





加入 PolkaWorld 社区,共建 Web 3.0!

Web3.0 的愿景是让互联网更加去中心化。
毫无疑问,提供安全、高可用性、低成本和易于使用的去中心化存储基础设施,将成为 Web3.0 应用的重要组成部分。
这次 PolkaWorld 专访,我们邀请到了波卡生态永久存储项目 Canyon 创始人徐留成,来聊聊为什么我们需要永久存储网络,Canyon 会如何为波卡生态和 Web3.0 带来更加优秀的存储基础设施。
PW:能不能用比较通俗的语言介绍一下 Canyon 是做什么的?
留成:Canyon 是基于 Substrate 的波卡生态永久存储网络,这个项目受到了 Arweave 的很大启发,你可以简单把 Canyon 看作是波卡生态里面 PoS 版本的 Arweave。
通过将 PoA(Proof of Access)共识与 PoS 系统相结合,Canyon 极大地减少了存储矿工的准入门槛,并以一种激励驱动的方式鼓励矿工存储尽可能多的数据来赢得更多奖励。作为一个新项目,除了一些由于区块链技术迭代天然带来的优越性,Canyon 还在永存数据的持久率(durability)和冗余度(redundancy)方面进行了创新和改进。我们的最终愿景是成为一个在 Web3.0 时代真正实用并且可持续的存储基础设施。
PW:为什么会想去做一个永久存储网络?
留成:这个问题可以分为两点来看,一个是为什么选择存储,另一个为什么选择永久存储。
先来看第一个问题,为什么选择区块链存储这个方向。想法其实很简单,当区块链的计算问题解决以后,毫无疑问将会产生更多的存储需求。在计算机科学领域,计算与存储是永远分不开的两个问题。对于区块链也是一样, 目前整个区块链行业其实还是在努力解决去中心化计算的问题,简单来说也就是 TPS 的问题。最早在区块链上做通用计算的是以太坊,我们发现去中心化计算真的有用,但是当以太坊生态慢慢起来以后同时也发现,以太坊的计算功能好用但是也完全不够用。所以后来出现了很多项目来试图解决计算问题,比如波卡、Solana、Near 等等。可以说这些项目在计算方面已经有了不少进步,TPS 有了很大提高。随着未来区块链计算问题得到进一步改善,我们相信加密世界将催生出不仅仅是 DeFi 应用, 而是更加丰富多样的 DApps, 这些去中心化应用也将必然催生出更多的去中心化存储需求。
第二个问题,为什么要选择永久存储。一个是当我们研究了 Arweave 以后,我们还是很认同它关于永久存储的一些看法。然后也确实发现了一些永久存储的需求,比如目前大火的 NFT, 以及一些基于永久存储网络解决链上计算问题的项目,比如 everFinance, 他们利用一个永存网络实现将链上的计算完全放到链下, 我们也觉得这是一个值得尝试的方向。还有一些区块链历史也会需要永久存储, 比如以太坊要从 PoW 迁到 PoS,以太坊基金会就提出了一个方案希望将以太坊整个 PoW 的历史保存在一个存储网络中。由此,我们认为永久存储在未来的 Web3.0 也必然会占有一席之地, 所以最终选择了永存这个方向。
PW: 当前的存储项目如何应对当前的去中心化存储需求十分匮乏的情况?
留成:首先真实的去中心化存储需求匮乏很大原因还是由于整个加密行业仍然处于早期,一个存储项目自身其实很难解决存储需求增长的问题,还是要靠整个加密行业不断发展,人们对于区块链的认知不断加深,诞生越来越多在云盘、视频、社交等方面更加丰富的去中心化应用才能催生真正的去中心化存储需求。
比如我们可以设想这样一个场景,当前的 Web2.0 时代,我们登录每个网络都可能会需要输入一些个人信息,那么未来我们可能可以将个人信息以一种加密的方式存储到一个存储网络,每当一个应用需要读取部分信息的时候,需要向用户发起读取请求,如果用户确实想开放某些数据的话,在确认后应用可以获取相关数据并进行解密。这样就避免了当个人信息托管到一个中心化实体,真正实现了拥有个人数据的所有权。当前的存储项目在目前真实存储需求匮乏的情况下,只要做到不鼓励向网络中存储垃圾数据进行获利的行为,让数据存储随着行业自然生长就可以了。
PW:你认为目前市场上其他的一些存储方案,比如 IPFS、Arweave 等,存在哪些问题?
