
作者:Eito Miyamura
编译:深潮TechFlow
GatlingX是一个由牛津大学校友领导的项目,专注于机器学习和强化学习,他们最近推出了“GPU-EVM”——据内部基准测试成绩显示,这可能是目前市面上性能最强的以太坊虚拟机(EVM)。
GPU-EVM是一种EVM扩展解决方案,性能非常强大,以至于最先进的基于强化学习(RL)的人工智能代理可以在其上进行训练,开发团队表示。它利用并行执行多种以太坊应用程序,帮助训练AI代理寻找安全漏洞。
GPU-EVM使用图形处理单元(GPUs)并行执行操作,从而提高交易吞吐量。该团队声称,GPU-EVM的处理任务速度几乎是目前高性能EVM(包括evmone和revm)的100倍。这主要得益于GPU能够同时处理多个操作,利用其天生适合并行处理的架构。
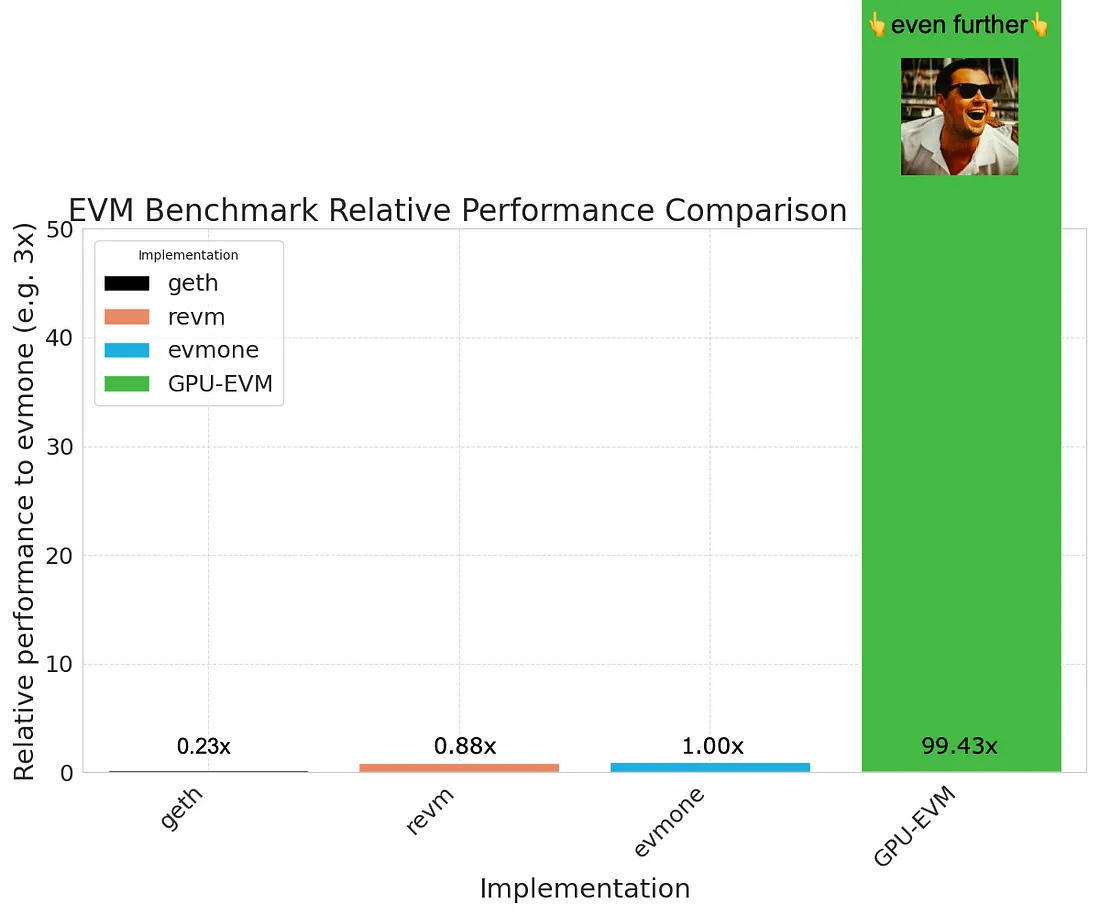
GPU-EVM 利用图形处理单元(GPU)的强大能力来并行运行以太坊虚拟机(EVM)操作。这意味着,与其依次执行任务,GPU-EVM 可以同时处理许多任务,显著加快计算速度。牛津大学计算机科学/人工智能校友团队的这一突破大幅提高了以太坊虚拟机每秒计算的单位经济效益。
以太坊虚拟机(EVM)是行业标准的虚拟机,运行智能合约,是现代区块链技术的基础。EVM 类似于区块链的操作系统,通过其基于 CPU 的客户端软件,在许多分布式计算机上实现无需信任第三方的交易。
有了 GPU-EVM 及其提供的性能增强,它给下游雄心勃勃的工程团队带来了巨大的功能提升:为与 EVM 交互的 AI/RL 模型提供基础设施、加速 L2、MEV、回测等。(详细信息见下文)
GPU-EVM:EVM 计算的新范式
英伟达最初是一家专注于游戏的小众公司,但现在已成为计算领域的关键参与者,处于人工智能革命的前沿。这种演变反映了从预测每两年计算能力翻倍的摩尔定律转向黄氏定律的过程,后者以英伟达首席执行官黄仁勋的名字命名。黄氏定律认为,由于硬件、软件和人工智能的整合,GPU 性能将在两年内增加一倍以上,超过 CPU,使 GPU 成为加速复杂任务的核心。
当我们达到摩尔定律的极限时,对 GPU 并行性的依赖预示着一个新的计算时代,从 CPU 主导向 GPU 驱动的进步过渡(参考Dennard scaling、阿姆达尔定律)。这种转变就像从单车道道路转向多车道高速公路一样,不仅加快了流程,还实现了更多同时进行的活动,从而拓展了技术上的可能性。
