
智能合约架构
我们将为币安网络上的合约扩展额外功能,以实现在以太坊一侧接收代币时,可清算币安网络上的代币。
更多信息将由附加合约提供,如字体、背景、图像链接等,以维持元数据的原貌,其中将存储指向附加元数据的链接。
在网络间转移代币时,元数据链接将原封不动。
网络
构建网络交互的关键标准是确保高水平的系统可用性,包括在高峰负载时段。鉴于大部分功能是为了交付现有内容,而非处理发送数据,因此默认使用以下网络工作方式:
• CloudFront(CF)作为缓存和CDN的主要提供者,对交互进行处理
• 用户对站点的初次请求生成SSR,其结果缓存在CF层级
• 通过后端API请求主数据。数据缓存必须在后端API一侧实现。
• 代币元数据及其图像必须从IPFS网络获取。为优化访问,还应使用CloudFlare IPFS网关
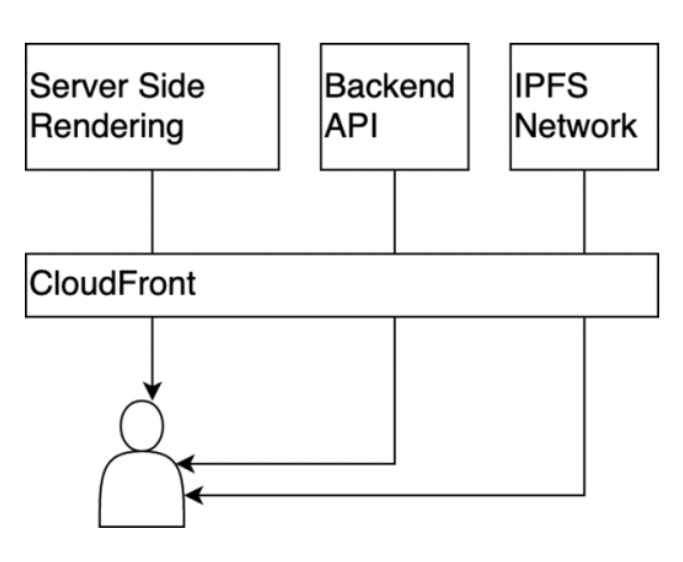
服务器端提交 /后端API /IPFS网络
CloudFront
基于文本的人工智能技术概述
Quoth数据集的基本AI技术路线如下:基于AI/ML(人工智能/机器学习)处理原有和新NFT,建立网罗一切的文本内容(从图像或视频中提取的文本)索引。根据自动发现的类别(标签)对原有和新条目(数以百万)进行分类。基于对现有NFT和条目的分析确定类别。为新创建的NFT条目及原有NFT文本执行原创性(剽窃)检查。
范围与实施

组件关系
原有NFT /铸造条目/语义索引/文本提取服务
全部索引数据库
提交条目/原创性检查/原创标签(Is_Original_tags)
原创性(剽窃)检测
原创性检测组件将执行两类核查:文字比对:如果两个条目的标点符号和拼写错误一致,则被视为相同条目。经现有条目和NFT(名称和描述)训练的ML模型会对常见拼写错误进行自动纠正。
释义检测:如果两个条目具有相似的语义表征,且相似度达到一定门槛,则视为相同条目。项目实施中将对语义表征的门槛及精准类别进行优化。后续实施阶段将利用人工“研究报告”结果进一步优化算法。
注:上述检查仅针对单语种(可能的翻译将被忽略)。这方面有一个重要用例,即条目作者或能以不同语言铸造同一条目的多个版本。
我们将基于专有技术Semantic Maps(一种基于语义的主题模型)为条目添加标签。在此,(目标)数据集和文档集这两个术语可互换使用,均表示分析的文本集,例如条目或NFT描述集。
为条目添加标签
添加标签的步骤如下:
• 对自定义语言模型进行自监督训练(词语嵌入);对于小数据集(几GB以内的文本),一些合适的大文本数据集(如维基百科)会被添加至目标数据集中。
• 基于语言模式,计算数据集中每个文档的语义表征。
• 在数据集语义空间中找出若干集群,锁定不同的“意义岛”。
• 进行数据集视觉检查时,需要计算出文档集的二维图,以将主题、关键字和文档关联起来。注:二维图中的主题仅大致对应视觉集群(“意义团块”)。
• 可选择人工为找出的集群赋予有意义的名称。
• 对于长文档,首先要对原始文档的片段(10-200单词)执行前面4个步骤,并依次重复,以生成“文档类别”。
目前,该方法的关键要求是要有足够大的文本集,并涵盖多元化的内容。但即使只有很小的文本集,也可使用为“黄金”文档集计算出的主题添加标签,例如针对一般性文本的维基百科或针对生物医学文本的PubMed。
文本提取
• 鉴于现有NFT中使用的字体、语言和艺术效果差别巨大,建议使用现有云服务执行文本提取工作。
• Quoth将使用作为基本服务的谷歌视觉API(支持数十种语言、手写文本及视频),但也会检视其他服务,例如微软Azure和亚马逊AWS的OCR服务。
• 提取文本后,语言不支持的文本、拼写错误过多的文本以及篇幅太短的文本将被舍弃。
• 后期处理过程会纠正拼写错误。
Quoth拥有扎实的技术,我们希望建立更多合作关系,以在NFT世界架起桥梁。请加入TG群了解更多信息:https://t.me/Quoth_CN;https://t.me/Quoth_ai
——————
Quoth是人工智能NFT索引协议、API以及链上预言机B2B服务提供商。人人都可使用Quoth APP搜索、认证和桥接任何NFT。协议、NFT市场和其他项目均可使用Quoth的API及预言机服务对现有的一切NFT进行数据和真伪验证。
$QUOTH是协议原生代币,用于为API节点网络提供支持。执行神经网络训练、桥接和真伪验证工作的用户均可获得$QUOTH奖励。Quoth的流动性挖矿将通过使用流动性质押的创新广告模式进行。Quoth多链节点Ravens将由独立节点运营者运营。人人均可运行Raven节点,并接收验证和搜索费用。Ravens与神经网络训练者合作,为AI安排必要的数据,进而为预言机提供必要的NFT信息,以维护索引,为Defi和Web3验证NFT协议API。













