
저자│시드 @IOSG

Web3 게임의 현재 상황
업계로서의 Web3 게임은 더 새롭고 더 집중적인 내러티브가 등장함에 따라 기본 및 공개 시장 내러티브 모두에서 뒷자리를 차지했습니다. 델파이의 2024년 게임 산업 보고서에 따르면, 1차 시장에서 Web3 게임의 누적 자금 조달 금액은 10억 달러 미만입니다. 이것이 꼭 나쁜 것은 아니며 단지 거품이 가라앉았고 현재 자본이 더 높은 품질의 게임과 호환될 수 있음을 보여줄 뿐입니다. 아래 그림은 분명한 지표입니다.
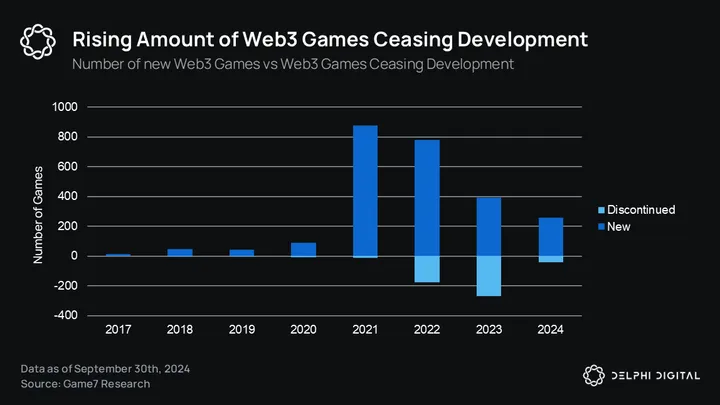
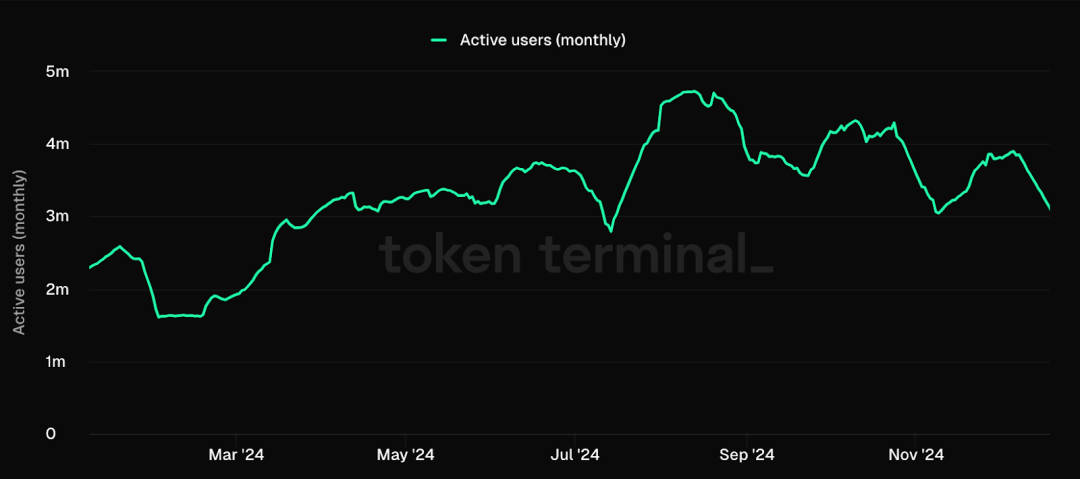
2024년 내내 Ronin과 같은 게임 생태계는 사용자 수가 엄청나게 급증하여 Fableborn과 같은 고품질 새 게임의 등장으로 인해 2021년 Axie의 전성기와 거의 맞먹었습니다.
게임 생태계(L1, L2, RaaS)는 점점 Web3의 Steam과 유사해지고 있으며, 이는 생태계 내 배포를 제어하며, 이는 플레이어 확보에 도움이 되기 때문에 게임 개발자가 이러한 생태계에서 게임을 개발하는 데 인센티브가 되었습니다. 이전 보고서에 따르면 Web3 게임의 사용자 확보 비용은 Web2 게임보다 약 70% 더 높습니다.
