





原文:《Web3视角下的AIGC算力进化论》
作者:宋嘉吉 孙爽
摘要
|
伴随着ChatGPT的爆红,AIGC(人工智能生成内容)产业链受到广泛关注。我们发现,同为算力,其与加密资产挖矿产业存在相似之处,均为投入算力和电力,获得经济回报,主要的不同点在产品端:AIGC产业链的产品是对用户提问而回应的内容,而加密资产挖矿的产品是加密资产。 同为算力“吞金兽”,短期比特币更耗电、长期AI算力增速快。同为算力生意,我们做了个有趣的研究,AIGC与BTC挖矿耗电量如何?按当前比特币全网算力319EH/S,每日耗电量约为2.2亿千瓦时;而OpenAI在训练、推理端的日均耗电量约2.6万千瓦时,约是前者的万分之一,但按OpenAI的预测,AI训练所需的算力每3-4个月翻倍,且考虑商业竞争算力增长速度预计将更快,“算力即权力”的时代将来临。中性预期下,ChatGPT日活稳定在1亿人次左右、ChatGPT每6个月模型参数翻倍、国际市场将出现10个左右类似于ChatGPT的商用大模型,而比特币挖矿耗电量保持当前状态,则大约4年后,AIGC大模型耗电量将超过比特币挖矿耗电量,乐观和悲观预期下,这一数字则分别为1.6年和7.5年。 算力的竞争性——产业自驱的结果。市场忽略了算力的竞争性,考虑商业因素,算力生意存在分子与分母端。对比特币挖矿而言,关于个体矿工能挖到的可用于变现的比特币数量,分子是个体的算力,分母是全网算力,个体矿工能挖得的比特币数量取决于其自身算力占全网算力的比例。而AIGC而言,关于个人内容生产者能获得的可用于变现的用户注意力,分子是个体算力驱动下的内容生产能力,分母是全网的内容膨胀速度,从UGC到AIGC的升维中,谁的内容生产力提升更快,谁就能获得更多商业利益,因此产业自驱之下,市场将追求更高的算力、更优的模型算法、更高功耗比的网络架构以及更便宜的电力。最终算力的需求规模将由应用定义。 寻找算力进化中的边际变化。当下难以预知未来多模态(图片、视频等)中到底会消耗多少算力,可当我们看到海外已然层出不穷的应用时,算力的增长只是时间问题,更重要的边际变化在于算力进化中在芯片、网络、连接等诸多领域有哪些创新方案?我们认为,在AIGC的推动下,更有利于新技术、新架构、新材料的落地应用,例如光连接中的CPO(光电共封装)、MPO(多纤连接器);芯片层面的Chiplet;网络架构层面的边缘计算等。 AIGC驱动算力产业版图生变。我们研究了过往加密资产领域的算力变迁,云服务与分布式早已应用(BTC云挖矿与Filecoin分布式存储),而今在AIGC的算力版图上亦同步发生。1)英伟达募资百亿进入AI云算力,其在GPU供给、算力复用度上占优,且将改变其商业模式;2)高通在AIoT领域布局终端算力,推理与内容生产端算力与存储的梯度分布(云—雾—端)。这些变化将驱动终端IT服务和硬件的升级。 投资建议:建议关注:1)算力侧:英伟达、微软、寒武纪、天孚、太辰光、锐捷网络、中兴、紫光、美格智能、新易盛、中际旭创、Chiplet产业链等;2)应用及IP:科大讯飞、汤姆猫、万兴科技、中文在线、昆仑万维、视觉中国、值得买等。 风险提示:AIGC技术发展不及预期,AIGC监管趋严。 |




1. 如何理解AIGC的算力生意?
伴随着ChatGPT的爆红,AIGC(人工智能生成内容)产业链受到市场广泛关注。算力,作为AIGC的基础,更被称为基石,近日英伟达在财报中的表述也佐证了这一点。市场一直在问:未来的算力需求到底有多大?我们发现现有的论述虽就GhatGPT的需求进行了推演,但未来AIGC必然走向多模态,其需求量和需求逻辑也将有所差异,算力的增长将大幅超预期,而理解这些的一切都建立在如何认识AI算力生意上。
过去我们讨论算力较多着眼于IDC,其商业逻辑着重于“数字地产”,即购买或租赁土地,投资建设机房并按机柜(或功耗)租赁给下游政企客户,从用途上兼顾“存”与“算”,但大部分一线城市以外的机柜都以“存”为主。AI算力则聚焦于“算”,在我们和国内外团队交流中,构建AI超算中心的资本开支核心在于GPU,这种高密度的计算未来将着重受限于两个指标:算力、功耗比。这与过往的“挖矿”市场在经济模型上有一定相似之处,研究这一特征有助于预测AIGC算力生意的未来走向。
