如果说元宇宙是“数字化”的终极形态,那动捕技术则是实现人“数字化”的关键一步。

在影视制作中,动作捕捉是最常用到的一项技术。无论是《阿凡达》还是《指环王》里的咕噜,都是先利用动作捕捉采集演员的肢体表演,再将捕捉到的动作渲染处理后,才呈现出震撼的视觉效果。
游戏行业也是动捕技术的核心应用场景。游戏动画中包含很多复杂的姿势动作,通过采集真人演员的动作数据,绑定到游戏角色的骨骼上,可以最大程度地还原人体真实的姿态、表情、重量和速度,从而让玩家能够体验到更加真实的游戏世界。
随着“元宇宙”概念的全面普及,动作捕捉对元宇宙的长期价值也逐渐显现出来,它和引擎、传输、计算和显示等技术处于同一级别,是元宇宙底层建设这块“巨大拼图”中的重要一块。
动捕技术发展历程
类似动作捕捉的技术最早出现在1915年,当时的动画大师 Max Fleischer 制作了一台放映机,原理就是把胶片的内容显示到透光台上。凭借着这台放映机,动画师可以很方便地照着画面中人物的动作造型,来绘制角色动作。
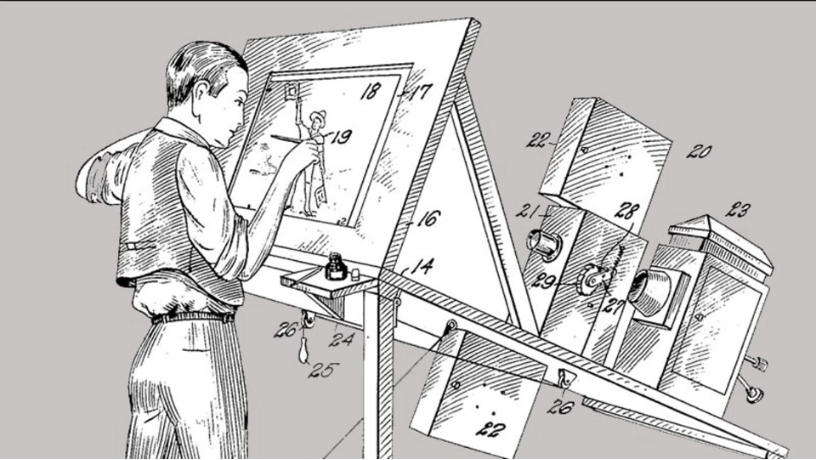
图 | 绘画放映机
1983年,加拿大思蒙弗雷泽大学的Tom Calvert在物理机械捕捉服装上取得的重大突破,这一技术让人们见识到了最早的机械类捕捉。与此同时,麻省理工也推出了一套基于LED的“木偶图像化(graphical marionetter)”系统,这就是早期光学动捕系统的雏形。
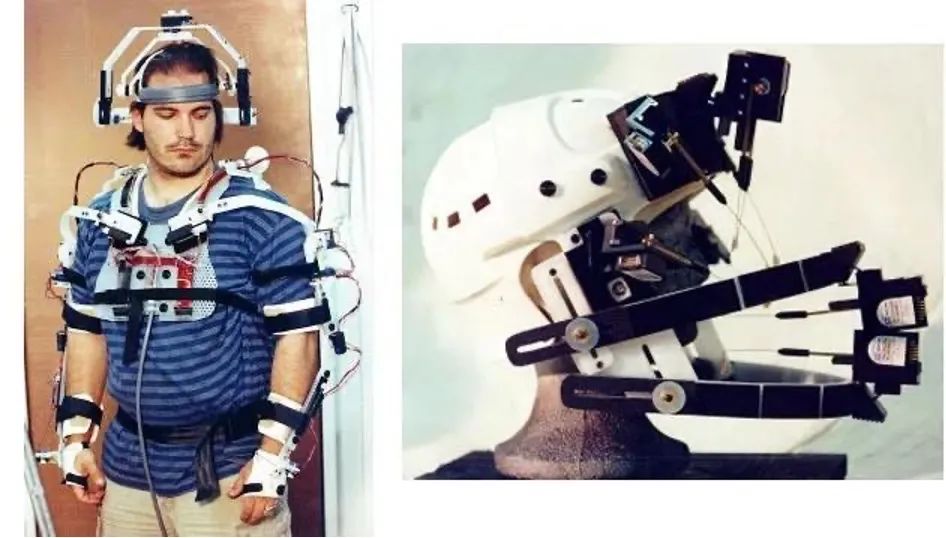
图 | Tom Calvert研究成果
此番生物力学研究为未来的影片制作铺平了道路,在接下来的时间里,当动作捕捉与计算机图形技术相遇,动作数据的易得性使动作捕捉技术快速发展,并相继被完整、大规模地运用到游戏与电影行业。
90年末,电影《指环王》的拍摄则第一次将动捕拍摄步骤带到了拍摄现场,动捕演员先驱Andy Serkis在场地中可以作为“咕噜”这一角色和其他演员进行互动,这样的互动更加有利于角色的塑造,因为只有当演员在表演过程中获得了其他演员的情绪和语言反馈,自身情绪才能更酣畅地被释放,角色才能更加有血有肉、活灵活现。

