
作者:雾月,极客web3
众所周知,EVM的定位是以太坊的“执行引擎”和“智能合约执行环境”,可以说是以太坊最重要的核心组件之一。公链是一个包含成千上万节点的开放性网络,不同节点的硬件参数相差甚大,若想让智能合约在多个节点上都跑出相同结果,满足“一致性”,要设法在不同设备上都搭建出相同的环境,而虚拟机可以实现这个效果。
以太坊的虚拟机EVM能在不同操作系统(如Windows、Linux、macOS)和设备上以相同的方式来运行智能合约,这种跨平台兼容性确保每个节点运行合约后,都能得到一致的结果。最典型的例子就是Java虚拟机JVM。
我们平时在区块浏览器里看到的智能合约,都是先被编译为EVM字节码,然后才存储到链上的。EVM在执行合约时,直接按顺序读取这些字节码,字节码对应的每条指令(opCode)都有相应的Gas成本。EVM会跟踪每条指令在执行过程中的Gas消耗,消耗量则取决于操作的复杂度。
此外,作为以太坊的核心执行引擎,EVM采用串行执行的方式处理交易,所有交易在单一队列里排队并按照确定顺序先后执行。之所以不用并行化的方式,是因为区块链要严格满足一致性,一批交易在所有节点中都要按相同次序来处理,如果将交易处理并行化,难以精确的预判交易次序,除非引入对应的调度算法,但这会比较复杂。
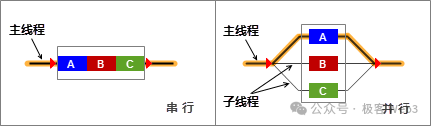
2014~15年的以太坊创始团队出于时间紧迫,选用了串行执行的方式。因为它设计简单且易于维护。然而随着区块链技术的迭代和用户群体越来越大,区块链对TPS和吞吐量的要求越来越高,在Rollup技术出现并成熟落地后,EVM串行执行带来的性能瓶颈在以太坊二层身上已经暴露无疑。
Sequencer作为Layer2的关键组件,以单个服务器的形式承接所有运算任务,如果与Sequencer配合的外部模块的效率都足够高,则最终的瓶颈将取决于Sequencer本身的效率,此时串行执行将成为巨大的阻碍。
opBNB团队曾通过对DA层和数据读写模块进行极致优化,Sequencer每秒最多可执行约2000多笔ERC-20转账。这个数字看起来很高,但如果要处理的交易比ERC-20转账复杂很多,TPS数值必然会大打折扣。所以说,交易处理的并行化将是未来的必然趋势。