1.1 算力经济模型:投入硬件和电力,获得经济回报
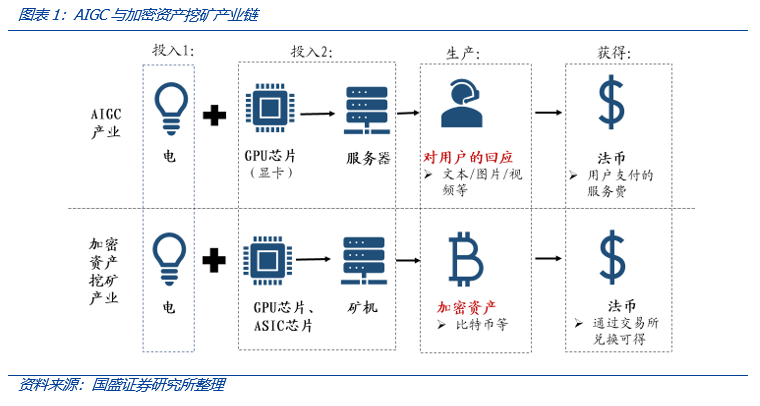
过去我们看到很多超算中心提供气象、交通、工业等领域的服务,但更多侧重于社会价值,而对AIGC或“挖矿”而言,都直接以经济回报为目的,投入产出要求更高。产业链方面,可以看出,AIGC产业链与加密资产挖矿存在若干相似之处。
- 成本主要是电费和算力投资,并且这两项费用主要取决于芯片本身的性能。其中,电费取决于芯片的功耗,而算力费用取决于芯片的算力水平和云计算费用。
- 目的都是为了获得经济回报。从OpenAI最近的合作及收费方式可以清晰看到其商业飞轮模型,正因为有了这样的反馈才能推动其快速发展。
1.2 对用户的内容生成,是AIGC产业链的产品
AIGC产业链与加密资产挖矿的不同之处在产品端,AIGC产业链的产品是对用户提问而回应的内容,而加密资产挖矿的产品是加密资产。具体看来,两大产业的不同包括:
成本端,
- AIGC:使用的的芯片主要是GPU(图形处理器/显卡);硬件之外,相较于加密资产挖矿,AIGC投入了更大规模、更昂贵的人力资源。例如,澎湃新闻称,为ChatGPT项目做出贡献的人员不足百人(共87人)。根据O’Reilly2021年6月的调查,OpenAI所在的加州数据和人工智能岗位的平均年薪为17.6万美元,假设OpenAI员工的平均年薪也与此相当,则OpenAI一年需付出1531万美元(约合1亿人民币)。
- 加密资产挖矿:使用的是ASIC(专用集成电路)和GPU(当前GPU因以太坊共识机制改变已经退出)。相较于GPU,ASIC芯片的针对性更强,只适用于各加密资产各自的算法。加密资产挖矿行业所需的专业人才主要是芯片设计人才和矿机运维人才,根据我们的了解,相较于前者,后者工资较低,而前者规模相较于重人力资本投入的AIGC产业明显更少,原因主要是加密资产挖矿(例如比特币矿机)芯片设计不需要类似于AIGC模型一般持续、大规模的人工调试和算法优化。
产品端,
- AIGC:产品是对用户提问的回答,形式包括文本、图片和视频等多模态输出,当前主要是前两种;
- 加密资产挖矿:产品是各加密资产系统为奖励矿工维护系统账本安全性,而发放的加密资产奖励,以及账本内交易中给矿工的手续费,例如比特币。
收入端,
- AIGC:会预先从客户处收取使用费,例如,ChatGPT高级版(Plus)的订阅费为每月20美元;同时对下游B端客户开放的API接口收费。
- 加密资产挖矿:需要将生产所得的加密资产,通过海外加密资产交易所等渠道兑现。
2 算力“吞金兽”:当前BTC耗电更大,而AIGC增速快
2.1 AIGC和比特币挖矿耗电量比较:当前比特币挖矿更耗电
由于AIGC算法和加密资产挖矿算法的不同,难以直接比较其参数,另外由于AIGC尚处于发展早期,年收入尚难估算,但我们找到了直接对比AIGC和比特币挖矿的一个直观指标:耗电量。
根据我们的计算,ChatGPT每日训练和推理的耗电量为25677千瓦时,是比特币挖矿日耗电量的万分之一(比特币挖矿为2.2亿千瓦时)。
此处我们使用的数据是:
比特币挖矿方面,
- 已知项:2023年2月28日,比特币全网算力为319(Ehash/s);
- 假设项:全网矿机一半为蚂蚁矿机S9(算力为14T hash/s,功耗为1400W),一半为蚂蚁矿机S19(算力为141T hash/s,功耗为3031.5W),其平均算力为78T hash/s,平均功耗为2216W。可以算出,按照前述全网算力,全网大约有412万台矿机。
AIGC方面,
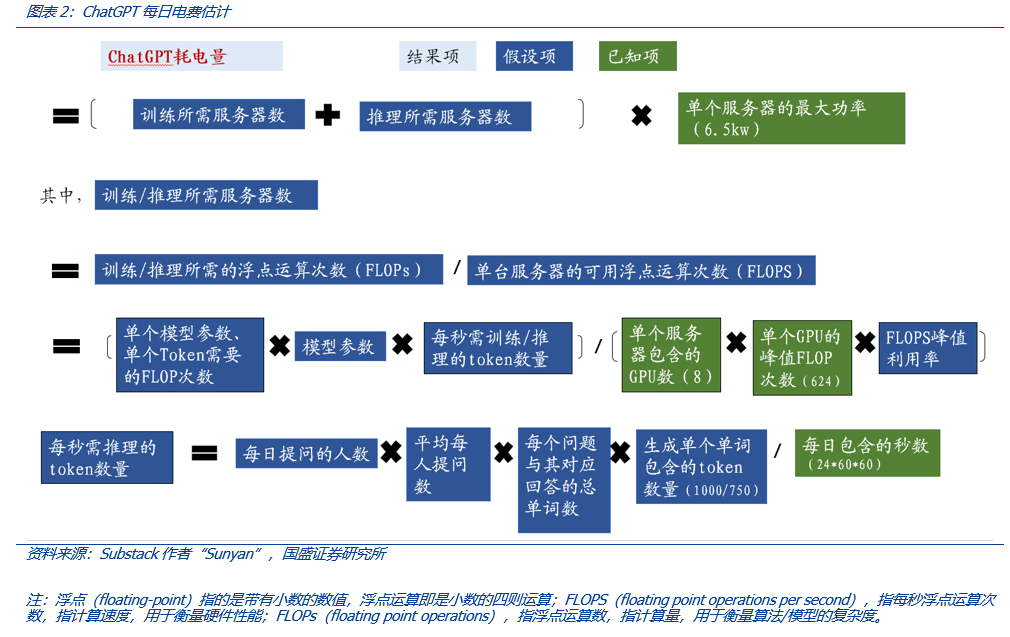