플레이어 끈적임
플레이어를 유지하는 것은 플레이어를 유치하는 것보다 더 중요하지는 않더라도 그만큼 중요합니다. Web3 게임의 플레이어 유지율에 대한 데이터가 부족하지만 플레이어 유지율은 "흐름"(헝가리 심리학자 Mihaly Csikszentmihalyi가 만든 용어) 개념과 밀접한 관련이 있습니다.
"흐름 상태"는 플레이어가 도전과 기술 수준 사이의 완벽한 균형을 이루는 심리적 개념입니다. 그것은 마치 "영역에 들어가는 것"과 같습니다. 시간이 빨리 지나가는 것처럼 느껴지고 게임에 완전히 몰입하게 됩니다.
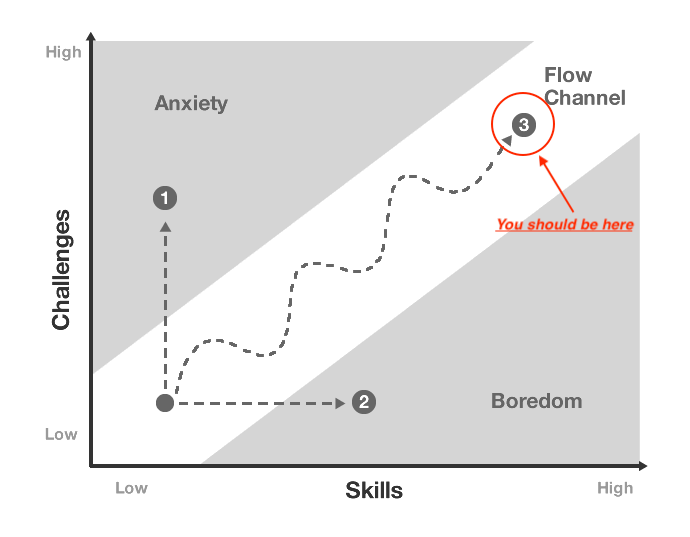
지속적으로 흐름 상태를 생성하는 게임은 다음과 같은 메커니즘으로 인해 유지율이 더 높은 경향이 있습니다.
#어드밴스디자인
게임 초반: 자신감을 키우기 위한 간단한 도전
게임 중반: 점점 난이도가 높아집니다.
게임 후반: 복잡한 도전, 게임 마스터하기
플레이어의 기술이 향상됨에 따라 이러한 세분화된 난이도 조정을 통해 자신의 속도를 유지할 수 있습니다.
#루프에 참여하세요
단기: 즉각적인 피드백(킬, 포인트, 보상)
중기: 레벨 및 일일 작업 완료
장기: 캐릭터 성장, 랭킹
이러한 중첩 루프는 다양한 기간 동안 플레이어의 관심을 유지합니다.
#흐름 상태를 파괴하는 요소는 다음과 같습니다.
1. 부적절한 난이도/복잡성 설정: 이는 잘못된 게임 디자인 때문일 수도 있고, 플레이어 수가 부족하여 매치메이킹이 불균형할 수도 있습니다.
2. 불분명한 목표: 게임 디자인 요소
3. 피드백 지연: 게임 디자인 및 기술적 문제로 인한
4. 침입적인 수익 창출: 게임 디자인 + 제품
5. 기술적 문제/지연

게임과 AI의 공생
AI 에이전트는 플레이어가 이러한 흐름 상태를 달성하도록 도울 수 있습니다. 이 목표를 달성하는 방법을 논의하기 전에 먼저 게임 분야에서 사용하기에 적합한 에이전트 종류를 이해해 보겠습니다.