下面我们将从更具体的细节入手,为大家详细解释传统EVM的局限性,以及并行EVM的优势。
以太坊交易执行的两大核心组件
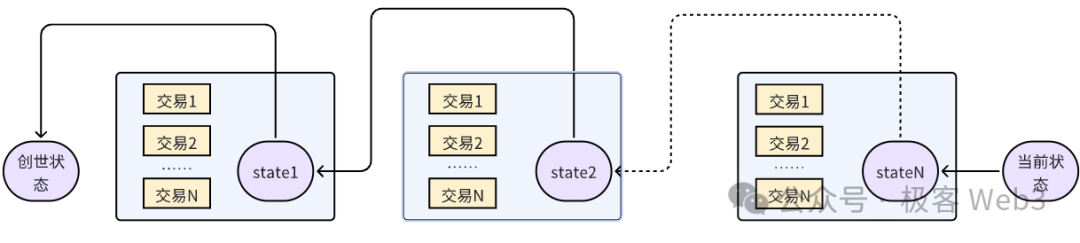
在代码模块层面,除EVM外,go-ethereum中与交易执行相关的另一核心组件是stateDB,用于管理以太坊中的账户状态和数据存储。以太坊采用名为Merkle Patricia Trie的树状结构来充当数据库索引(目录),EVM每一次交易执行都会变更stateDB中存放的某些数据,这些变更最终会反映在Merkle Patricia Trie(后面简称全局状态树)中。
具体来说,stateDB负责维护所有以太坊账户的状态,包括EOA账户和合约账户,其存储的数据包括账户余额、智能合约代码等。在交易执行过程中,stateDB会对相应账户的数据进行读写。而在交易执行结束后,stateDB需要将新的状态提交到底层数据库(如LevelDB)中,进行持久化处理。
总的来说,EVM负责解释和执行智能合约指令,根据计算结果变更区块链上的状态,而stateDB则充当全局状态存储,管理所有账户和合约的状态变化。两者协作构建了以太坊的交易执行环境。
串行执行的具体过程
以太坊的交易类型分两种,即EOA转账和合约交易。EOA转账是最简单的交易类型,即普通账户之间的ETH转账。这种交易不涉及合约调用,处理速度非常快。由于操作简单,EOA转账收取的gas费极低。
与简单的EOA转账不同,合约交易会涉及到智能合约的调用与执行。EVM在处理合约交易时,要逐条解释和执行智能合约中的字节码指令,合约的逻辑越复杂,涉及的指令越多,消耗的资源越多。
举例来说,ERC-20转账的处理时间大约是EOA转账的2倍,而对于更复杂的智能合约,如Uniswap上的交易操作,耗时更长,甚至可以比EOA转账慢十几倍。这是因为DeFi协议需要在交易时处理流动性池、价格计算、代币swap等复杂逻辑,需要进行非常复杂的计算。
那么在串行执行模式下, EVM与stateDB这两个组件是如何协作处理交易的呢?