杰文斯悖论很好地说明了这种效果:就像 LED 灯泡的效率导致了更广泛而不是减少的使用一样,GPU-EVM 的增强效率和降低成本开启了大量新的可能性。它不仅仅节省资源,还催生了区块链技术及其以外的创新和采用,承诺了一个未来,其中 GPU 计算的效率推动了计算应用的指数增长。
GPU-EVM 性能
利用现代 GPU 的通用计算能力的显著进步,我们已经将 GPU-EVM 的性能提升到传统 EVM 的惊人水平的 100 倍以上。现代 GPU 设计有数千个核心,能够同时处理多个操作,使其非常适合并行处理任务。这种固有的架构优势使 GPU-EVM 能够并行执行大量的 EVM 指令,大大加快了计算速度和效率。
为了客观地衡量 GPU-EVM 带来的性能提升,我们使用EVM Bench提供的开源工具进行了全面的基准测试。这个工具允许我们模拟各种 EVM 操作,并比较传统基于 CPU 的 EVM 与我们的 GPU-EVM 之间的执行时间。
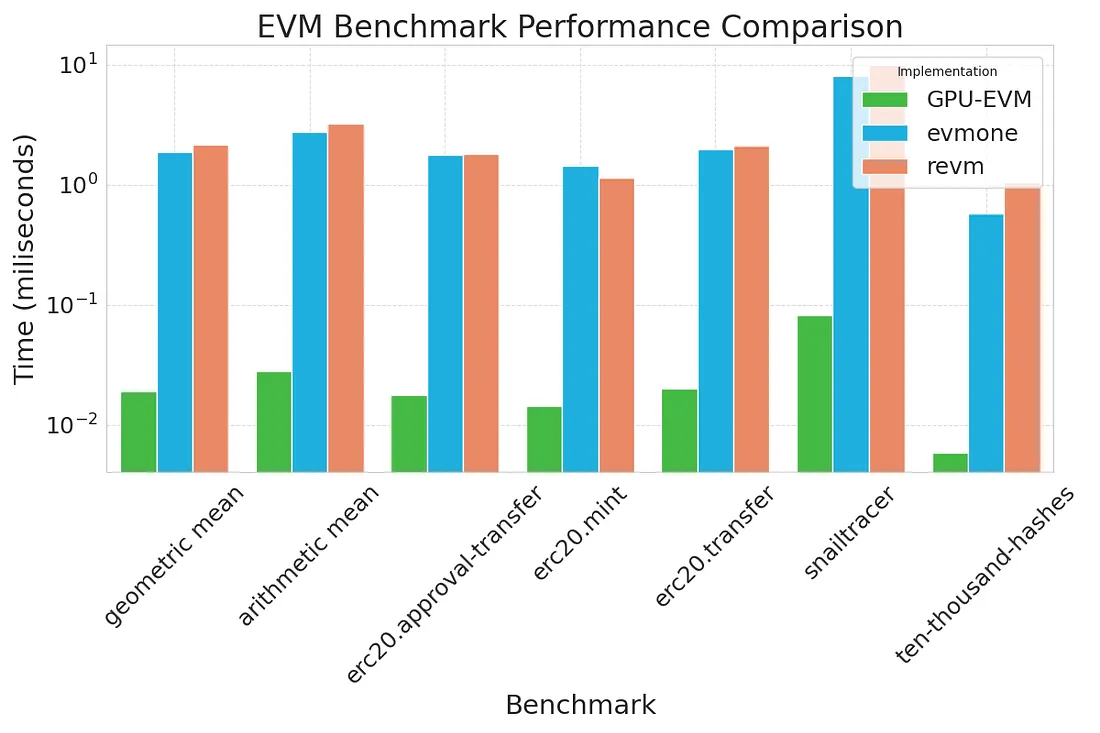
与传统的计算范式相比,GPU-EVM 利用 GPU 无与伦比的处理能力完全领先,为 EVM 的性能和效率设定了新的基准。
有了这个技术基础,让我们探讨一下 GPU-EVM 如何革新 AI 训练和 DeFi 模拟等领域,为区块链应用开辟新的前沿。
使用 EVM 训练 AI 代理
人工智能正在改变世界,由 ChatGPT 和其他 LLM 聊天机器人领导,他们通过人类反馈的强化学习进行了训练,应用了强化学习(RL)的知识。在其核心,RL 体现了通过与奖励正确行为的环境进行交互来训练 AI 代理做出决策的过程。这种学习方法至关重要,因为它反映了人类和动物从周围环境中学习的基本方式,使其成为能够自适应和优化其行为的智能系统开发的基石。
AlphaGo 在围棋世界冠军身上取得的里程碑式胜利证明了 RL 的变革力量。这不仅仅是一场比赛;它展示了通过 RL,AI 可以发现超越人类洞察力的战略和解决方案的方式,通过模拟和与围棋棋盘复杂环境的交互。这一突破突显了 RL 的本质:使 AI 代理能够自主导航并从其环境中学习,以实现特定目标,受奖励系统指导。