LLM 및 강화 학습
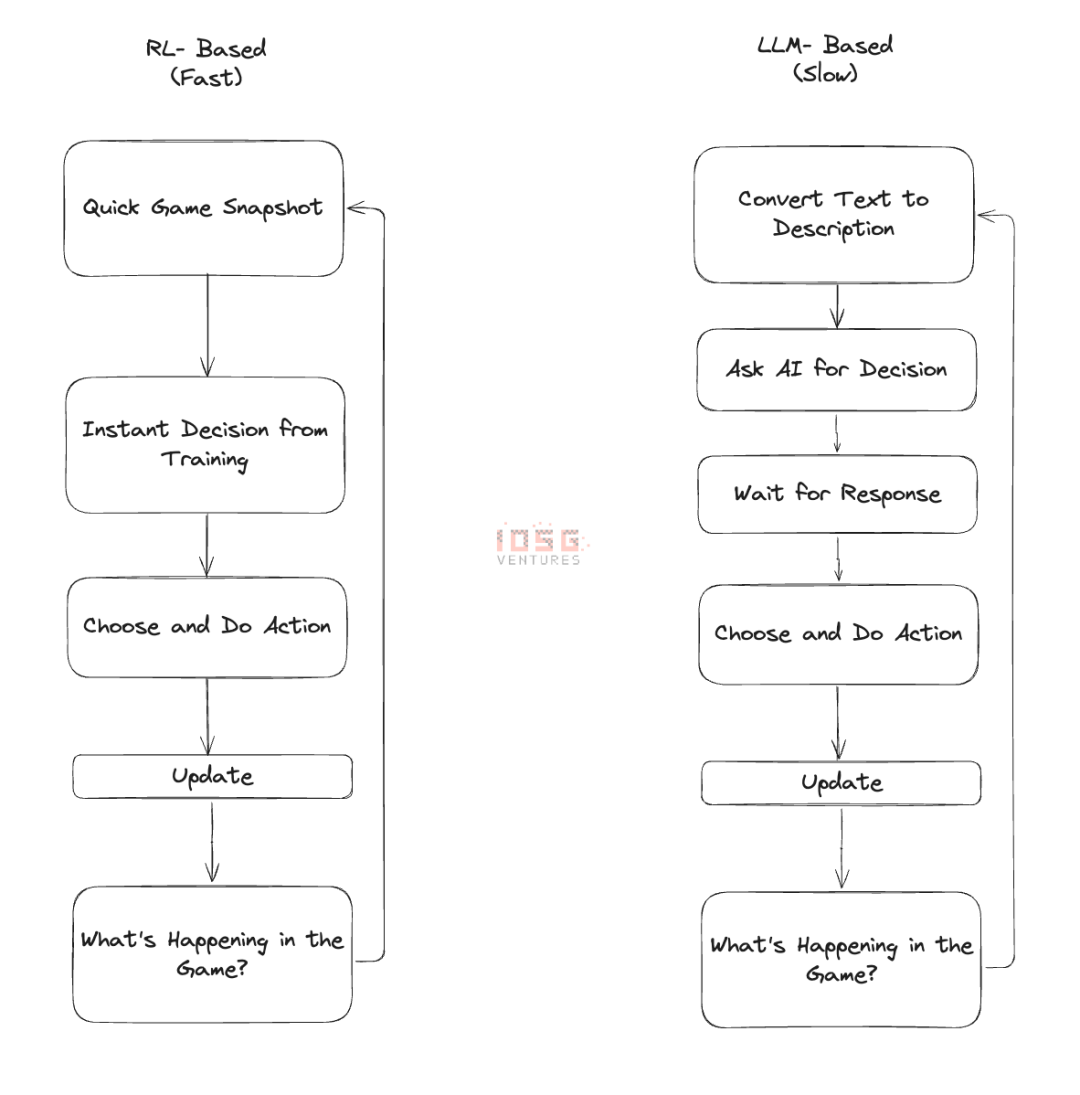
게임 AI의 핵심은 속도와 규모입니다. 게임에서 LLM 기반 에이전트를 사용할 때 각 결정에는 거대한 언어 모델을 호출해야 합니다. 이는 모든 단계 전에 중개자가 있는 것과 같습니다. 중개인은 똑똑하지만 그의 응답을 기다리는 것은 모든 일을 느리고 고통스럽게 만듭니다. 이제 게임에서 수백 명의 캐릭터에 대해 이 작업을 수행한다고 상상해 보십시오. 속도가 느릴 뿐만 아니라 비용도 많이 듭니다. 이것이 아직 게임에서 대규모 LLM 에이전트를 볼 수 없는 주된 이유입니다. 지금까지 우리가 본 가장 큰 실험은 Minecraft에서 개발된 1,000명의 에이전트 문명입니다. 서로 다른 맵에 100,000명의 동시 에이전트가 있는 경우 비용이 매우 많이 듭니다. 새로운 에이전트가 추가될 때마다 지연이 발생하므로 플레이어는 트래픽 중단의 영향을 받습니다. 이는 흐름 상태를 파괴합니다.