- 已知项:1)英伟达单个DGX A100服务器内含8个A100 GPU;2)单个英伟达A100 GPU的峰值浮点运算次数是624 TFLOPS(稀疏化后,指每秒可做10^12次浮点运算);3)单个英伟达DGX A100服务器的最大功率是6.5千瓦;4)ChatGPT前身——GPT3的模型参数量是1750亿个、训练的标识符(token)数是3000亿个。
- 假设项:1)ChatGPT模型参数是3000亿个,推理时可以通过蒸馏等技术仅使用300亿个参数;2)单个模型参数、单个标识符训练时所需的浮点运算次数为6N,推理时为2N,其中N为模型参数,单位为FLOPs;3)单个服务器训练时的峰值利用率为46.2%,推理时为21.3%,与GPT3保持一致;4)训练用标识符数量为5000亿个;5)关于推理时用的标识符数量,假设根据Similarweb统计,截至2023年2月21日的28日chat.openai.com的每日访问人数均值为28696429,此处简化为3000万人,平均每人提出10个问题,每个提问含50个单词,ChatGPT为单个提问生成5个回答,每个回答包含100个单词,每1000个单词对应750个标识符;6)假设ChatGPT每个月训练十次,每个月有三十天。可以算出,ChatGPT每次训练需要1506个英伟达DGX A100服务器,每日推理需要144个,相当于13194个A100 GPU。
ChatGPT之外,我们也注意到其他AIGC文本服务和多模态领域对算力和电量的海量需求。
大语言模型训练成本高昂。参考Substack作者“Sunyan”的测算,模型参数为2800亿个Gopher(Google DeepMind)的训练成本为200万美元;模型参数为5300亿的MT-NLG(Microsoft/Nvidia)的训练成本为400万美元;模型参数为5400亿的PaLM(Google Reasearch)的训练成本为1100万美元。根据《财富》杂志,在尚未收费的2022年,OpenAI该年度净亏损即高达5.445亿美元(不含员工股票期权),我们预计其中算力成本占据了重要位置。
图片
生成图片所需的算力取决于多个因素,例如生成图片的分辨率、所使用的算法、训练数据集的大小和质量,以及使用的硬件等。
Stable Diffusion
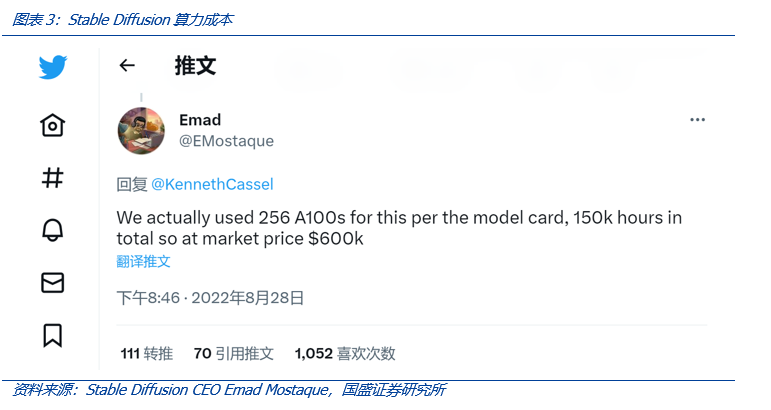
- 根据Stability AI 的创始人兼首席执行官 Emad Mostaque,Stable Diffusion使用了256张 Nvidia A100训练,所有显卡总计耗时 15 万小时,成本约为 60 万美元。
- 根据Business Insider 2022年10月的报道,Stable AI的运营和云计算成本超过5000 万美元。当月,Stability AI完成了1亿美元融资,投后估值10亿美元,为AI训练助力。
Dall-E
根据《Zero-Shot Text-to-Image Generation》,OpenAI在Dall-E的整个训练中,共使用了 1024 块 16GB 的 NVIDIA V100 GPU。团队从网上收集了一个包含 2.5 亿个图像文本对的数据集,在这一数据集上训练一个包含 120 亿个参数的自回归 Transformer。
另外,论文介绍道,用于图像重建部分的dVAE模型的训练,共用了 64 块 16GB 的 NVIDIA V100 GPU,判别模型 CLIP 则共使用 256 块 GPU 训练了 14 天。
视频
生成视频所需的算力和存储空间比生成单张图片更高,因为生成视频需要在时间维度上连续地生成,而视频中的每一帧都需要根据前一帧生成。
因此,生成视频所需的算力取决于多个因素,包括视频分辨率、帧率、视频长度、所使用的算法和训练数据集的大小和质量。使用GPU可以显著加速训练,但是在生成高分辨率视频时,可能需要使用多个GPU和分布式计算来加速训练。
