原文:Aptos Labs
编译:Aptos Global
https://arxiv.org/pdf/2306.03058.pdf

概述
1)Aptos labs 已经解决了DAG BFT中两个重要的开放问题,大大地减少了延迟,并且首次消除了确定性实际协议中对暂停的需求。总的来说,在无故障情况下将Bullshark的延迟改进了40%,在故障情况下改进了80%。
2)Shoal 是一个框架,通过pipelining and leader reputation增强任何基于 Narwhal 的共识协议(例如,DAG-Rider、Tusk、Bullshark)。流水线通过每轮引入一个锚点来减少 DAG 排序延迟,领导者声誉通过确保锚点与最快的验证节点相关联来进一步改善延迟问题。此外,领导者声誉使 Shoal 可以利用异步 DAG 构造来消除所有场景中的超时。这允许 Shoal 提供我们命名为普遍响应的属性,它包含通常需要的Optimistic 响应。
3)我们的技术非常简单,它涉及到按顺序一个接一个地运行底层协议的多个实例。因此,当用Bullshark实例化时,我们得到一群正在进行接力赛的「鲨鱼」。
动机
在追求区块链网络的高性能时,人们一直关注降低通信复杂性。 然而,这种方法并没有导致吞吐量的显著提高。 例如,在早期版本的 Diem 中实现的 Hotstuff 仅实现了 3500 TPS,远远低于我们实现 100k+ TPS 的目标。
然而,最近的突破源于认识到数据传播是基于领导者的协议的主要瓶颈,并且它可以从并行化中受益。Narwhal 系统将数据传播与核心共识逻辑分离,并提出了一种架构,其中所有验证者同时传播数据,而共识组件仅订购较少量的元数据。Narwhal 论文报告了 160,000 TPS 的吞吐量。
在之前的文章中,我们介绍了 Quorum Store。我们的 Narwhal 实现将数据传播与共识分离,以及我们如何使用它来扩展我们当前的共识协议 Jolteon。Jolteon 是一种基于领导者的协议,结合了 Tendermint 的线性快速路径和 PBFT 风格的视图更改,可将 Hotstuff 延迟降低 33%。然而,很明显,基于领导者的共识协议无法充分利用 Narwhal 的吞吐量潜力。尽管将数据传播与共识分开,但随着吞吐量的增加,Hotstuff/Jolteon 的领导者仍然受到限制。
