittensor、Allora 等項目,其建構了一個主網,然後其它項目成為 subnets,建構了一個相互隔離的運作環境。同時,與這些專案類似,都建構了更適合架構本身的新興共識協議,Octra 建構了一個基於機器學習的共識協議 ML-consensus,其本質是基於 DAG(有向無環圖)的。
該共識的技術原理目前還未披露,但是我們可以大致的推測。大概就是交易被提交到網路中,然後使用 SVM(支援向量機)演算法來決定最佳的處理節點,主要是透過目前各節點的網路負載情況選擇。系統會基於歷史資料(ML 演算法學習)來判斷最好的父節點共識所達成的路徑。只要滿足 1/2 的節點就可以達成該不斷增長的資料庫的共識。
期待
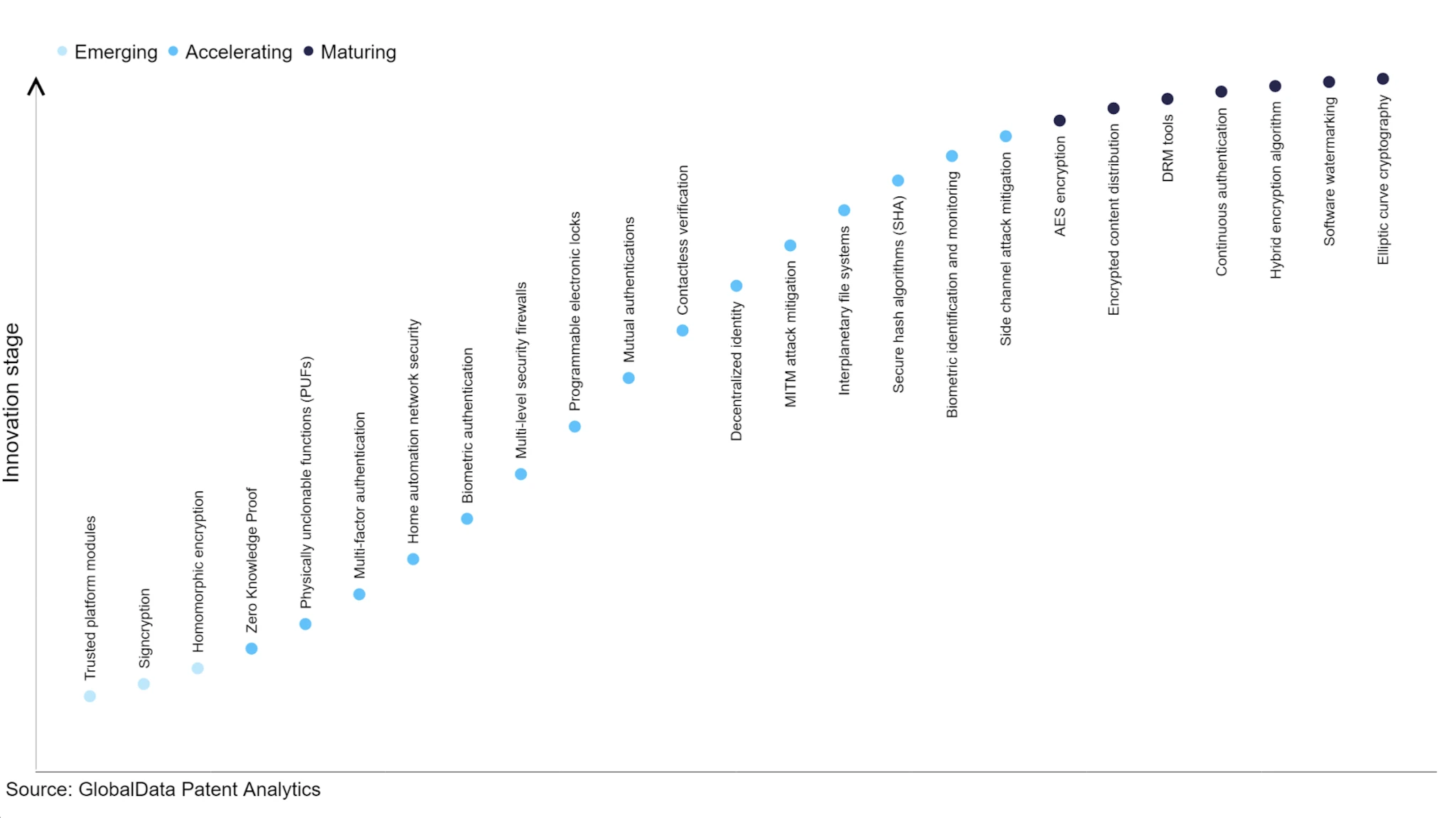
前沿密碼學技術發展現狀,圖源:Verdict
FHE 技術是一種面向未來的技術,其發展現狀仍然不及 ZK 技術,缺乏資本的投入,因為隱私保護帶來的低效率以及高成本對大部分商業機構來來說都動力不足。 ZK 技術的發展因為 Crypto VC 的投入變得更加快速。 FHE 仍然處於非常早期,即使是現在,市面上的項目仍然較少,因為其成本高昂、工程難度高、商業化落地前景仍然不明朗的等原因導致。 2021 年 DAPRA 聯合多家公司如 Intel、Microsoft 等開啟了長達 42 個月的 FHE 攻克計劃,雖然取得一定進展,但是距離實現的性能目標仍然較遠。隨著Crypto VC 對該方向的注意力到來,會有更多的資金湧入這個行業,預計業內會有更多的FHE 項目出現,也會有更多類似Zama、Octra 等具備很強工程與研究能力的團隊站在舞台中央,FHE 技術對於區塊鏈的商業化和發展現狀的結合仍然值得探索,目前應用較好的就是驗證節點投票的匿名化,但是應用範圍仍然狹小。
與 ZK 一樣,FHE 晶片的落地是 FHE 商業化落地前提之一,目前有多個廠商如 Intel、Chain Reaction、Optalysys 等在探索這一方面。即使FHE 面臨許多的技術阻力,但伴隨著FHE 晶片的落地,全同態加密作為一項極具前景和確切需求的技術,其對於如國防、金融、醫療等行業會帶來深刻的變革,釋放這些隱私資料與未來量子演算法等技術結合的潛力,也會迎來其爆發時刻。
我們願意探索這項早期的尖端技術,如果你正在打造真正得以商業化落地的 FHE 產品,或是有更具前沿眼光的技術創新,歡迎與我們接觸!












