
前言
在过去的1年里,随着ChatGPT等生成式AI大模型的诞生,AI从简单的自动化工具扩展到复杂的决策和预测系统,发展成为驱动当代社会重要进步动力。AI类产品和应用也发生了爆发式的增长,ChatGPT本身陆续推出GPTs,Sora等瞩目的产品,AI底层设施英伟达的业绩持续超出预期, 2024 财年第四季度中数据中心业务占据83%以上营收,同步增长409%,其中40%用于大模型的推理场景,显示出对于底层算力的快速需求增长。
当下,AI已经成为欧美资本圈竞相追逐的主题,同时Web3市场也迎来新一轮的牛市,AI+Web3是当下最热门的两个技术主题的碰撞,近期也出现了一批该主题的项目,凸显了市场对这个主题的关注和期待。
抛开炒作和价格泡沫,AI+Web行业目前发展情况如何?是否真实有应用场景?长期来看,是否能够创造有价值和叙事和产业?未来AI+Web3的产业将会形成怎样的生态格局,具有潜力的方向在哪里?
围绕以上话题,Future3 Campus将会撰写一系列相关文章,从AI+Web3产业链的各个层面进行分析。本文为第一篇,AI+Web3的整体产业图景和叙事逻辑。
AI工作生产流程
概括地说,AI+Web3结合的方向可以分为两方面,一方面是Web3如何帮助AI发展,另一方面是Web3应用结合AI技术。其中Web3技术和概念赋能AI是当下大部分项目的方向。因此,我们可以通过AI从模型训练到生产的流程中来分析如何与Web3相结合。
LLM的诞生与之前机器学习的流程有一些区别,但总体上,一个简化的AI生产流程大致分为以下几个阶段:
-
数据获取
在AI模型的训练全生命周期中,数据是AI模型提供训练的基石。通常需要采用高质量的数据集作为基础,并进行探索性数据分析 (EDA) ,创造可重现、可编辑和可共享的数据集、表格和可视化图标。
-
数据预处理和特征工程/提示工程
获得数据后需要对数据进行预处理,这里在机器学习中是特征工程(数据标注),在大模型中是提示(Prompt)工程。包括迭代地对数据进行分类、聚合和删除重复数据以标注精细的特征,迭代开发可供LLM结构化查询的Prompt。同时需要可靠地将特征/Prompt进行存储和共享。
-
模型训练和调优
利用丰富的模型库对AI模型进行训练,通过不断的迭代和调整,提升模型的性能、效率和准确性。其中在LLM中主要是通过人类反馈强化学习(RLHF)来不断对模型进行调优。
-
模型审查和治理
使用MLOps/LLMOps平台来优化模型开发流程,包括模型的发现、跟踪、共享和协作,确保模型的质量和透明度,同时符合伦理和合规要求。
-
模型推理
部署训练有素的AI模型,对新的、未见过的数据进行预测。模型利用其学习到的参数对输入数据进行处理,生成预测结果,如分类或回归预测。
-
模型部署和监控
在确保模型性能达标后,将其部署到实际应用场景中,并实施持续的监控和维护,确保模型在动态变化的环境中保持最佳性能。
在以上流程中,有很多Web3与之结合的机会。目前,我们看到AI发展过程中的一些挑战,例如模型的透明度、偏见和伦理应用等问题引起了广泛关注,在这一方面,Web3技术结合ZK等密码学技术,能够改善AI的信任问题。此外,AI应用需求的提高也对更低成本、更开放的基础设施和数据网络提出了要求,而Web3的分布式网络和激励模型也能够打造更加开放、开源的AI网络和社区。
AI+Web3产业图景和叙事逻辑
结合上述AI生产流程和AI与Web3结合的方向,以及当前市场上主流的AI+Web3项目,我们梳理出了AI+Web3产业图景,AI+Web3产业链可以分为三层,分别为基础设施层、中间层和应用层。
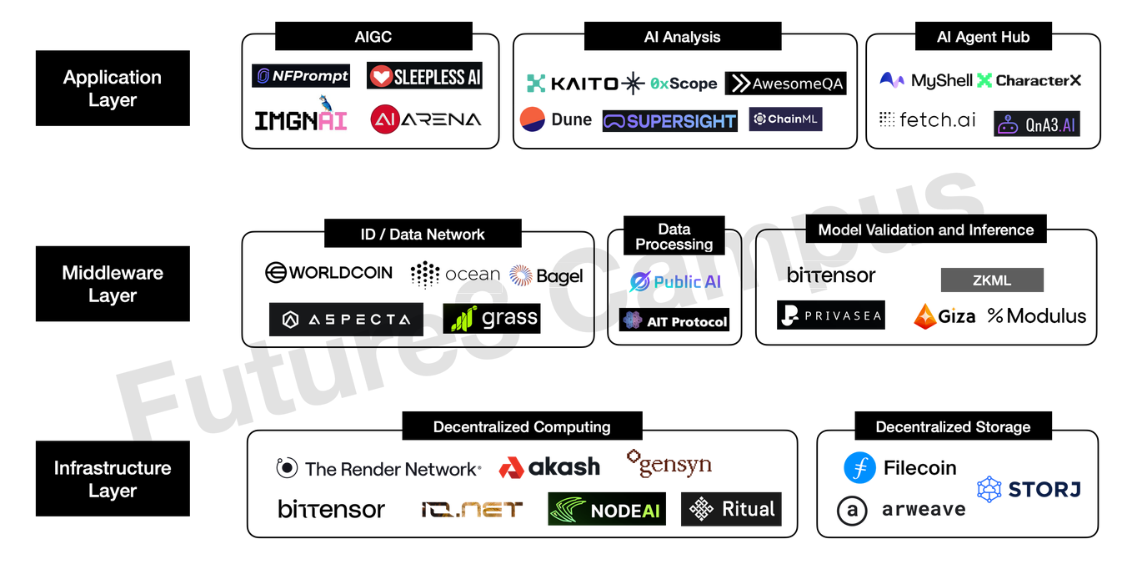