因此,我们决定在 Narwhal DAG 之上部署 Bullshark,一种零通信开销的共识协议。不幸的是,与 Jolteon 相比,支持 Bullshark 高吞吐量的 DAG 结构带来了 50% 的延迟代价。
在这篇文章中,我们介绍了 Shoal 如何实现大幅减少 Bullshark 延迟。
DAG-BFT 背景
让我们从理解这篇文章的相关背景开始。关于 Narwhal 和 Bullshark 的详细描述请参考 DAG meets BFT 帖子。
https://decentralizedthoughts.github.io/2022-06-28-DAG-meets-BFT/
Narwhal DAG 中的每个顶点都与一个轮数相关联。为了进入第 r 轮,验证者必须首先获得属于第 r-1 轮的 n-f 个顶点。每个验证者每轮可以广播一个顶点,每个顶点至少引用前一轮的 n-f 个顶点。由于网络异步性,不同的验证者可能会在任何时间点观察到 DAG 的不同本地视图。下面是一个可能的局部视图的图示:
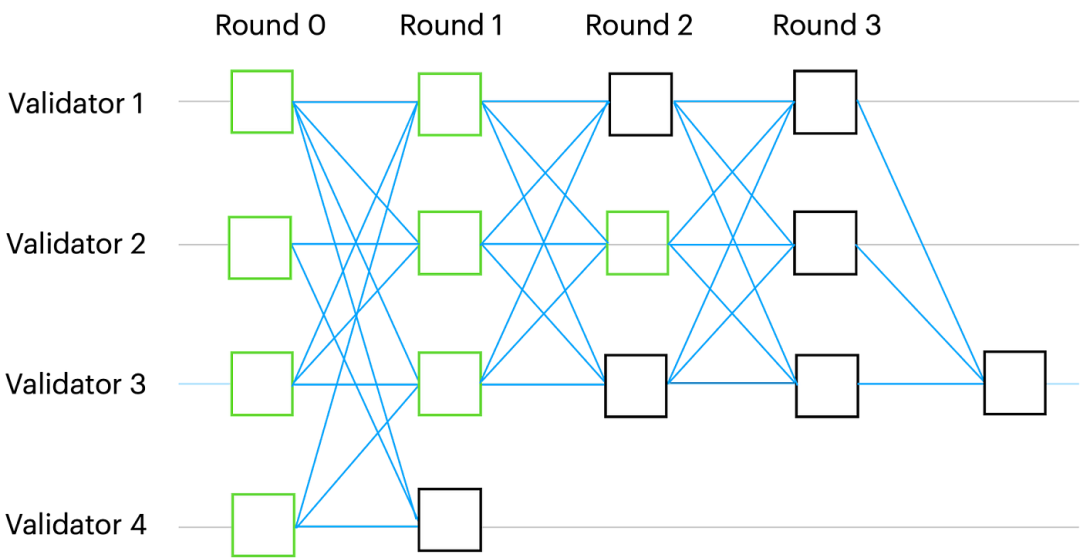
图1:第 2 轮验证节点 2 识别的顶点的因果历史以绿色突出显示
DAG 的一个关键属性不是模棱两可的:如果两个验证节点在它们的 DAG 本地视图中具有相同的顶点 v,那么它们具有完全相同的 v 因果历史。
Total Order
可以在没有额外通信开销的情况下就 DAG 中所有顶点的总顺序达成一致。 为此,DAG-Rider、Tusk 和 Bullshark 中的验证者将 DAG 的结构解释为一种共识协议,其中顶点代表提案,边代表投票。
虽然 DAG 结构上的群体交集逻辑不同,但所有现有的基于 Narwhal 的共识协议都具有以下结构:
1)Predetermined anchors,每隔几轮(例如,Bullshark 中的两轮)就会有一个预先确定的领导者,领导者的顶点称为锚点;
2)Ordering anchors, 验证者独立但确定性地决定订购哪些锚点以及跳过哪些锚点;