강화 학습(RL)은 다른 접근 방식입니다. 헤드셋을 통해 서로에게 단계별 지시를 하기보다는 댄서를 훈련시키는 것과 비슷하다고 생각합니다. 강화 학습을 사용하면 AI에게 "춤추는" 방법과 게임 내 다양한 상황에 대응하는 방법을 가르치는 데 초기 시간을 투자해야 합니다. 일단 훈련되면 AI는 자연스럽게 흐르며 상향 요청 없이 밀리초 안에 결정을 내립니다. 수백 개의 훈련된 에이전트를 게임에서 실행할 수 있으며, 각 에이전트는 보고 듣는 내용에 따라 독립적인 결정을 내릴 수 있습니다. LLM 에이전트만큼 명료하거나 유연하지는 않지만 신속하고 효율적으로 작업을 수행합니다.
RL의 진정한 마법은 이러한 에이전트가 함께 작동해야 할 때 나타납니다. LLM 에이전트가 조정을 위해 긴 "대화"를 필요로 하는 경우, RL 에이전트는 몇 달 동안 함께 훈련해 온 축구팀처럼 훈련에서 암묵적인 관계를 발전시킬 수 있습니다. 그들은 서로의 움직임을 예상하고 자연스럽게 조화를 이루는 법을 배웁니다. 이것이 완벽하지는 않지만 때로는 LLM이 저지르지 않는 실수를 저지르기도 하지만 LLM이 따라올 수 없는 규모로 운영될 수 있습니다. 게임 애플리케이션의 경우 이러한 절충안은 항상 의미가 있습니다.
에이전트 및 NPC
NPC로서의 에이전트는 오늘날 많은 게임이 직면한 첫 번째 핵심 문제인 플레이어 이동성을 해결합니다. P2E는 플레이어 유동성 문제를 해결하기 위해 암호경제학을 사용한 최초의 실험이었고, 우리 모두는 그 결과가 어떻게 되었는지 알고 있습니다.
사전 훈련된 에이전트는 두 가지 목적으로 사용됩니다.
- 멀티플레이어 게임에서 세계를 채우세요
- 전 세계 플레이어 그룹의 난이도를 흐름 상태로 유지합니다.
이것이 명백해 보일 수도 있지만 구축하기 어려울 수 있습니다. 독립 게임과 초기 Web3 게임에는 인공 지능 팀을 고용할 만큼 충분한 재정 자원이 없습니다. 이는 RL을 핵심으로 하는 모든 에이전트 프레임워크 서비스 제공자에게 기회를 제공합니다.
게임은 플레이 및 테스트 중에 이러한 서비스 제공업체와 협력하여 게임 출시 시 플레이어 이동성의 기반을 마련할 수 있습니다.
이런 방식으로 게임 개발자는 게임 메커니즘에 집중하여 게임을 더욱 흥미롭게 만들 수 있습니다. 우리는 토큰을 게임에 통합하는 것을 좋아하는 만큼 게임은 게임이고 게임은 재미있어야 합니다.
에이전트 플레이어
세계에서 가장 많이 플레이되는 게임 중 하나인 리그 오브 레전드(League of Legends)에는 플레이어가 최고의 속성으로 캐릭터를 훈련시키는 암시장이 있지만 게임에서는 그렇게 하는 것이 금지되어 있습니다.
이는 NFT의 기반이 되는 게임 캐릭터와 속성을 형성하고 이를 가능하게 하는 시장을 만드는 데 도움이 됩니다.
이러한 AI 에이전트의 코치 역할을 하는 새로운 "플레이어" 하위 집합이 등장한다면 어떻게 될까요? 플레이어는 이러한 AI 에이전트를 지도하고 경기 승리 등 다양한 형태로 수익을 창출할 수 있으며, e스포츠 선수나 열정적인 플레이어를 위한 '훈련 파트너' 역할도 할 수 있습니다.
메타버스의 귀환?