然而,通过 RL 实现这种 AI 突破的旅程充满了计算挑战。为 AI 模拟环境需要大量的计算资源。GPU 并行化仿真环境的出现,如英伟达的 Isaac Gym、Google 的 Brax 和 JAX-LOB,在克服这些障碍方面起到了关键作用。通过利用 GPU 并行化仿真环境,这些平台实现了性能提升,范围从 100 倍到 250,000 倍不等,使 RL 的计算方面更加可行和高效。由于 AI 训练的瓶颈通常是 CPU-GPU 之间传递数据的通信带宽,GPU 并行化实现了这些速度改进,并已成为 RL 研究界的行业标准。
在快速发展的人工智能世界中,GPU-EVM 作为一个 GPU 并行化仿真环境,在区块链生态系统内直接促进了 AI 代理的训练。其中一个引人注目的应用是在金融行业,GPU-EVM 可以革新实时欺诈检测系统。历史显示了这些系统的重要性,Max Levchin 开发了 PayPal 的第一个防欺诈机制,以防止公司破产。通过使金融 AI 能够在短短几秒钟内模拟和分析数百万笔交易,它可以以前所未有的速度和准确度识别出欺诈活动的异常模式。这种能力,以前可能需要几天时间才能实现,代表了金融机构如何防范欺诈的重大转变。通过将 AI 代理与 EVM 集成到 GPU-EVM 中,为在区块链领域内应用强化学习(RL)原理开辟了新途径。在这里,AI 代理通过根据预定义的奖励函数准确识别欺诈交易来学习和改进。
L2 加速 / 仿真
第二层解决方案的出现对于提高以太坊的吞吐量至关重要,从而促进其在主流应用,特别是支付领域的采用。通过在主要以太坊区块链(第一层)之外处理交易,L2 显著增强了网络的容量,同时保持了其安全性和分散性的基本原则。与传统基于 CPU 的系统不同,GPU-EVM 独立运行,能够无缝集成和加速现有的 L2 解决方案。这种加速可以通过各种方法实现,包括优化视图函数和应用蒙特卡洛树搜索等算法,以实现更高效的区块构建和交易排序。
然而,在 L2 加速的背景下,利用并行 EVM 的作用是复杂的,需要认真对待。通过并行 EVM 直接加速 L2 并不像看起来那么简单。要真正利用并行 EVM 的能力,必须共同努力创新 L2 解决方案的设计和它们的数据库。这一点被诸如下面的工作所强调:
尽管将 GPU-EVM 与 L2 解决方案集成的细微差别极具前景,但需要注意的是还有其他挑战需要解决。这一努力的主要瓶颈包括解决与存储相关的限制、管理长链的相互依赖交易以及减少状态膨胀成本。单单 GPU-EVM 无法解决所有这些问题。因此,在 L2 加速背景下,通过创新设计 L2 解决方案和支撑它们的数据库,共同努力是克服这些障碍并充分实现 GPU-EVM 的好处的关键。