3)Order causal histories,验证者一个一个地处理他们的有序锚点列表,并且对于每个锚点,通过一些确定性规则对其因果历史中所有先前无序的顶点进行排序。
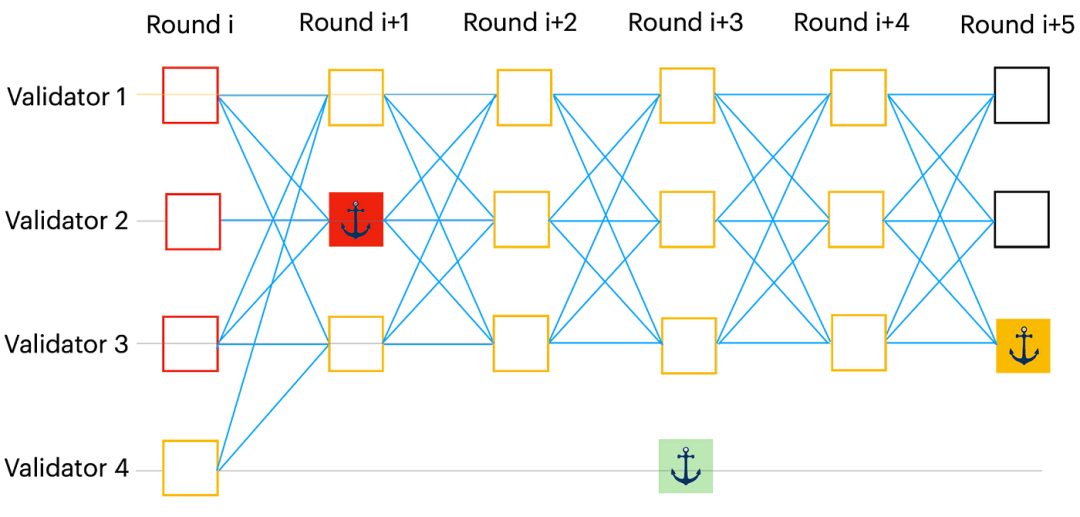
图二:Bullshark 协议中 DAG 的可能局部视图的图示。在此示例中,红色和黄色锚点被排序,而绿色(不在 DAG 中)被跳过。因此,为了对 DAG 进行排序,验证节点确定性地首先对红色锚点的因果历史进行排序,紧随其后的是黄色锚点。
满足安全性的关键是确保在上面的步骤 (2) 中,所有诚实的验证节点创建一个有序锚点列表,以便所有列表共享相同的前缀。在Shoal,我们对上述所有协议做出以下观察:
所有验证者都同意第一个有序的锚点。
Bullshark 延迟
Bullshark 的延迟取决于 DAG 中有序锚点之间的轮数。 虽然 Bullshark 最实用的部分同步版本比异步版本具有更好的延迟,但它远非最佳。
问题 1:平均块延迟。在 Bullshark 中,每个偶数轮都有一个锚点,每个奇数轮的顶点都被解释为投票。常见情况下,需要两轮 DAG 才能订购锚点,然而,anchor 的因果历史中的顶点需要更多的轮次来等待 anchor 被排序。在常见情况下,奇数轮中的顶点需要三轮,而偶数轮中的非锚点顶点需要四轮(见图 3)。
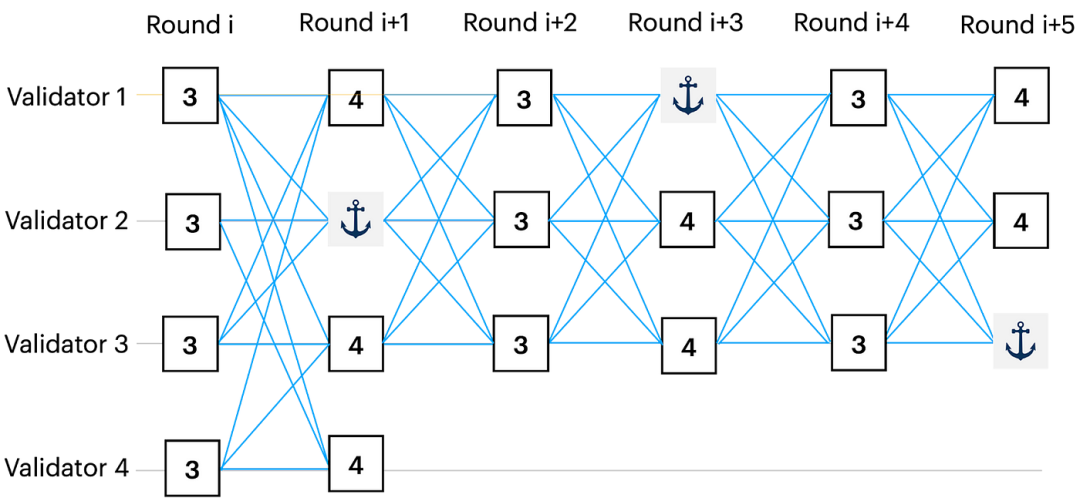
图 3:在常见情况下,第 i+1 轮中的锚点需要排序两轮。第 i 轮中的顶点同时排序,因此它们的延迟为三轮。然而,第 i+1 轮中的顶点必须等待下一个锚点被排序(第 i+3 轮中的那个),因此它们的排序延迟为四轮。
问题 2:故障案例延迟,上述延迟分析适用于无故障情况,另一方面,如果一轮的领导者未能足够快地广播锚点,则无法对锚点进行排序(因此被跳过),因此前几轮中所有未排序的顶点必须等待下一个锚点被排序。这会显着降低地理复制网络的性能,特别是因为 Bullshark 超时使用来等待领导者。
Shoal 框架