메타버스의 초기 버전이 단순히 이상적인 현실이 아닌 대체 현실을 만들어 냈기 때문에 목표를 놓쳤을 가능성이 있습니다. AI 에이전트는 메타버스의 주민들이 이상적인 세계, 즉 탈출구를 만들 수 있도록 돕습니다.
제 생각에는 이것이 바로 LLM 기반 프록시가 유용할 수 있는 부분이라고 생각합니다. 어쩌면 누군가는 도메인 전문가이고 자신이 좋아하는 것에 대해 대화를 나눌 수 있는 사전 교육을 받은 에이전트로 자신의 세계를 채울 수도 있습니다. 1000시간의 Elon Musk 인터뷰를 통해 훈련된 에이전트를 만들고 사용자가 자신의 세계에서 해당 에이전트의 인스턴스를 사용하기를 원한다면 그에 대한 보상을 받을 수 있습니다. 이는 새로운 경제를 창출합니다.
Nifty Island와 같은 메타버스 게임을 사용하면 이것이 현실이 될 수 있습니다.
Today: The Game에서 팀은 라이브 스트리밍을 24x7 시청하는 동안 여러 에이전트가 전 세계에서 자율적으로 상호 작용한다는 비전을 가지고 "Limbo"라는 LLM 기반 AI 에이전트(투기 토큰 출시)를 만들었습니다.

암호화폐가 여기에 어떻게 들어맞나요?
암호화폐는 다양한 방식으로 이러한 문제를 해결하는 데 도움이 될 수 있습니다.
- 플레이어는 더 나은 경험을 위해 모델을 개선하기 위해 게임 데이터를 제공하고 그에 대한 보상을 받습니다.
- 캐릭터 디자이너, 트레이너 등 다양한 이해관계자와 협력하여 최고의 게임 내 에이전트를 만듭니다.
- 게임 내 에이전트 소유권을 위한 마켓플레이스를 만들고 이를 통해 수익을 창출하세요.
이 모든 일과 그 이상을 수행하는 팀이 있습니다. 바로 ARC 에이전트입니다. 그들은 위에서 언급한 모든 문제를 해결하고 있습니다.
그들은 게임 개발자가 게임 매개 변수를 기반으로 인간과 유사한 인공 지능 에이전트를 만들 수 있는 ARC SDK를 보유하고 있습니다. 매우 간단한 통합을 통해 플레이어 이동성 문제를 해결하고, 게임 데이터를 정리하고 통찰력으로 전환하며, 난이도를 조정하여 플레이어가 흐름을 유지하도록 돕습니다. 이를 위해 강화학습(Reinforcement Learning) 기술을 사용했습니다.
그들은 원래 AI 캐릭터가 싸울 수 있도록 기본적으로 훈련시키는 AI Arena라는 게임을 개발했습니다. 이는 ARC SDK의 기초를 형성하는 기본 학습 모델을 형성하는 데 도움이 되었습니다. 이렇게 하면 DePIN과 같은 플라이휠이 생성됩니다.