DeFi 仿真 / 模糊测试
GPU-EVM 的基础性能提升为 DeFi 仿真和模糊测试带来了变革性的改变。这种数据处理能力的显著提升使得可以发现以前未考虑到的 DeFi 策略和协议设计的边缘情况,揭示出可能隐藏的新漏洞。为了说明这一进展的重要性,可以将传统基于 CPU 的方法比作水枪,而 GPU-EVM 更像是强大的水龙头,提供了更有效的灭虫手段。
由于 GPU-EVM 的基础性能提升,运行在这个平台上的模糊器可以深入探索并以惊人的速度运行,几秒钟内识别出边缘情况。这与基于 CPU 的模糊器形成了鲜明对比,后者可能需要几周甚至几个月才能发现相同的问题。在 GPU-EVM 之上运行这些高级模糊器的能力,允许对智能合约进行持续监控,特别是那些在实际生产中的合约。这些自动化系统旨在不懈地挑战智能合约,试图提前数步预见潜在的漏洞,就像一个战略性的象棋游戏,其最终目标是确保最高水平的安全性。
我们即将推出的产品体现了这种前沿的 DeFi 仿真和模糊测试方法。敬请期待,这将重新定义智能合约安全性和韧性的标准。
关于 GatlingX
GatlingX 是一个应用基础设施和人工智能实验室,专注于开发重型技术基础设施。我们的使命是创建能够在深层基础设施层次上操作的各种区块链应用产品。
我们相信,有一些极端困难的技术问题,是区块链行业不愿意解决的,因为它们太困难了。快速且廉价的安全性、计算性能和速度是蓬勃发展的区块链生态系统的必要先决条件,但同样也是极其困难的问题,会带来很多痛苦。我们相信,除非我们将世界上最优秀的问题解决者聚集起来解决它,否则没有人会解决这些问题。
我们致力于推动人工智能、GPU、区块链和分布式计算等领域的最新技术发展,这些领域对推动全球技术进步至关重要。
我们是一群狂热的人:如果我们能买到现成的东西,我们就会这样做。如果不能,我们就会自己动手建造。
使用 GPU-EVM
GPU-EVM 目前处于私人早期访问阶段,因为我们正在扩大 GPU 容量。如果您有兴趣在工程工作中使用 GPU-EVM,请填写此表格以加入等待列表。
我们的团队规模小,但极具才华。我们的创始团队由牛津大学校友组成,他们在基础设施、应用人工智能方面取得了突破性成就,曾在 Crowdstrike、Wayve、Citadel Securities 等公司工作,并创造了影响深远的项目,如 ZKMicrophone 和 Graphite。