近期我们尝试定制了2D仿真数字人,在每次内容生产时就是将语音和文本内容添加到已经构建好的人物模型中(数字人模型),在后台通过GPU生成短视频,其生成速度与GPU规模密切相关。对于创业企业而言,未来的定价就是基于算力成本,用户也是购买算力时长后自由使用。
2.2 未来,AIGC耗电量或将超越比特币挖矿
这个问题在近期的交流中常被问及,海外有一系列的论文对此算力进行了测算,但我们认为更重要的各类应用涌现、商业竞争加剧带来的算力“军备竞赛”是非线性的,算力与应用之间会形成正反馈。
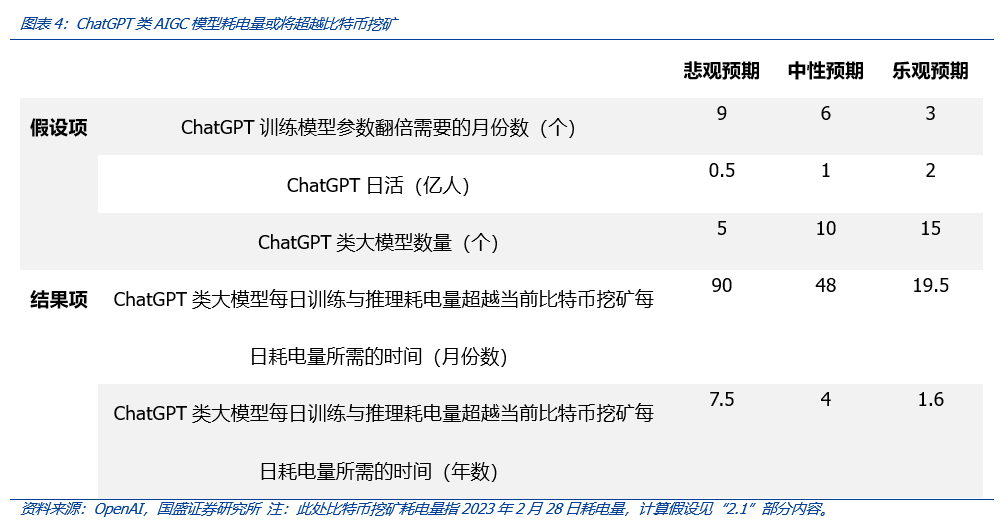
考虑到ChatGPT的日活还在不断增长、国际AIGC服务的竞争还在不断加深,我们预计,不考虑模型效率提升对算力需求的下降,也不考虑模型训练的标识符(token)的增长,中性预期下,ChatGPT日活稳定在1亿人次左右、ChatGPT每3个月模型参数翻倍、同时假设全球市场将出现10个左右类似于ChatGPT的商用大模型,而比特币挖矿耗电量保持当前状态,则大约4年后,AIGC大模型耗电量将超过比特币挖矿耗电量。乐观和悲观预期下,这一数字则分别为1.6年和7.5年。注意,此时我们只是考虑了类似于ChatGPT的商用大模型,而实际可能出现可能消耗更多算力的多模态商用大模型,如果考虑到这一点,AIGC耗电量的增长将会更快。
3 算力的竞争性——不容忽视的产业自驱结果
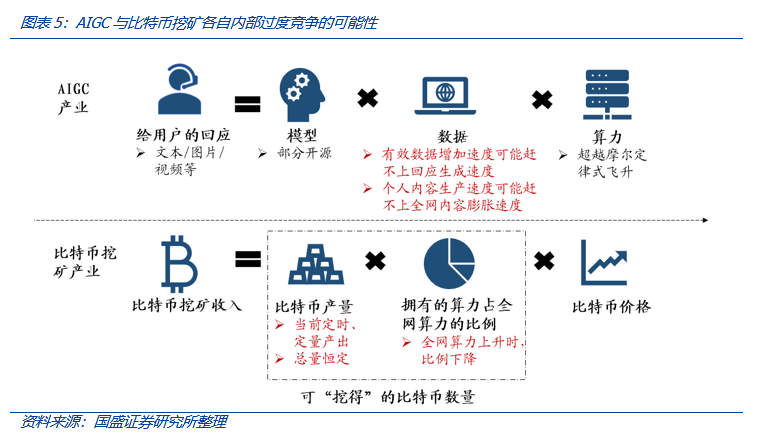
很多时候,算力的投入并不是独立的,而需要和全网总量竞争。我们认为,AIGC产业和加密资产挖矿中的比特币挖矿,都存在内部过度竞争的可能性。对于比特币而言,算力竞赛的目的是要占据更多的全网算力比重,从而提高获得奖励的可能性;对于AIGC而言,在内容创作领域,需要保证自身的内容生产速度快于行业平均,尤其是在短视频、游戏等相对重度的领域中。
3.1 比特币挖矿的内化竞争
3.1.1 “产量”恒定,全网算力越多,自身获益越少
比特币全网每10分钟出一个“区块”,成功“挖掘”出该“区块”的矿工会获得系统发行的比特币奖励和该区块内所有交易的手续费(前者占主要部分),当前的出块奖励是6.25个比特币(起初是50个,奖励数每四年减半,即“50→25→12.5→6.25→……”)。
根据这些限制条件,比特币的“产量”总量恒定(约为2100万),在出块奖励未改变的每四年内也保持了相对恒定(如当前每天几乎是900个),而矿工能挖得的比特币数量取决于其自身算力占全网算力的比例。当其他矿工认为当前挖矿性价比较高而将算力投入挖矿,则单个矿工自身算力占全网算力的比例下降,此时如果比特币价格没有出现明显上升,则该矿工的比特币挖矿收入和利润出现下降,这就是比特币挖矿内部过度竞争的逻辑。
3.1.2 内部过度竞争的出现有前提
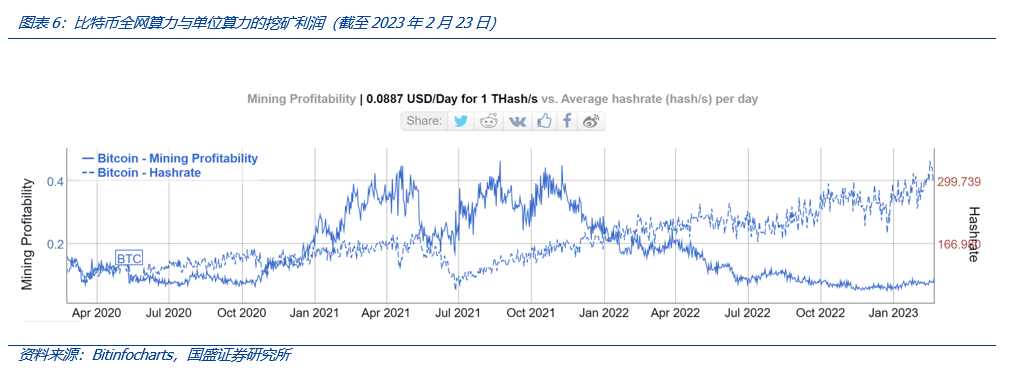
需要注意到,比特币挖矿出现内部过度竞争存在若干前提,实际情况中,内部过度竞争并非一定会出现。根据Bitinfocharts统计,截至2023年2月23日的三年以来,比特币全网算力呈现平稳上升趋势,而与此同时,单位算力的挖矿利润呈现平稳下降趋势,这呈现出一定的“内部过度竞争”特征。一个重要原因是,比特币价格在此期间呈“横盘震荡”状态。
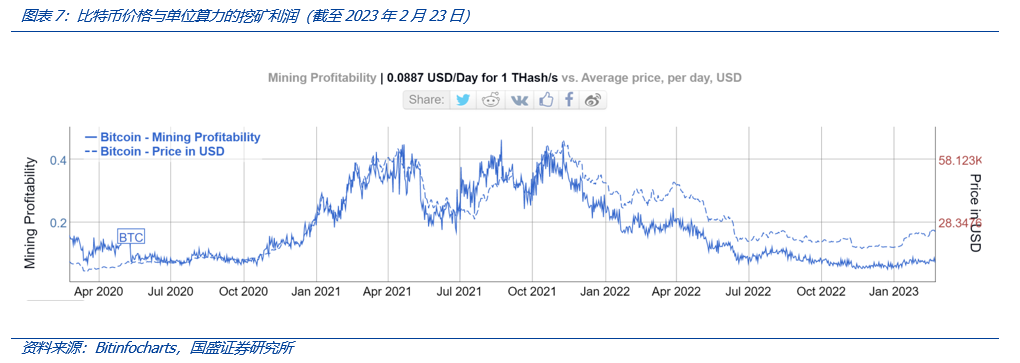
从趋势上看,比特币挖矿单位算力挖矿利润与比特币价格更为相关,当比特币价格上升,前者即能出现较为明显的上升态势。这在一定程度上意味着,打破矿工之间在算力和可挖得比特币“数量”上的内部过度竞争,获得更多比特币挖矿收入和利润,需要比特币“价格”因素发力。
3.2 AIGC算力的外化竞争
3.2.1 需求端:刚被点燃,放量在即
创新应用往往是供给引导需求。当前,AIGC正走向多模态,各种服务已经逐步实现商业化,用户需求刚被供给端点燃,从最新的增长情况看,放量在即。
AIGC文字服务ChatGPT
- 高级版(Plus)订阅服务每月费用为20美元/账户。Ø AIGC图片服务Stable Diffusion