在以太坊的设计中,一个区块内的交易会按先后次序被一笔笔处理,每笔交易(tx)都会有一个独立实例,用于执行该交易的具体操作。尽管每笔交易会使用不同的EVM实例,但所有交易要共用同一个状态数据库,也就是stateDB。
在交易执行过程中,EVM需要不断与stateDB交互,从stateDB中读取相关的数据,并将变更后的数据写回stateDB。
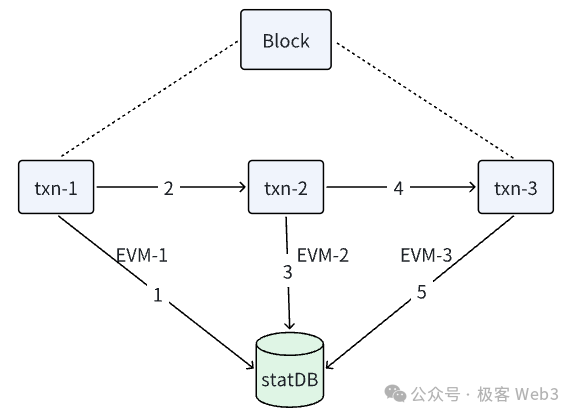
我们从代码角度大致看下EVM和stateDB是如何协作执行交易的:
1. processBlock()函数会调用Process()函数处理一个区块中包含的交易;

2. Process()函数中定义了一个for循环,可以看到交易是被一笔一笔执行的;
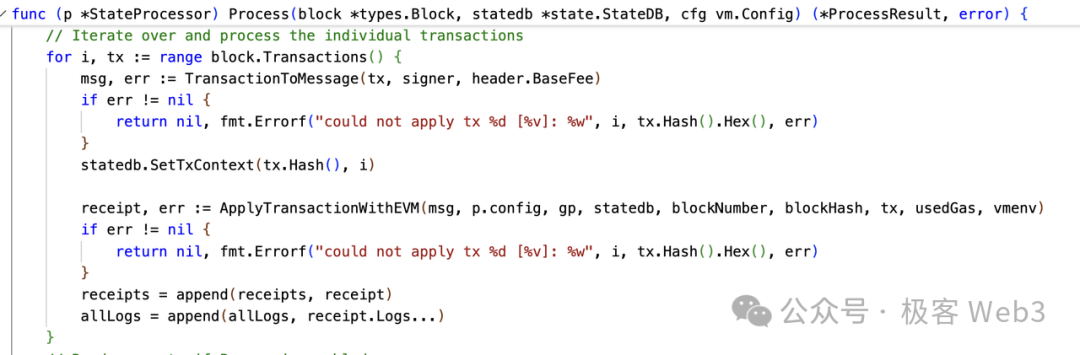
3. 在所有交易处理完毕后,processBlock()函数调用writeBlockWithState()函数,再调用statedb.Commit()函数,提交状态变更结果。
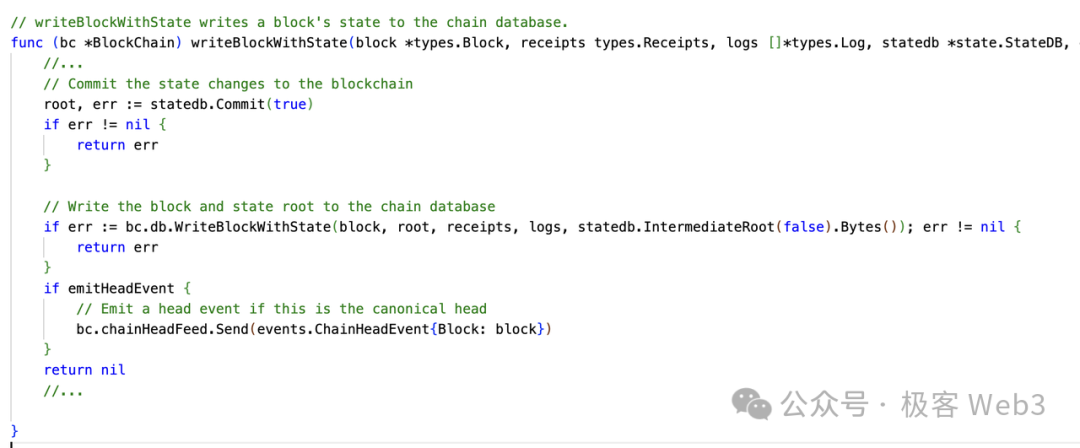
当一个区块中所有交易都被执行完毕后,stateDB中的数据会被Commit到前面提到的全局状态树(Merkle Patricia Trie),并生成新的状态根(stateRoot)。状态根是每个区块中的重要参数,它记录了区块执行后新的全局状态的“压缩结果”。
我们不难理解,EVM的串行执行模式瓶颈很明显:交易必须按顺序排队执行,如果出现耗时很久的智能合约交易,在其处理完毕前,其他交易只能等待,这显然无法充分利用CPU等硬件资源,效率会受到较大限制。
EVM的多线程并行优化方案
如果用生活中的例子来对比串行执行与并行执行,前者类比为只有一个柜台的银行,并行EVM则类比为有多个柜台的银行。在并行模式下,可以开启多个线程同时处理多笔交易,效率可以得到几倍速的提升,但棘手的地方在于状态冲突问题。