Shoal 解决了这两个延迟问题,它通过 pipelining 增强了 Bullshark(或任何其他基于 Narwhal 的 BFT 协议),允许在每一轮中都有一个锚点,并将 DAG 中所有非锚点顶点的延迟减少到三轮。Shoal 还在 DAG 中引入了零开销领导者声誉机制,这使得选择偏向于快速领导者。
挑战
DAG协议的背景下,流水线和领导者声誉被认为是困难的问题,原因如下:
1)以前的pipelining试图修改核心 Bullshark 逻辑,但这从本质上讲似乎是不可能的
2)Leader Reputation 在 DiemBFT 中引入并在 Carousel 中正式化,是根据验证者过去的表现动态选择未来领导者(Bullshark 中的锚)的想法。 虽然在领导者身份上存在分歧并不违反这些协议中的安全性,但在 Bullshark 中,它可能导致完全不同的排序,这引出了问题的核心,即动态和确定性地选择轮锚是解决共识所必需的,而验证者需要就有序历史达成一致以选择未来的锚。
作为问题难度的证据,我们注意到Bullshark的实现,包括目前在生产环境中的实现,都不支持这些特性。
协议
尽管存在上述挑战,但正如俗话所说,事实证明解决方案隐藏在简单的背后。
在 Shoal 中,我们依靠在 DAG 上执行本地计算的能力,并实现了保存和重新解释前几轮信息的能力。凭借所有验证者都同意第一个有序锚点的核心洞察力,Shoal 按顺序组合多个 Bullshark 实例对它们进行流水线处理,使得(1)第一个有序锚点是实例的切换点,以及(2)锚点的因果历史用于计算领导者的声誉。
Pipelining
与 Bullshark 类似,验证者先验地就潜在的锚点达成一致,即,有一个已知的映射 F:R -> V 将轮次映射到领导者。 Shoal 一个接一个地运行 Bullshark 的实例,这样对于每个实例,锚由映射 F 预先确定。每个实例都订购一个锚,这会触发切换到下一个实例。
最初,Shoal 在 DAG 的第一轮启动 Bullshark 的第一个实例并运行它直到确定第一个有序锚点,比如在第 r 轮。 所有验证者都同意这个锚点。 因此,所有验证者都可以确定地同意从第 r+1 轮开始重新解释 DAG。 Shoal 只是在第 r+1 轮启动了一个新的 Bullshark 实例。