留成:首先谈谈 Filecoin。Filecoin 其中一个问题是它实现数据存储的成本很高,它采用了零知识证明的手段保证了矿工在规定时间内正确存储了数据,但是零知识证明方案导致矿工矿机的硬件成本非常高。另外有个很简单的原则,如果厂商所提供的一个服务自身成本很高,那么这种高成本最终必然会叠加到用户身上。抛开项目早期的贴补政策,从逻辑上来说,Filecoin 这么高的存储成本最终是一定是由客户来买单的, Filecoin 自然也就无法提供真正低成本的数据存储服务。
Filecoin 另外一个问题是网络中存储了大量的垃圾数据。矿工为了为了逐利不断地向网络中存储垃圾数据来提高算力, 目前整个 Filecoin 网络的存储容量已经达到了 EiB 级别, 显然这其中 99%都是无效的垃圾数据。相比之下,Arweave 现在全网一共才 11 T 的数据,中间差了 6 个数量级。
与 Filecoin 相比,Arweave 的 PoA 是一种概率性的存储共识,以一种近乎零成本的方式实现了激励数据存储的效果。但是 Arweave 将 PoA 共识建立在 PoW 之上,抛开 PoW 的浪费电力,速度慢,没有最终性等问题,在数据方面,Arweave 只能基于概率的方式鼓励矿工存储数据,但是无法保证数据不会丢失,用户数据存储本质上无法得到任何保障。
第二个问题是 Arweave 没有在协议层保证数据的可检索性,也就是保证数据可读,虽然它的白皮书提出了 wildfire 等依靠网络节点自身的一些行为进行约束,但是该机制实际上并没有实现。此外,由于提供数据读取服务所消耗的带宽并非零成本,要求节点免费提供检索服务也不太合理。一个存储网络如果无法保证用户能够往网络中获取到数据,那么就是没有价值的。
Arweave 还存在类似于自私挖矿的问题, 就是整个网络中有一些隐藏数据是其他所有人都读不到的,节点可以将某些数据藏起来获得一些挖矿优势。虽然 Arweave 最初这样设计,是希望激励矿工存储更稀少的数据来获得挖矿优势,从而增加稀少数据的冗余度,但实际上最终演变成了可以自私挖矿的一个手段。
最后一个问题就是存储矿池的问题。存储矿池是什么意思呢?Arweave 可能最终会演变成为只有一个存储矿池的情况。因为 PoA 要求只要能获取到数据就好,那么作为一个节点,我可以本地不存这个数据,而是加入一个很大的矿池,当需要数据就通过网络来矿池读取,这就导致数据可能在全网只存了一份。如果数据只有一份,一旦存储节点出现任何问题,数据就永久丢失了。