- Stability AI推出了基于Stable Diffusion的图片AIGC平台和API DreamStudio。DreamStudio会根据用户对图片像素和操作步骤的需求收费,每张图片消耗0.2-8.2个积分。新注册用户可以免费获得200个积分,此后每100积分消耗1英镑,默认设置生产4 张512 * 512 的图消耗0.8 个积分。
- 此外,公司还对企业客户提供定制化服务。
- 截至2022年10月,DreamStudio拥有超过150万用户,创建了超过1.7 亿张图像,而Stable Diffusion全渠道的用户数量每天超过1000万。
AIGC图片服务Dall-E
- 定价是15美元生成115次。每次生成请求会返回 3~4 张 1024*1204 尺寸的结果图片,每次耗费 0.13 美元。
- 2022年7月,OpenAI正式宣布DALL-E 准备向100 万个用户开放测试版,第一个月,用户有50个免费积分,以后每个月有15个免费积分。
- 根据OpenAI,截至2022年11 月3 日,已经有超过300 万人使用DALL·E 2,每天创建的图片数量达到400 万张。
AIGC图片服务Midjourney
- 按月订阅收费,个人用户有每月 10 美元和 30 美元两档,分别对应 200 和 900 次标准生成或放大请求(1 次标准生成请求对应 1 GPU 分钟,在 fast 模式下。每次生成会获得四张 256*256 的初始结果,用户可以选择放大,每次放大也耗费 1 GPU 分钟);
- 超过限额后,每 60 GPU 分钟售价 4 美元。但使用这两档订阅服务,用户的提示词和结果图片都将暴露在公共空间,此时再付出 20 美元可享有私密服务通道。
- B端每年费用为600美元。
- 截至2022年11月,Midjourney在Discord服务器中已累计有超300万用户。
3.2.2 供给端:算力和数据快速进化,模型获开源赋能
我们认为,如果“需求横盘震荡或下滑”前提不存在,则AIGC并不会陷入内部过度竞争状态。目前看来,业内公认的AIGC大语言模型(LLM)的三个关键因素都在快速飞升,但一旦AIGC内部过度竞争出现,“数据”和“算力”可能最先,“模型”则可能次之,部分模型的开源能为其带来长久活力。
算力:六年来增长了182倍
- 摩尔定律中,集成电路上可容纳的元器件的数目,约每隔 18-24 个月便会增加一倍,性能也将提升一倍。
- 继摩尔定律后,英伟达 CEO 黄仁勋提出黄氏定律:每 12 个月 GPU 性能翻一倍,且不受物理制程约束。
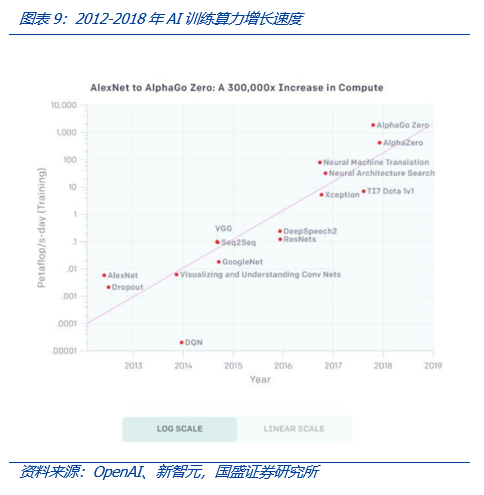
- 根据OpenAI测算,自2012年至2018年,用于训练AI所需要的算力大约每隔3-4个月翻倍,总共增长了30万倍(而摩尔定律在相同时间只有7倍的增长),每年头部训练模型所需算力增长幅度高达 10 倍,整体呈现指数级上涨。
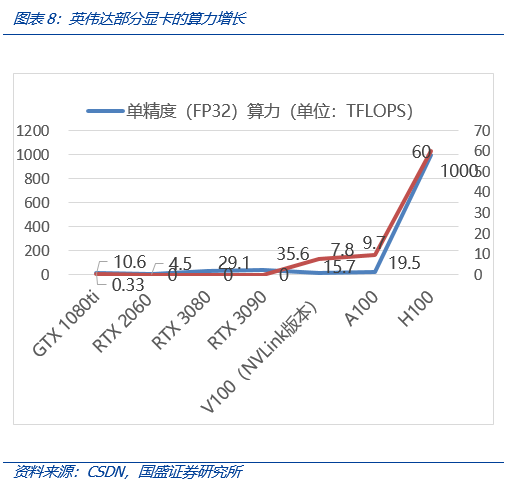
- 我们统计了部分英伟达有代表性的显卡,发现2017年以来,2022年4月面世的H100较2017年3月推出的GTX 1080ti,在单精度(FP32)上,是后者的94倍(1000/10.6),在AIGC常用的双精度(FP64)算力上,是后者的182倍(60/0.33)。
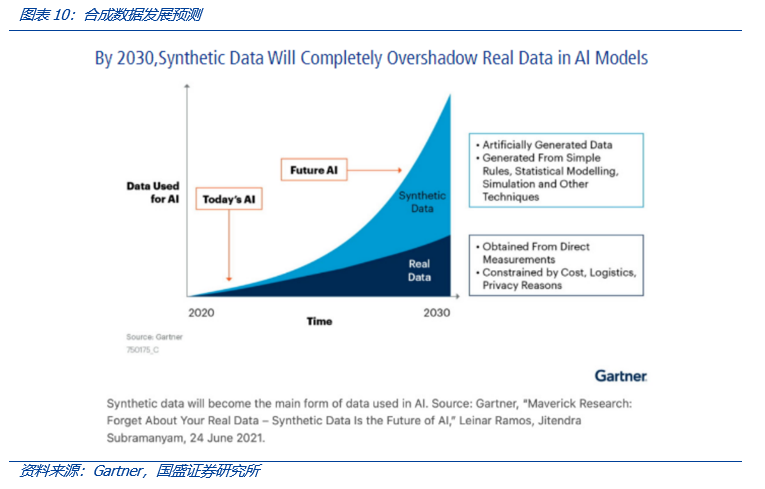
- 数据:当前互联网数据将耗尽,合成数据将成主流
输入端
合成数据,不基于任何现实现象或事件的数据组成,而通过计算机程序生成。AIGC生成的数据是合成数据生产的重要方式。Gartner预测,
- 到2024年用于训练AI的数据中有60%将是合成数据;
- 到2025年,AIGC生成的数据将占所有合成数据的10%,而目前这一比例还不到1%。
- 到2030年AI模型使用的绝大部分数据将是人工智能合成的。