如果多笔交易都声明要改写某个账户的数据,当它们被同时处理时,就会产生冲突,比如某NFT仅能铸造1个,而交易1和交易2都声明要铸造该NFT,如果他们的请求都得到满足,显然会出现错误,应对这类情况需要进行协调处理。实际操作中的状态冲突往往比我们提到的更频发,所以如果要将交易处理并行化,就必须要有应对状态冲突的措施。
Reddio对EVM的并行优化原理
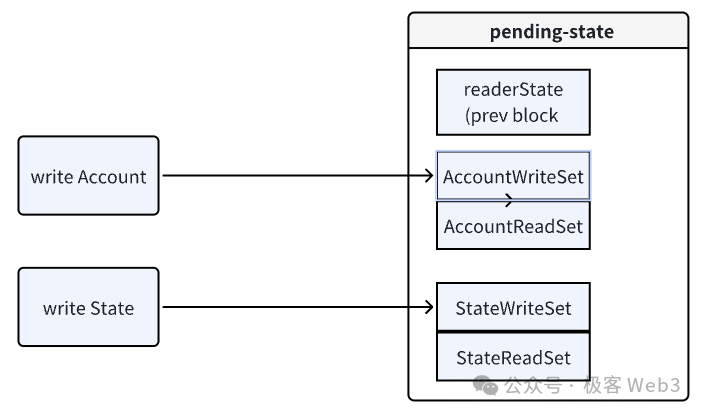
我们可以看一下ZKRollup项目Reddio对EVM的并行优化思路。Reddio的思路是为每个线程都分配一笔交易,并在每个线程中提供一个临时的状态数据库,称为pending-stateDB。具体细节如下:
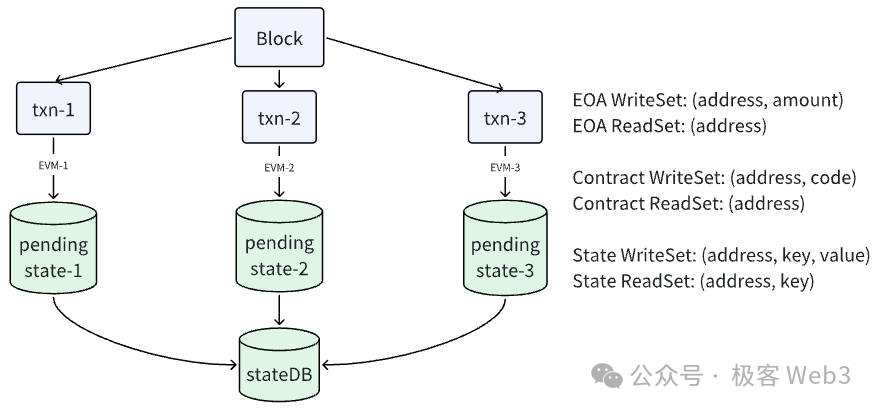
1. 多线程并行执行交易:Reddio设置多个线程同时处理不同的交易,线程之间互不干扰。这可以几倍速提升交易处理速度。
2. 为每个线程分配临时状态数据库:Reddio为每个线程都分配一个独立的临时状态数据库(pending-stateDB)。各个线程在执行交易时,不会直接修改全局的stateDB,而是将状态变化结果暂时记录在pending-stateDB中。
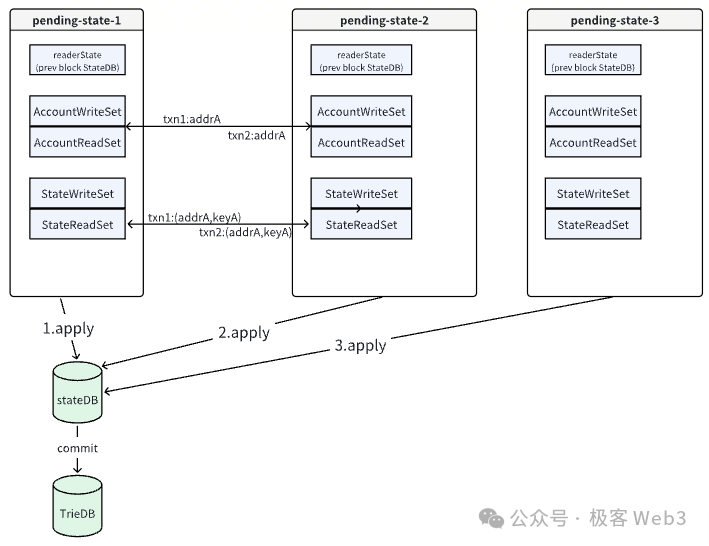
3. 同步状态变更:在一个区块内的所有交易都执行完毕后,EVM会将每个pending-stateDB中记录的状态变更结果依次同步到全局stateDB中。如果不同交易在执行过程中没有发生状态冲突,就可以将pending-stateDB中的记录顺利合并到全局stateDB中。
Reddio对读写操作的处理方式进行了优化,以确保交易能够正确访问状态数据并避免冲突。
·读操作:当一个交易需要读取状态时,EVM会首先检查Pending-state的ReadSet。如果ReadSet显示存在所需数据,EVM就直接从pending-stateDB中读数据。如果ReadSet中没有找到对应的key-value(键值对),就从上一个区块对应的全局stateDB中读取历史状态数据。