图 | 电影《指环王》动作捕捉剧照
2009年上映的电影《阿凡达》可以说是将动作捕捉与表情捕捉技术成功结合的先驱者。导演James Cameron与团队使用了头戴式面部捕捉相机,并建立了有史以来最大的拍摄与动作捕捉影棚。

图 | 电影《阿凡达》动作捕捉剧照
特效影视制作和游戏从来是不分家的,很快有人把动作捕捉的概念带到了游戏圈。在这个领域最具有先锋意识的是当时在主机领域与任天堂、索尼三分天下的世嘉。
它1994年推出的街机游戏《VR战士》就使用了动作捕捉模拟人物行动。这种新概念在当时粗糙的街机和家用机游戏市场成为一股清流,用逼真流畅的动作吓呆了一众玩家。隔年,南梦宫也推出了《刀魂》,作为自家动作捕捉技术的先锋军,也取得了成功。
如今,动作捕捉几乎成为大型游戏工作室标配,利用动捕技术,真人和动画人物是同步的,游戏角色会显得更加真实、生动。这就是为什么我们可以在游戏中看到电影级水平的动作表演。
常见的动捕技术
随着技术的成熟,现在动作捕捉技术应用的领域也越来越广泛了,从动画制作、人机交互、到机器人遥控、体育训练等等,甚至现在的虚拟人直播,也是用的动捕技术。
面对不同的使用场景,动捕技术也出现了多种技术路线,常见的有光学动作捕捉技术、惯性动作捕捉技术以及视觉动作捕捉技术。
光学动作捕捉技术操作的时候会直接在人的身体上进行简单的标记,标记点会直接反射到提前设定好的摄像机上,然后再通过反射的不同位置的成像信息来预算标记点的空间运动信息,最终将信息进行简单地定位以及输出。

图 | 光学动捕:身上标记光点
惯性动作捕捉技术会直接在人的身上佩戴陀螺仪,人在运动的时候,陀螺仪也会跟着进行旋转。此时,直接通过感知陀螺仪的旋转信息将人的运动推算出,然后实现动作捕捉。
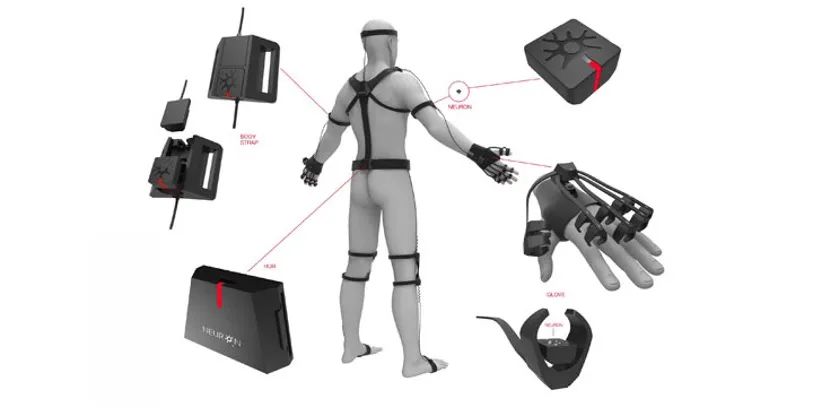
图 | 惯性动捕需穿戴各种设备
视觉动作捕捉技术在操作的时候是不需要标记和佩戴设备的,只要在人的活动范围内通过普通的摄像头进行动作的录制,将人体关键信息进行识别,然后采用特殊AI算法实现动作捕捉。