这一方面体现出市场对合成数据的看好,另外一方面,我们认为,这反应出市场当前互联网公开数据可能存在被AI模型“耗尽”的担忧。
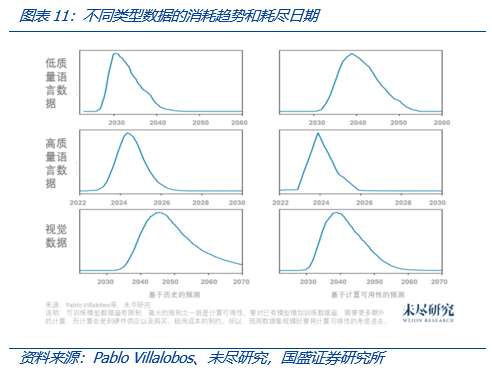
根据未尽研究的梳理,阿伯丁大学、麻省理工大学、图宾根大学的Pablo Villalobos等6位计算机科学家在论文《我们会用完数据吗?机器学习中数据集缩放的局限性分析》中预计,
- 对于语言模型来说,耗尽当前互联网数据的情况将在2030年到2040年之间发生;
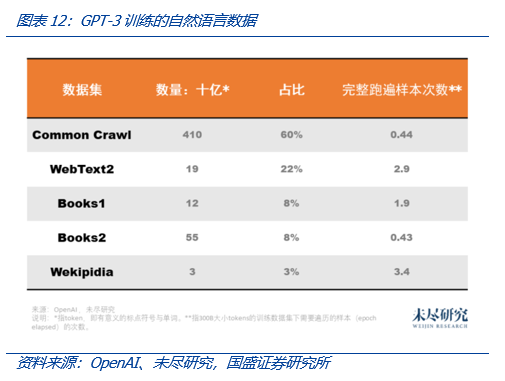
- AIGC文本训练使用的是高质量数据集,它通常包括50%的用户生成内容,15%~20%的书籍,10%~20%的科学论文,近10%的代码和近10%的新闻;
- 假设数字化书籍、公共GitHub和科学论文中可用文本的全部数量占高质量数据集的30%到50%之间,当前高质量语言数据的总存量为9万亿(即9e12,上下限大概为4.6万亿到17万亿)个单词,每年增长率为 4% 到 5%。以高质量语言数据库作为上限来预测语言数据集的增长,放缓发生得更早,在2026年之前。
根据上述论文《我们会用完数据吗?机器学习中数据集缩放的局限性分析》,现在互联网上的存量视觉数据数量在8.1万亿到23万亿之间,目前的年增长率在8%左右,视觉模型数据耗尽的情况将在2030年到2060年之间发生。相较文本数据,视觉数据对AI训练而言,耗尽的时间较为靠后。不过根据IDEA研究院计算机视觉与机器人研究中心讲席科学家张磊博士的观点,将视觉数据用于AI训练,还存在“大模型学到的全图表征用于细粒度问题会性能递减”“视觉算法方面尚需进一步改进”“视觉大模型目前还没有达到单纯增加数据提高效果的阶段”等问题。
输出/产品端
除了“输入”内容/数据的快速进化,我们还需要考虑的是,在AIGC“输出”的内容/数据方面,当未来AIGC的使用越来越普及的时候,互联网内容竞争的格局会有怎样的变化?
在过去的十年中,抖音、小红书等平台大幅降低了内容创作、分享的壁垒,UGC模式的内容丰富程度和规模远超过往。而当前无论是带货直播还是内容创作,门槛均比之前有所提高,UGC也“卷”了起来。
而当AIGC来临时,内容竞争又将升维,例如数字虚拟人将实现包括外形、声纹、对话内容的模拟,或许看到的很多内容将是AI生成,作为个体需要保证自身的内容生产、进化速度快于行业均值,背后的算力投入将首当其冲,否则将直接影响账号盈利能力。
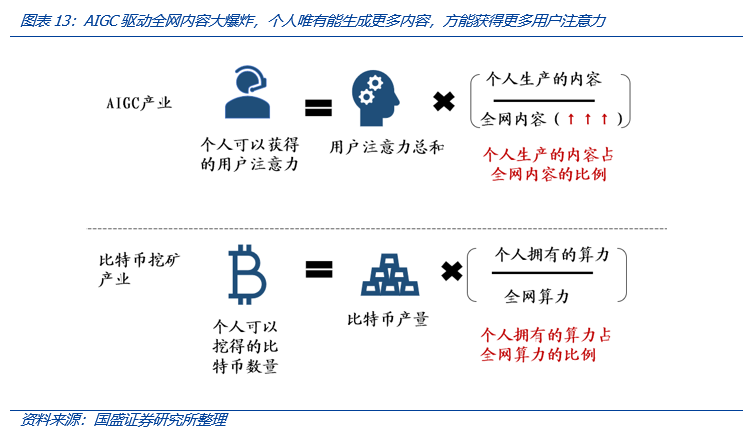
我们认为,市场忽略了算力的竞争性,考虑商业因素,算力生意存在分子与分母端。对比特币挖矿而言,其分子是个体的算力,分母是全网算力,个体矿工能挖得的比特币数量取决于其自身算力占全网算力的比例。而对AIGC而言,其能获得的用户注意力的分子是个体算力驱动下的内容生产能力,分母是全网的内容膨胀速度。从UGC到AIGC的升维中,谁的内容生产力提升更快,谁就能获得更多商业利益,因此产业自驱之下,市场将追求更高的算力、更优的模型算法、更高功耗比的网络架构以及更便宜的电力。
模型:参数迅速堆叠
2017年以来,AIGC模型的参数量逐年增加,从,2021年以来,这一趋势呈现出明显加快的状态,从ELMo的9400万个参数一路飙升,至2020年年中,GPT-3引领行业走入千亿参数时代,参数达1750亿个,截至2021年年中,英伟达大语言模型MT-NLG更是超过了5300亿。

底层的大模型具有明显的头部效应,在算力、投资、数据上形成了正反馈,可以预见,竞争之下,大模型会不断集中。而基于大模型开发的垂直应用将层出不穷,正如我们在上篇报告中所说,大模型的“通识化”将是未来AI快速迭代的基础。
4 AIGC算力进化的边际变化
当下难以预知未来多模态(图片、视频等)中到底会消耗多少算力,可当我们看到海外已然层出不穷的应用时,算力的增长只是时间问题,更重要的边际变化在于算力进化中在芯片、网络、连接等诸多领域有哪些创新方案?