在最好的情况下,这允许 Shoal 在每一轮都订购一个锚。 第一轮的锚点按第一个实例排序。 然后,Shoal 在第二轮开始一个新的实例,它本身有一个锚点,该锚由该实例排序,然后,另一个新实例在第三轮中订购锚点,然后该过程继续。 请参见下图的说明:
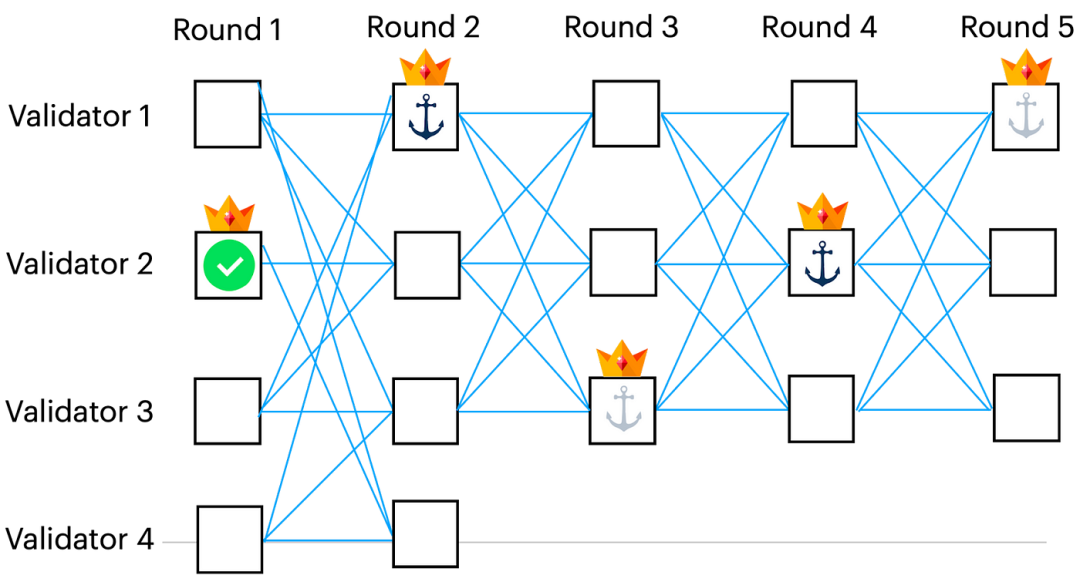
图 4:与 F 确定的领导者对应的顶点用皇冠标记,Bullshark 的第一个实例首先用第 1、3 和 5 轮中的锚点解释 DAG,Bullshark 确定第 1 轮中的锚点(用绿色复选标记标记)是第一个在第一个实例中被排序的。(请注意,在一般情况下,可以跳过此锚点,而其他一些锚点将首先被排序。)然后,第一个实例的其余部分将被忽略,Bullshark 的新实例从第 2 轮开始,锚点标记为 在第 2 轮和第 4 轮中。
Leader reputation
在 Bullshark 排序期间跳过锚点时,延迟会增加。 在这种情况下,Pipelining技术无能为力,因为在前一个实例订购锚点之前无法启动新实例。 Shoal 通过使用信誉机制根据每个验证节点最近活动的历史为每个验证节点分配一个分数来确保将来不太可能选择相应的领导者来处理丢失的锚点。 响应并参与协议的验证者将获得高分, 否则,验证节点将被分配低分,因为它可能崩溃、缓慢或作恶。
其理念是在每次分数更新时,确定性地重新计算从回合到领导者的预定义映射F,偏向于得分较高的领导者。为了让验证者在新的映射上达成一致,他们应该在分数上达成一致,从而在用于派生分数的历史上达成一致。
在 Shoal 中,流水线和领导声誉可以自然结合,因为它们都使用相同的核心技术,即在就第一个有序锚点达成一致后重新解释 DAG。
事实上,唯一的区别是,在第 r 轮中对锚点进行排序后,验证者只需根据第 r 轮中有序锚点的因果历史,从第 r+1 轮开始计算新的映射 F'。然后,验证节点从第 r+1 轮开始使用更新的锚点选择函数 F' 执行 Bullshark 的新实例。请参见下图:
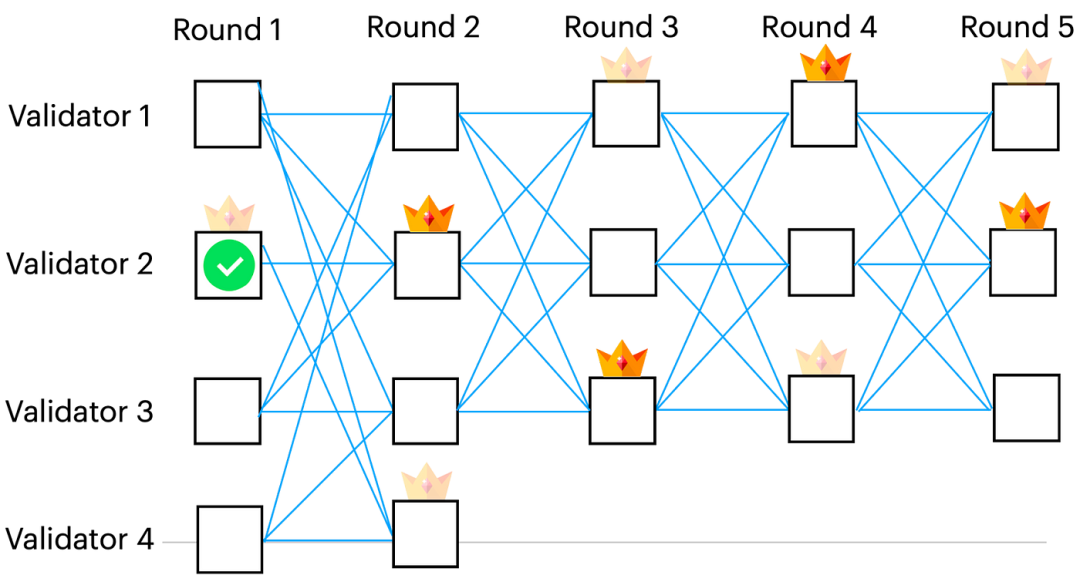
图 5. 与 F 确定的领导者对应的顶点用透明冠标记。Bullshark 的第一个实例在第 1 轮中订购了一个锚点,用绿色复选标记标记,然后,根据 anchor 的因果历史中的信息计算新的映射 F'。由 F' 决定的领导人以彩色皇冠为标志。