图 | AI引擎驱动的动捕技术
光学动作捕捉技术和惯性动作捕捉技术有一定的使用门槛,在影视和游戏领域比较常见,虽然呈现的效果非常精准,但存在两个问题:第一,成本高。便宜的至少也需要几万,贵的则需要几十万至几百万不等,只有大型影视和游戏工作室才能负担得起这种成本。第二,使用不方便。在制作现场,动捕演员身上往往穿戴很多设备,穿戴设备与动作捕捉需要团队多人配合。
而更便于在普通消费者市场进行普及的视觉动作捕捉技术,近年来受到苹果、Meta等大厂的追逐。
Meta用一个头显搞定全身动捕
早在2019年,Meta就曾公布其虚拟人头像系统,其特点是通过VR设备进行3D动捕技术来还原真人形象,可渲染出高度保真的肤色、纹理、毛发、微表情等细节。Meta希望未来人们在虚拟环境中见面就像在现实中一样真实。

图 | Meta旗下VR设备Quest可识别面部表情
据外媒报道,根据本月发布的一份论文,Meta提出了一种仅通过Quest实现全身动捕的解决方案。也就是说,此前VR头显仅仅可以将面部表情进行动作捕捉,而现在已经可以实现全身动作捕捉。
这主要是由人工智能的预测能力所驱动的。
对于上半身追踪,通过在AI训练过程中获得的经验,仅需来自现实世界的少量输入就足以将双手准确地转换到虚拟世界。例如,Quest的摄像头可以看到你的手臂,肘部,手掌,所以可以很好地根据肌肉骨骼结构估计上半身的完整姿态。

图 | Quest头显可实现全身动作捕捉
现在对于下半身,Meta同样在探索利用这一原理。使用收集的追踪数据训练人工智能,仅使用来自VR头显和两个控制器的传感器数据,就可以逼真地制作全身虚拟人动画。
Meta团队使用人工生成的传感器数据训练QuestSim (AI引擎)。为此,研究人员根据172人各8小时的运动捕捉剪辑模拟了头显和控制器的运动。这样,他们就不必从头开始捕捉头显和控制器与身体运动的数据。
动作捕捉剪辑包括130分钟的步行、110分钟的慢跑、80分钟的手势、对话、90分钟的白板讨论和70分钟的保持平衡。
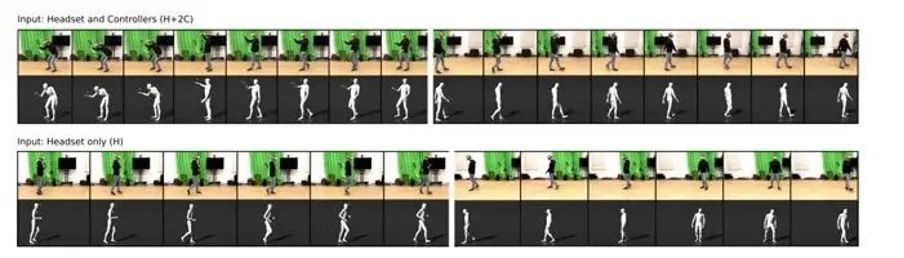
图 | AI引擎自我学习中
训练后,QuestSim可以根据真实的头显和控制器数据识别出一个人正在执行的动作。利用人工智能预测,QuestSim甚至可以模拟没有实时传感器数据的身体部位运动。
研究人员还进一步发现,即使不用手柄控制器,只需要头显的60个姿势(包含位置和方向数据),就足以重建各种运动姿态,还原出来的效果同样没有物理伪影(本不存在却出现在影像中的成像)。
对于动捕技术的未来,中信证券认为,动捕技术有望在生物力学、工程应用、游戏、影视、VR等方向进一步发展和应用。在元宇宙发展的过程中,捕捉用户动作并及时生成虚拟世界中的相应表现是用户高质量体验的重要一环,将来动作捕捉将有广泛的基础应用空间。

中文推特:https://twitter.com/8BTC_OFFICIAL