我们认为,在AIGC的推动下,更有利于新技术、新架构、新材料的落地应用,例如光连接中的CPO(光电共封装)、MPO(多纤连接器);芯片层面的Chiplet;网络架构层面的边缘计算等。
4.1 提升超算通信效率,高密度光连接成首选
大规模超算集群,通信效率直接影响训练效率。大模型训练需要超算集群持续运算数月时间,需调用数千片GPU运算海量数据,GPU与GPU间、服务器与服务器节点之间存在海量内部数据交互需求,根据木桶效应,只要有一条链路出现负载不均导致网络堵塞,成为木桶短板,则其他链路即使畅通无阻,集合通信时间仍然会大幅度增长,进而直接影响训练效率。集群训练会引入额外的通信开销,从而导致N个GPU算力达不到单个GPU算力的N倍。因此,高性能网络互联,是大规模GPU集群所必须的。
提升超算通信效率,高密度光连接成为首选。超算除了需要高密度光传输端口外,端口和端口间主要以光纤连接器来实现光互联,多采用MTP/MPO高密度光纤连接器实现连接。其中MPO是光纤连接器,主要用途是用以实现光纤的接续,MPO会直接影响光传输系统的可靠性等各项性能。数据中心的内部光学连接需要借助光模块和光纤连接器来实现。因超算集群内部节点之间对于高效率高速互联的硬性需求,光端口密度的进一步提升,并且综合光纤连接器走线连接的可实施性和可维护性,我们预计超算集群对于高密度光纤连接器的需求量较传统云数据中心有较大幅度的提升,而随着全球科技聚焦大模型AI训练,相应超算投入将确定性增长,高密度光连接将确定性受益。
4.2 基于功耗考虑,CPO方案渗透率有望逐步提升
AI大背景下,未来基于功耗考虑,CPO方案渗透率有望逐步提升。CPO方案通过光电耦合共封装在插槽或PCB上,加上液冷板降温控制功耗,有望成为AI高算力下高能效比方案。但CPO在降低功耗的同时也有一些隐患,主要是光电共封装后,光引擎焊接在同一插槽上不可更换。如果光纤或者光引擎出现损坏,可能会影响整个CPO交换ASIC基板,对交换机生产的总体成本会产生负面影响。
从CPO方案看MPO的变化。CPO交换机内部带来的变化一个是光纤数量增多,一个是交换机内部布线复杂度提升。一个51.2T的交换机按单口100G来估算将达到512通道,对应1024根光纤。对应如果是16芯的MPO需要64根,对应64个端口。
光纤和MPO用量提升后,同时又由于CPO方案拉近了光引擎和ASIC的距离来降低线上损耗,就导致光纤布线要从原来的机箱外部延伸到内部接到光引擎,等于额外增加了光引擎到交换机机箱前面板的布线。内部光纤路由复杂程度提高。
中间板/板载光互连或成布线解决方案,降低CPO出错成本。因为CPO下每个光引擎到面板距离不同,导致尾纤长度有差异,且布线复杂易损坏光纤影响整机。考虑在光引擎和端口面板间增加板中连接器,固定尾纤长度,降低布线复杂度。将CPO的试错成本转移到板中连接器和端口的MPO上。简而言之,通过增加连接来降低布线复杂度和出错的成本。
海外AIGC/ChatGPT持续扩散,带宽密度有望大幅上行。在未来算力/带宽高增的背景下,以及CPO的新方案拉动下,MPO的用量有望大幅提升,在设备内部重要性也逐步提高。
5 AIGC驱动算力产业版图生变
5.1 云化:算力服务商与云厂商走向历史性合作
当算力竞争加剧,“降本增效”将成为企业的生存关键,通过投资、并购,与上、游合作,将成本“内化”是一条可选路径。我们注意到,当前已有AIGC企业选择“投靠”云服务厂商,例如OpenAI与微软Azure云的合作;也有算力厂商开始了对AI模型的研发,例如英伟达大语言模型NeMo和NVIDIA BioNeMo LLM 服务。
其中,OpenAI与微软Azure云的合作具有一定程度的示范效应,它通过深刻利益绑定,我们推测,这种合作能降低OpenAI训练AI所需的云计算成本。
根据《财富》杂志报道,在OpenAI的第一批投资者收回初始资本后,微软将有权获得OpenAI 75%利润,直到微软收回投资成本(130亿美元);
当OpenAI实现920亿美元的利润后,微软的份额将降至49%。与此同时,其他风险投资者和OpenAI的员工,也将有权获得OpenAI 49%的利润,直到他们赚取约1500亿美元。
如果达到这些上限,微软和投资者的股份将归还给OpenAI非营利基金会。
除了利润回报,微软微软在整合ChatGPT等方面也占尽了先机。除了将搜索引擎Bing整合ChatGPT,2023年1月,微软宣布推出Azure OpenAI服务,Azure 全球版企业客户可以在云平台上直接调用OpenAI模型,包括 GPT-3.5、Codex 和 DALL.E 模型。
英伟达向SEC提交百亿增发申请,全球算力龙头启动战备。2月28日,英伟达向美国证券交易委员会(SEC)提交近百亿美元的股票增发申请,此次增发申请通过储驾发现模式进行,可在三年内自主决定发行证券的具体时机。英伟达作为全球算力龙头,在本轮chatgpt带动的大模型发展,科技巨头跑步进场,AI算力底层基础设施迎确定性爆发,英伟达在此前财报会议上表示将与头部云服务商合作,提供AI即服务,帮助企业访问英伟达世界领先的AI平台,本次融资或代表全球算力龙头英伟达拉开了算力竞备序幕。