没有更多超时
超时在所有基于leader的确定性部分同步BFT实现中起着至关重要的作用。然而,它们引入的复杂性增加了需要管理和观察的内部状态的数量,这增加了调试过程的复杂性,并且需要更多的可观察性技术。
Timeout 也会显着增加延迟,因为适当地配置它们非常重要,并且通常需要动态调整,因为它高度依赖于环境(网络)。在转移到下一个领导者之前,该协议会为有故障的领导者支付完整的超时延迟惩罚。因此,超时设置不能过于保守,但如果超时时间太短,协议可能会跳过好的领导者。例如,我们观察到,在高负载情况下,Jolteon/Hotstuff 中的领导者不堪重负,并且在他们推动进展之前超时就已到期。
不幸的是,基于领导者的协议(如 Hotstuff 和 Jolteon)本质上需要超时,以确保每次领导者出现故障时协议都能取得进展。如果没有超时,即使是崩溃的领导者也可能永远停止协议。由于在异步期间无法区分有故障的领导者和缓慢的领导者,超时可能会导致验证节点在没有共识活跃度的情况下查看更改所有领导者。
在 Bullshark 中,超时用于 DAG 构造,以确保在同步期间诚实的领导者将锚点添加到 DAG 的速度足够快,以便对它们进行排序。
我们观察到 DAG 构造提供了一个估计网络速度的“时钟”。在没有暂停的情况下,只要 n-f 个诚实的验证者继续向 DAG 添加顶点,轮次就会继续前进。虽然 Bullshark 可能无法以网络速度排序(由于领导者有问题),但 DAG 仍然以网络速度增长,尽管一些领导者有问题或网络是异步的。最终,当一个无故障的领导者足够快地广播锚点时,锚点的整个因果历史将被排序。
在我们的评估中,我们比较了 Bullshark 在以下情况下有和没有timeout:
1)快速领导者,意味着至少比其他验证者更快。在这种情况下,两种方法都提供相同的延迟,因为锚是有序的并且不使用超时。
2)错误的领导者,在这种情况下,没有暂停的 Bullshark 提供了更好的延迟,因为验证节点将立即跳过它的锚点,而有暂停的验证者将在继续之前等待它们的到期。