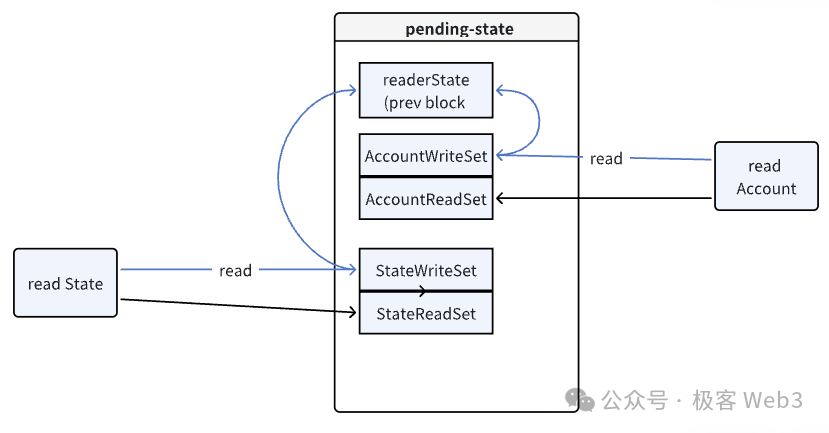 ·写操作:所有写操作(即对状态的修改)都不会直接写入全局stateDB,而是先记录到Pending-state 的WriteSet中。待交易执行完成后,通过冲突检测再尝试将状态变更结果合并到全局stateDB中。
·写操作:所有写操作(即对状态的修改)都不会直接写入全局stateDB,而是先记录到Pending-state 的WriteSet中。待交易执行完成后,通过冲突检测再尝试将状态变更结果合并到全局stateDB中。
 并行执行的关键问题在于状态冲突,当多笔交易尝试读写相同账户的状态时,该问题尤为显著。为此Reddio引入了冲突检测机制:
并行执行的关键问题在于状态冲突,当多笔交易尝试读写相同账户的状态时,该问题尤为显著。为此Reddio引入了冲突检测机制:
· 冲突检测:在交易执行过程中,EVM会监测不同交易的ReadSet和WriteSet。如果发现多个交易尝试读写相同的状态项,则视为发生冲突。
· 冲突处理:当检测到冲突时,冲突交易将被标记为需要重新执行。
在所有交易都执行完成后,多个pending-stateDB中的变更记录会被合并到全局stateDB中。如果合并成功,EVM会将最终状态提交到全局状态树中,并生成新的状态根。
 多线程并行优化对性能的提升是显而易见的,特别是应对复杂智能合约交易时。
多线程并行优化对性能的提升是显而易见的,特别是应对复杂智能合约交易时。
根据并行EVM的研究显示,在低冲突工作负载(交易池中较少矛盾的或者占用相同资源的交易)中,基准测试的TPS相比传统的串行执行,提升了3~5倍左右。在高冲突工作负载中,理论上如果将所有优化手段都用上甚至可以达到60倍。
总结
Reddio的EVM多线程并行优化方案,通过为每个交易分配临时状态库,并在不同线程中并行执行交易,显著提高了EVM的交易处理能力。通过优化读写操作和引入冲突检测机制,EVM系公链能够在保证状态一致性的前提下,实现交易的大规模并行化,解决了传统串行执行模式带来的性能瓶颈。这为以太坊Rollup未来的发展奠定了重要基础。
后续我们会进一步深入分析Reddio的实现细节,如如何进一步从优化存储效率提升效率,冲突高发时的优化方案,以及如何借助GPU做优化等等内容。