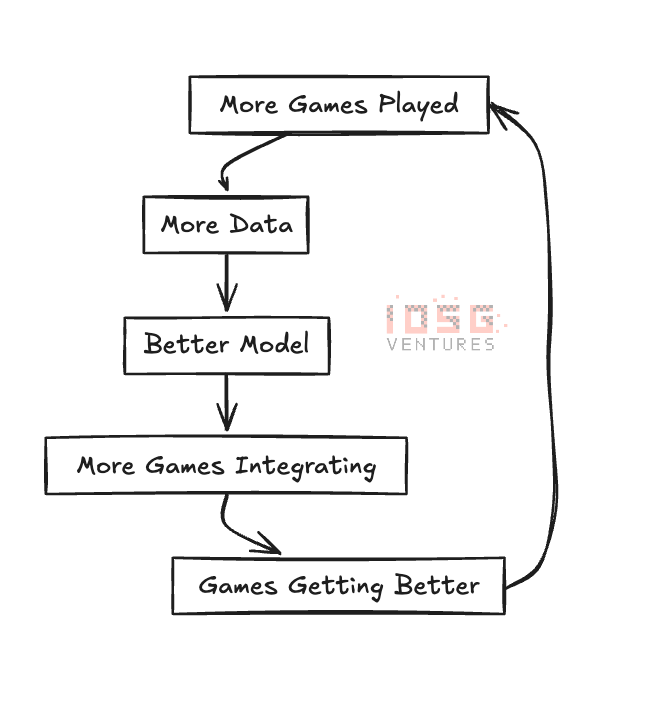
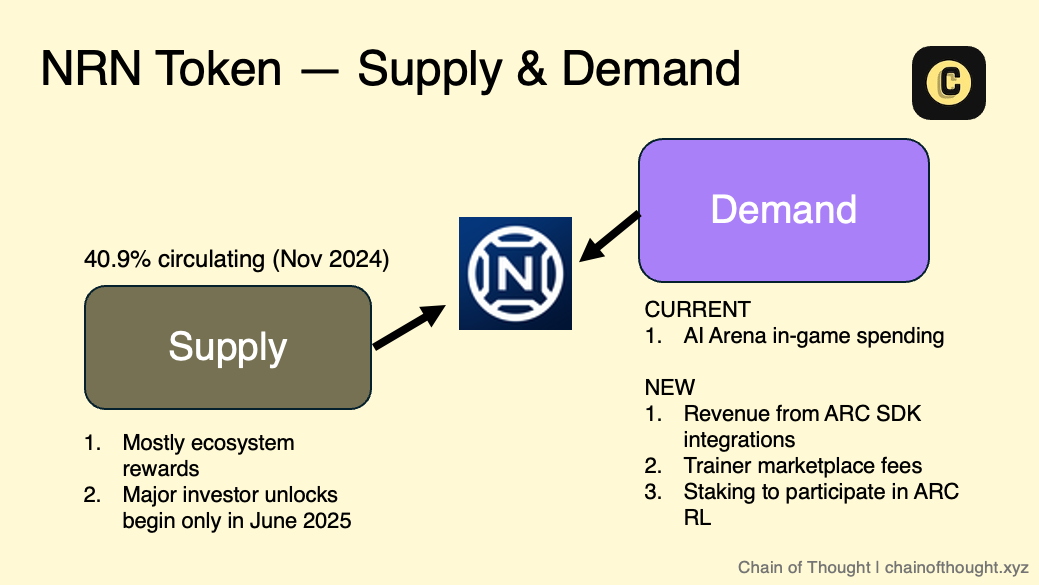
이 모든 것은 생태계 토큰 $NRN으로 조정됩니다. Chain of Thought 팀은 ARC 프록시에 대한 기사에서 이에 대해 매우 잘 설명합니다.
Bounty와 같은 게임은 에이전트 우선 접근 방식을 취하고 Wild West 세계에서 처음부터 에이전트를 구축합니다.

결론
AI 에이전트, 게임 디자인, 암호화폐의 융합은 단순한 기술 트렌드가 아니라 인디 게임을 괴롭히는 다양한 문제를 해결할 수 있는 잠재력을 가지고 있습니다. 게임에서 AI 에이전트의 가장 큰 장점은 게임을 재미있게 만드는 요소, 즉 좋은 경쟁, 풍부한 상호 작용, 계속해서 더 많은 것을 위해 돌아오게 만드는 도전 과제를 강화한다는 것입니다. ARC 에이전트와 같은 프레임워크가 성숙해지고 더 많은 게임이 AI 에이전트를 통합함에 따라 완전히 새로운 게임 경험이 등장할 가능성이 높습니다. 다른 플레이어가 있어서가 아니라 그 안에 있는 에이전트가 커뮤니티와 함께 학습하고 발전할 수 있기 때문에 살아있는 세상을 상상해 보세요.
우리는 "플레이 투 적립(play-to-earn)" 시대에서 더욱 흥미진진한 시대, 즉 정말 재미 있고 무한히 확장 가능한 게임으로 이동하고 있습니다. 향후 몇 년은 이 분야에 초점을 맞춘 개발자, 플레이어 및 투자자에게 흥미진진한 시간이 될 것입니다. 2025년 이후의 게임은 기술적으로 더욱 발전할 뿐만 아니라 근본적으로 우리가 이전에 본 어떤 것보다 더 매력적이고 생생할 것입니다.