根据福布斯中国的梳理,客户使用自己的浏览器,就可以通过 NVIDIA DGX Cloud 来使用 NVIDIA DGX AI 超级计算机,该服务已经在Oracle Cloud Infrastructure上可用,预计不久后也将在微软Azure、谷歌云和其他平台上线。在AI平台软件层,客户将能够访问NVIDIA AI Enterprise,以训练和部署大型语言模型或其他 AI 工作负载。而在AI模型即服务层,英伟达将向希望为其业务建立专有生成式AI模型和服务的企业客户提供NeMo和BioNeMo可定制AI模型。
无独有偶,AI产业算力服务商与云厂商的历史性合作,加密资产挖矿领域早已应用。例如,加密资产矿机厂商比特大陆一度推出云算力服务平台“比特小鹿”,用户无需购买矿机硬件,也可以购入挖矿算力,获得挖矿收入。这一举措,通过“化整为零”的方式,对用户/AIGC需求厂商而言,能最大化降低入局挖矿门槛,驱动全民挖矿/AIGC时代降临;对矿机/算力厂商而言,在矿机/芯片进入淡季、矿机/芯片库存趋增时,能通过售卖云算力的方式,平滑收入的波动;对云服务厂商而言,则有助于增加客流。
5.2 推理边缘化:边缘算力有望成为推理主体
高通发布在Android手机上部署AI模型的解决方案。3月2日,高通中国公众号发布了全球首个运行在Android手机上的Stable Diffusion终端侧演示。高通AI部门演示了如何利用高通AI软件栈,首次在Android智能手机部署Stable Diffusion模型。该模型是一个用文字生产图片的AI模型,参数超过10亿,过去只能在云端计算集群内运行。
边缘算力有望成为推理主体。在本次实验中,高通AI团队从Hugging Face的FP32 1-5版本开源模型入手,通过量化、编译和硬件加速进行优化,使其能在搭载第二代骁龙8移动平台的手机上运行。我们认为,未来AI的推理过程,通过一定的针对性优化后,完全有能力通过边缘算力实施。同时,边缘算力具有低时延、安全、隐私等优势,符合未来AIGC时代,对于AI创作所有权和隐私权的要求。手机,智能模组等算力相对于云端访问,对于普通用户来说更加便捷和易于学习,对于AIGC应用的推广也更加有利。
边缘算力是未来算力体系的重要一环。当前,无论是需要超强硬件支撑的AI迭代与训练,还是运行要求相对较低,需求相对分散的AI推理,都放在超算中心内进行。我们认为,在AI大爆发周期内,迭代和训练需要的整体算力将会呈指数级增长,增速将会超过单芯片算力增长速度。同时,单个AI超算规模将会受到功耗、土地、散热等因素制约。因此,未来的AI运算将呈现出训练与迭代在云端,推理与内容生产梯度分布(云侧+雾侧+边缘侧)的格局变化。此外,随着AIGC内容愈发丰富,从简单的文字发展到视频、虚拟场景,如果采用云生成然后发送到端的形式,将会产生较多的网络带宽成本和一定程度的时延,进而影响模型的商业化进程与用户使用体验,边缘算力有助于作为补充手段改善这一情形。
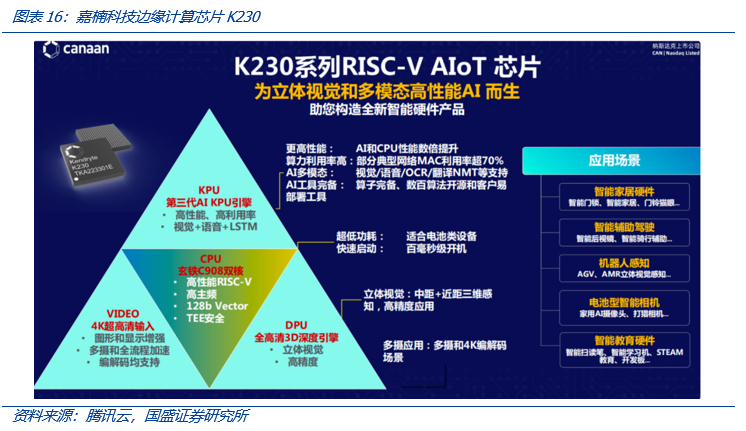
我们注意到,比特币矿机厂商嘉楠科技推出了自研的边缘AI芯片,其董事长张楠赓在一次公开发言中表示,未来会有更多计算发生在边缘侧或者端侧。2022年11月,嘉楠科技宣布即将推出为立体视觉和高性能AI而生的端侧RISC-V AIoT芯片 K230。值得一提的是,嘉楠科技作为比特币矿机厂商,是首个交付全球7nm ASIC芯片的企业,2016年启动AI人工智能芯片研发,2018年发布了全球首款基于RISC-V的AI芯片。嘉楠科技的布局,也体现出AI算力和加密资产算力在商业模式等层面的一种共通性。
投资建议
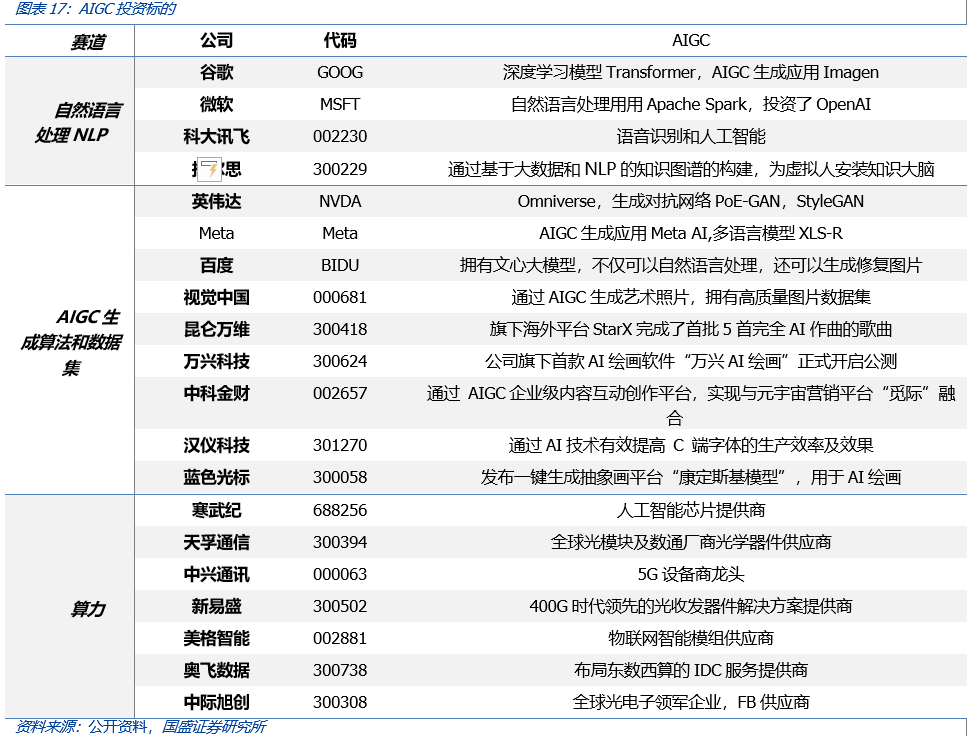
综上所述,算力、数据和场景是当下A股的主要投资方向。算力层面,我们认为硬件开销的规模由应用决定,在AIGC赋能千行百业的情况下,着重于跟踪应用端的边际变化。AI硬件仍以英伟达GPU产业链为主;在能耗、电费因素的影响下,东数西算的重要性将强化,新疆、内蒙古、云南、四川、贵州、西藏等火电、水电、太阳能资源丰富的省份将成为AI大规模训练、应用的优势区域。目前国内的AIGC竞赛刚刚开始,预计将首先出现英伟达A100需求的趋紧,随着规模增加,能耗问题也将凸显。
同时,我们看到国内大量拥有用户、IP的应用型企业也在跃跃欲试,本身对于文字创作、广告、游戏等赛道而言,“备战AIGC”将成为当务之急。一方面,其缺乏大模型能力,必须选择与OpenAI或百度等企业的合作;另一方面,其手中有大量的细分场景和付费群体,也是大模型企业期待落地的合作伙伴。我们认为,如能在场景应用、合规等方面做好自己的“小模型”,亦有望在AIGC时代脱颖而出。
风险提示
AIGC技术发展不及预期。虽然AIGC产业的技术在飞速迭代中,但可能遇到阻滞。
AIGC监管趋严。AIGC产业可能在内容创作、数据使用等方面迎来严格监管。
本文节选自国盛证券研究所已于2023年3月19日发布的报告《Web3视角下的AIGC算力进化论》,具体内容请详见相关报告。







 APP
APP 