3)缓慢的领导者,这是 Bullshark 超时性能更好的唯一情况。这是因为,如果没有暂停,锚点可能会被跳过,因为领导者无法足够快地广播它,而如果有暂停,验证者将等待锚点。
在 Shoal,避免超时和领导声誉是密切相关的。重复等待缓慢的领导者会而增加延迟,领导者声誉机制排除了缓慢的验证者被选为领导者。通过这种方式,系统利用快速验证节点在所有现实场景中以网络速度运行。
请注意,FLP不可能性结果表明,没有确定性共识协议可以避免超时。Shoal不能规避这个结果,因为存在一个理论上的对抗性事件时间表,可以阻止所有锚被命令。相反,在可配置的连续跳过锚的数量之后,Shoal会退回到超时。实际上,这种情况极不可能发生。
普遍反应
Hotstuff 论文普及了乐观响应的概念,虽然没有正式定义,但直观上它意味着协议可以在包括快速领导者和同步网络的良好情况下以网络速度运行。
Shoal提供了一个更好的属性,我们称之为普遍响应。具体来说,与Hotstuff相比,即使领导者在可配置的连续回合数或网络经历异步周期内失败,Shoal也会继续以网络速度运行。请参阅下表中更详细的比较。
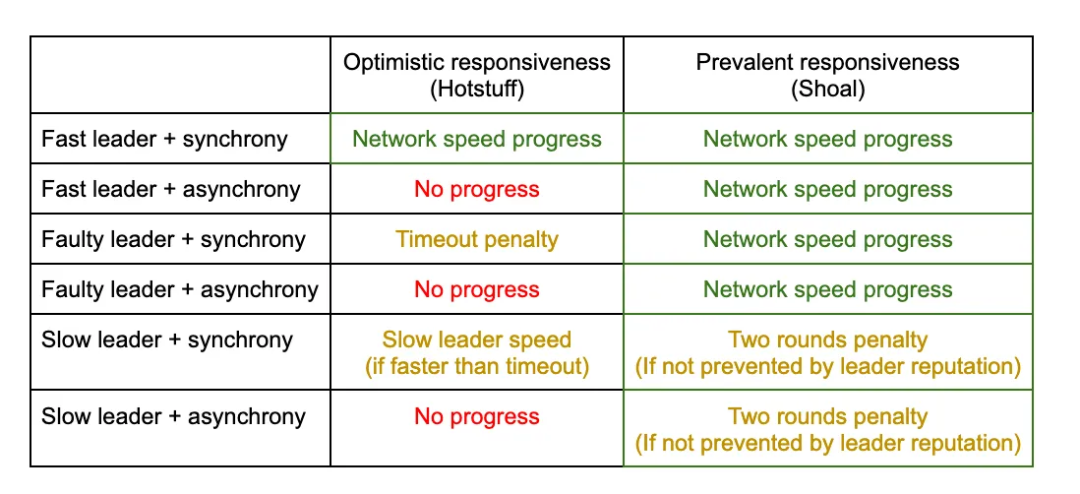
请注意,普遍的响应性在异步期间和领导者出现故障时提供了严格更好的进度保证。在与慢速领导者同步期间,这些属性是无法比较的,因为这取决于领导者有多慢。然而,鉴于领导者的声誉,行动迟缓的领导者应该很少出现在Shoal中。
评估
我们在我们的 Narwhal 实现 Quorum Store 之上实现了 Bullshark 和 Shoal。 Shoal、Bullshark 和 Jolteon 之间的详细比较可以在 Shoal 论文的评估部分找到,在这里,我们提供了一些亮点。
首先,为了演示异步DAG构造的强大功能,我们比较了有暂停和没有暂停的Bullshark。完整的Bullshark论文假设了一个异步网络,但提供了快速路径模式,因此在所有回合中都需要暂停。我们把这个版本称为 Vanilla Bullshark。我们观察到,对于独立的部分同步网络假设版本,不需要投票轮中的暂停。我们把这个版本称为没有投票暂停的Vanilla Bullshark w/o Vote timeout,Baseline Bullshark 是没有任何暂停的版本。