总结一下,在存储的这个角度,Arweave 在数据持久率、可检索性、数据冗余度上均都无法没有做到任何的理论保障。
PW:那么 Canyon 是如何解决以上这些问题的呢?
留成:Arweave 使用的是 “PoW + PoA”,而它的种种问题主要都来源于 PoW, 在 PoW 中无法知道有多少个矿工,也无法对于存储矿工所提供的存储服务施加任何限制,所有矿工都是随时随地随意加入。
Canyon 选择了 “PoS + PoA”,对于一个 PoS 系统,我们可以知道所有节点的数量,也可以对节点的存储服务上做限制,从而能够实现一个高数据持久率。具体方案是通过 PoS 给节点施加一个最低的存储比例的限制, 也就是要求每个节点至少要存储一个最低比例的全网数据。然后这就变成了一个简单的概率问题,假设有 100 个节点,要求每个节点至少存储所有数据的 20%,那么我们很容易算出某个数据不存在的概率是多大, 就是 1 减去所有人都没有存储改数据的概率。
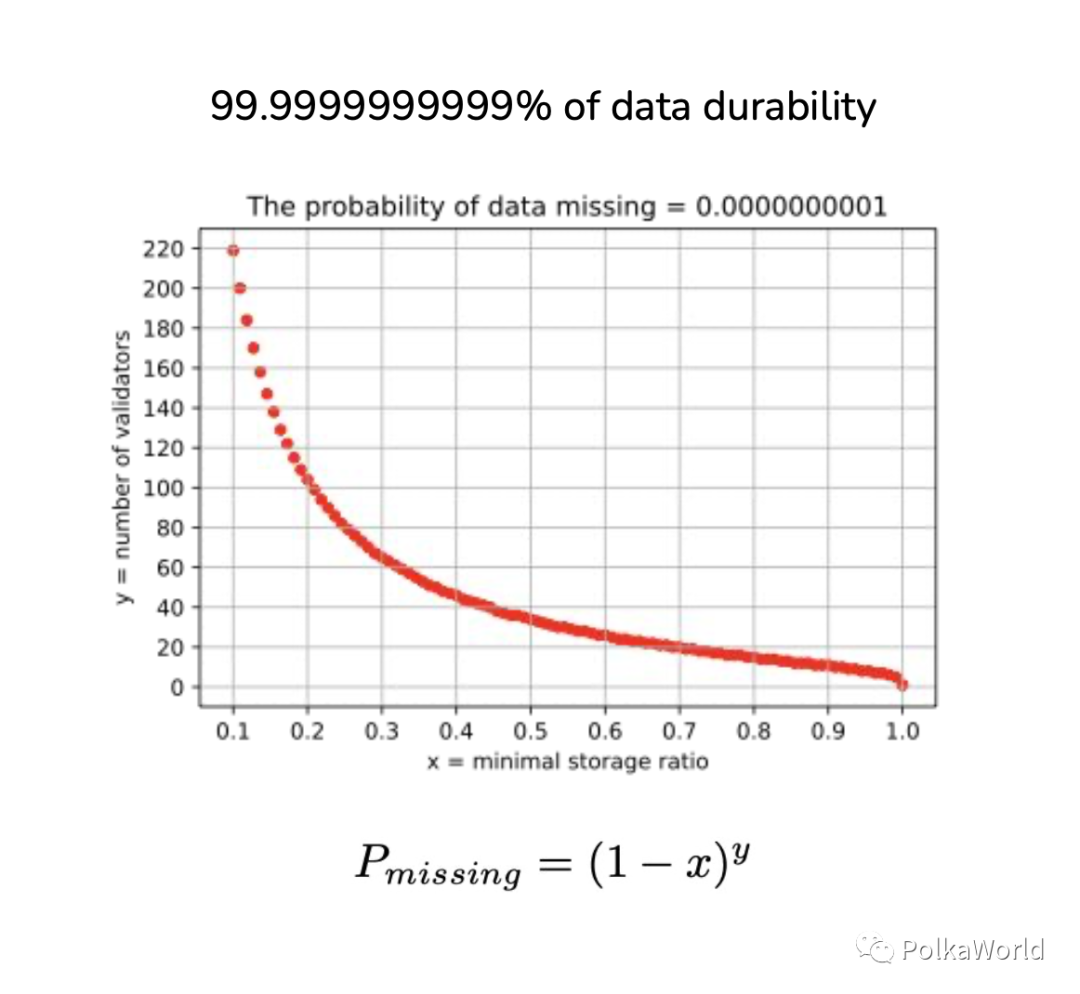
通过这个机制,在 200 个节点的情况下,每个人至少存储 10% 的数据就可以做到 12 个 9 的数据持久率,如果每个人存储 90% 的数据的话,那么只需要十几个节点就可以做到。相比而言,亚马逊只有 11 个 9 的数据持久率保证。所以说,虽然我们的数据持久率同样是概率性的,但是我们的
数据丢失概率有理论下限
,而同样使用 PoA 但是选择 PoW 的 Arweave 却无法做到。
数据冗余度方面,我们是通过读取付费来间接解决。首先我们认为带宽不是 0 成本的,检索(读取)数据也是有成本的。为什么读取收费可以解决数据冗余度问题?因为当这个数据读取需要付费的时候,对于节点来说就是可盈利的,于是节点就有动机去存储一些有频繁读取需求的数据。那么如果一个数据被越频繁地读取,它在网络中会自然的拥有越多的备份,因为越多的人会乐意去存它,有任何人来读,我可以提供给他,我可以挣钱。这个机制通过一种由市场驱动的方式实现自适应式的数据冗余度。
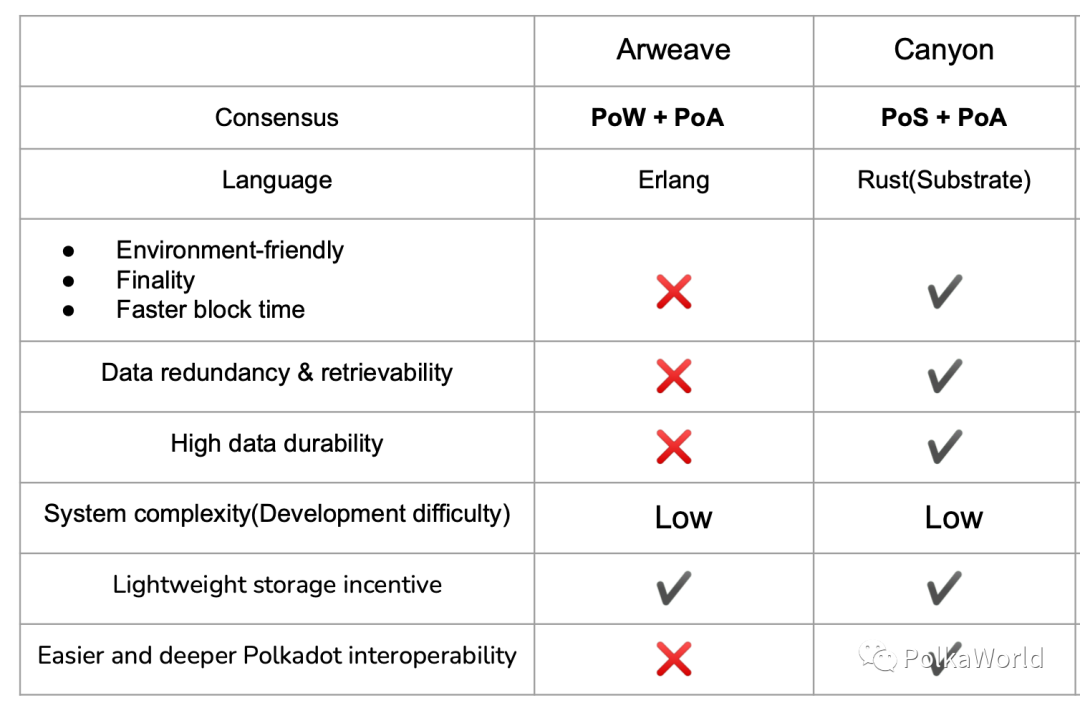