-
基础设施层
主要包括计算和存储基础设施,贯穿整个AI工作生产流程,提供AI模型训练、推测等需要的算力,以及全生命周期中数据和模型的存储。
当前AI应用快速增长,使得对基础设施尤其是高性能算力的需求出现了暴增。因此,提供更高性能、更低成本、更充足的计算和存储基础设施会成为未来几年(AI发展早期)成为非常重要的趋势,预计将抢占50%以上的产业链价值。
Web3能够打造去中心化的计算和存储资源网络,利用闲置、分散的资源,来显著降低基础设施的成本,服务广大的AI应用需求。因此去中心化AI基础设施是目前确定性最高的叙事。
当前这一赛道的代表性项目包括主打渲染服务的Render Network,以及提供去中心化的云服务和计算硬件网络的Akash、gensyn等;存储领域,代表项目仍然是老牌去中心化存储网络Filecoin、Arweave等,最近也推出了针对AI领域的存储和计算服务。
-
中间层
主要指在AI工作生产的特定流程中,采用Web3相关技术改善现状和存在的问题。主要包括:
1)数据获取阶段,采用去中心化的数据身份,创造更开放的数据网络/数据交易平台。主要通过结合密码学技术和区块链特性来保护用户和确权数据,并结合激励措施鼓励用户分享高质量的数据,从而扩大数据来源,提高数据获取效率。这一领域的代表性项目包括AI身份项目Worldcoin,Aspecta,数据交易平台Ocean Protocol,以及低参与门槛的数据网络Grass等。
2)数据预处理阶段:主要创建分布式的AI数据标注和处理平台,采用经济模型激励来鼓励众包模式,以推动更高效、更低成本的数据预处理,服务后续的模型训练阶段。代表项目如Public AI等。
3)模型验证和推理阶段:如上一小节所述,数据和模型黑盒是目前AI中现实存在的问题,因此在模型验证和推理阶段中,Web3能够结合ZK、同态加密等密码学技术,来验证模型的推理,是否使用给定的数据和参数,确保模型的正确性,同时保护输入数据的隐私。典型的应用场景是ZKML。目前Web3技术结合在模型验证和推理阶段的代表性项目包括bittensor、Privasea、Modulus等。
中间层的很多项目更偏向于开发者工具,通常针对现有的开发者、项目方等提供附加服务,在目前AI发展的早期,其市场需求和商业落地仍在发展过程中。
-
应用层
在应用层面,更多的是AI技术如何应用到Web3中。Web3应用结合AI技术能够有效提高效率和产品体验,例如利用AI的内容生成、分析、推测等功能,可以应用到诸如游戏、社交、数据分析、金融预测等各个领域。目前AI+Web3的应用主要可以分为三大类。
1)AIGC类,即采用AI生成式技术允许用户通过对话生成文字、图片、视频、Avatar等内容。以单独的AI agent或者直接结合进产品中展现。代表项目包括NFPrompt、SleeplessAI等。
2)AI分析类,项目方融入自己积累的数据、知识库、分析能力等训练垂直的AI模型,能够进行分析、判断、预测等,并产品化提供给用户,使得用户可以低门槛地获取获取AI的分析能力,例如数据分析、信息追踪、代码审计和修改、金融预测等。代表性项目包括Kaito、Dune等。
3)AI Agent Hub,各类AI Agent的聚合,通常提供用户无代码创建定制化AI Agent的能力,类似GPTs。代表性项目包括My Shell、Fetch.ai等。
应用层目前还有没有出现非常头部的项目,但长期来看一定是天花板更高的板块,具有极强的尚待挖掘的潜力。AI+Web3应用的竞争不在于技术的创新竞争力,而在于产品能力和技术能力的积累,特别是在AI方面能够提供体验更好的产品,将会在这一领域获得更多竞争优势。