下图比较了有无故障时超时对 Bullshark 延迟的影响。显然,Baseline Bullshark(无超时)在出现故障时表现最佳。在没有失败的情况下,Baseline Bullshark 与没有投票暂停的 Vanilla Bullshark 相当。这是因为,如前所述,如果没有领导者信誉机制,超时可能在领导者好但慢的情况下具有优势。
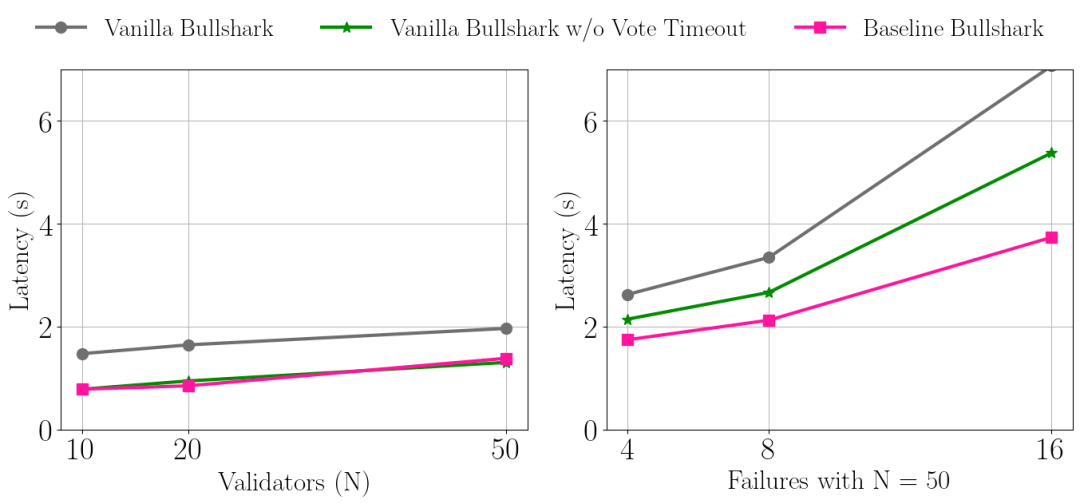
图 6.:超时对无故障(左)和有故障(右)的 Bullshark 延迟的影响,失败案例中有 50 个验证节点
接下来,我们使用 Baseline Bullshark(无超时)实例化 Shoal,并演示在有无故障的情况下流水线和领导者信誉机制的延迟改进,为了完整起见,我们还在无故障情况下将其与 Jolteon 进行了比较。
下面的图 7 显示了无故障情况,虽然流水线和领导声誉都可以单独减少延迟,但将它们组合在一起可以实现最佳延迟。
至于 Jolteon,它无法扩展到超过 20 个验证节点,并且即使它运行在 Quorum Store 之上,也只能达到 Bullshark/Shoal 吞吐量的一半左右,这消除了数据传播瓶颈。
结果表明,Shoal 极大地改善了 Bullshark 延迟。至于 Jolteon,重要的是要注意,尽管我们只测量了共识延迟。由于 Jolteon 无法在 DAG 之上本地运行,因此它需要额外的延迟来解耦数据传播,我们没有对此进行测量。因此,在高负载下,Shoal 应该与 Jolteon 的端到端延迟相匹配。
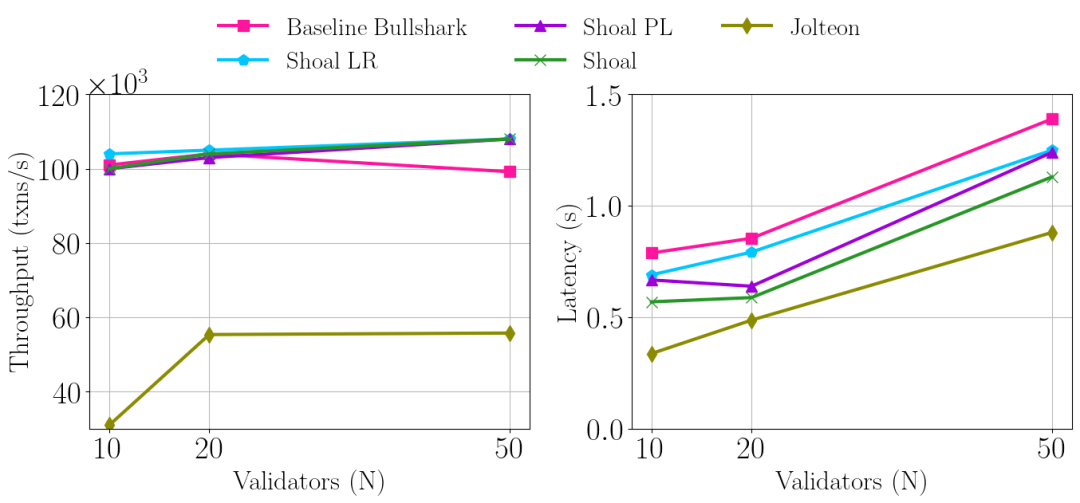
图 7:无故障情况下的吞吐量和延迟,Shoal PL 和 Shaol LR 分别仅支持流水线和领导声誉。
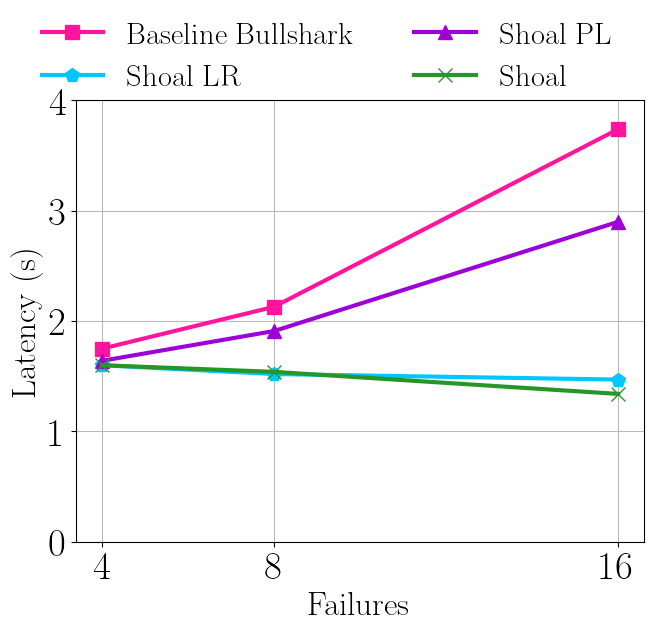
下面的图 8 显示了具有 50 个验证节点的失败案例,其中领导者信誉机制通过降低失败的验证者被选为领导者的可能性来显着改善延迟。请注意,在 50 次失败中有 16 次失败,Shoal 的延迟比 Baseline Bullshark 低 65%。