总结起来,首先,不管是热数据还是冷数据,PoS+PoA 的高数据持久率保证了数据至少存一份,也就是不会丢。通过数据读取收费解决数据存得尽量多的问题, 如果某个数据经常被用到,经常被读取,那么很自然地它就应该拥有更多的数据备份, 也间接实现了存储资源上的更合理分配。
PW: Canyon 的存储挖矿对矿工有什么要求?
留成:得益于超轻量级的存储共识 (PoA), Canyon 对于矿工的硬件要求极低,不需要任何的矿机,不需要指定类型的硬件,只需要任意运行一个普通的 PoS 节点配置加上一定容量的硬盘就可以参与挖矿。
PW:Canyon 的代币有什么用途?
留成:普通用户可以使用代币支付 Gas 费,支付存储和检索服务的手续费,参与 Staking 和链上治理等。对于节点用户,代币会激励节点积极参与网络共识和提供高质量存储服务,另外节点还可以通过提供检索服务获得检索服务费等。
PW:Canyon 项目是从什么时候开始的?目前的进展怎么样了?
留成:我们是在 2020 年底开始研究区块链存储这个方向,然后今年 3 月份左右第一次申请了 Web3 基金会 Grant。到目前为止我们已经拿到了两轮 Web3 基金会 Grant,并且都已经成功交付。我们的第二轮 grant 已经基于 Substrate 框架实现了 PoA 共识, 并实现了与 PoS 的融合。
目前整个项目的一些技术难点其实差不多算是已经调研完毕,接下来的融资、组建团队如果顺利的话,预计能在 1-2 年内推出主网。
PW:Canyon 为什么选择用 Substrate 开发?
留成:一个是本身我们在 Substrate 生态里面也好几年了,比较熟悉这个生态。其次是 Substrate 框架还是非常有用的。还有就是看好波卡生态,期待以后可以跟波卡生态项目有更好的互操作性。另外当时我们最早在研究这个项目的时候,波卡里面还没有做永存的存储项目,所以我们是波卡生态里第一个做这个方向的。
本文来自 “PolkaWorld 专访计划”,该计划旨在帮助更多人了解波卡生态新项目,如果你也希望 PolkaWorld 来采访你,可以点此了解详情和申请。
欢迎学习 Substrate: https://substrate.dev/关注 Substrate 进展:https://github.com/paritytech/substrate关注 Polkadot 进展:https://github.com/paritytech/polkadot












 APP
APP 
