
原文:《Fraud and Data Availability Proofs》by Rabia Fatima
编译:ChinaDeFi
最近,我们在推特上看到了关于数据可用性及其重要性的讨论。毫无疑问,L2 解决方案正在赋予以太坊能够成为全球超级计算机的力量。然而,我们不能否认的事实是,就算使用 L2,但由于数量的限制,我们也无法实现我们的预期。其中第一个也是最重要的问题是「数据可用性问题 (DA)」。因此,在本系列中,我们将深入了解 DA 是什么,以及如何通过数据抽样和欺诈证明来解决它。
为了完全理解 DA 证明的概念我们需要知道的有:
- 欺诈和数据可用性证明
- DA 背景下的 Reed Solomon 代码
- Merkle 树构造的二维 Reed Solomon 代码
- 错误生成的扩展数据的欺诈证明
在这篇文章中,我们将讨论什么是数据可用性,为什么它对我们很重要,以及解决这个问题的潜在方案是什么。我们还将讨论在检测到 L2 上的恶意交易时,节点应如何提交欺诈证明。
加密货币平台每天都在受到大量的关注。但这种大规模的采用依然伴随着现有区块链的可扩展性限制。有可能解决该问题的方案是通过改进硬件规格来简单地增加链上吞吐量。但是这样做的话,就会损害去中心化,因为如果需要大型硬件,那么能够参与的节点会非常少。因此,大多数节点将运行轻客户端,并依赖于完整节点来验证区块链状态。在大多数节点不诚实的情况下,这种依赖并不十分靠谱。这就是为什么 L1 把链下解决方案作为实现可扩展性的最佳替代方案的主要原因。
当我们谈论像 Rollup 这样的链下解决方案时,我们常常倾向于忽略一个事实,就是即使使用 Rollup,我们也不能实现无限的吞吐量。想过为什么吗?
这是因为 Rollup 是一种链下计算解决方案,它在链下执行状态计算。为了完成区块,他们确实需要将状态和 callData 发布到基础层,如以太坊。因此,即使我们制作了 sequencer,一个超级计算机来产生无限区块,但由于基础层的网络和存储限制,我们无法最终确定它们。
所以当我们认识到 Rollup 本身不能实现无限的吞吐量时,我们就会有另一个问题,那就是如果中心化 sequencer 本身不诚实怎么办?他计算出了一个错误的状态了呢?L1 如何拒绝这些交易?现在当遇到这种情况时,我们在基础层上有完整的节点,这些节点会监控状态,在检测到错误的交易时,它们可以提交欺诈证明,以标记区块无效。
这是否意味着所有负责监控 Rollup 活动的 L1 节点都需要下载整个 sequencer 数据呢?? 答案是肯定的,情况正是如此。也就是说即使提出了链下解决方案,我们仍然需要完整节点,并提高我们的硬件需求。
在此基础上,就算我们设法运行一个强大的节点来监控交易,这仍然不能保证 sequencer 不会试图通过隐瞒数据来作弊。因为即使 1% 的数据不可用,也没有节点可以重建状态,因此没有人可以在定义的时间内提交欺诈证明,使区块有效。这就是我们定义的「数据可用性问题」。
但没有必要恐慌,因为以太坊已经提出了另一个聪明的解决方案来解决这个问题,即「数据可用性抽样」。那么什么是数据可用性抽样呢?它允许我们在不需要节点下载整个数据的情况下确保数据可用性。这是实现可扩展性的重大突破。
所以我们有两个概念:
- sequencer 试图用错误的交易来作弊,同时不保存任何数据。
- sequencer 试图用错误的交易来作弊,并且还保留了一定比例的数据,以便节点可能无法重建区块来提供欺诈证明。
现在我们想证明在共识节点中在不诚实的大多数的影响下,轻节点不会接受带有无效交易的区块。
作为第一个概念的例子,我们假设一个场景,恶意的 sequencer 试图通过在区块中包含错误的交易来进行欺骗,但不保存任何数据。
在 Optimistic Rollup 的情况下,为了证明该区块是无效的,节点需要重构一个区块并为它提交一个欺诈证明。
Rollup 区块结构
当涉及到支持欺诈证明的生成和有效性时,区块结构非常重要。现在假设高度为 i 的区块头 h_i 包含以下信息。
- 先前的 Blockhash 哈希 (prevHash_i)
- 涉及区块交易的数据 Merkle Root (dataRoot_i)
- Merkle 树中表示的叶数 (dataLength_i)
- Rollup 状态的 Merkle 树 (stateRoot_i)
- 网络可能需要的其他任意数据 (additionalData_i)
在以太坊等基于账户的模型中,键值对是账户地址和余额。
首先,我们定义一个转换函数,它在执行转换时不需要整个状态树,而只需要对交易读取或写入的状态树部分的 Merkle 证明,这通常被称为「State Witness」。这些 Merkle 证明有效地表示了为具有公共根的同一状态树的子树。函数可以定义为:
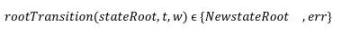
- t→Rollup 交易
- w→Merkle 交易证明树
w 由状态树中的一组值对及其相关的 Merkle 证明组成。
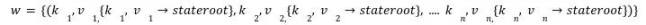
在 w 给定的部分状态上执行所有交易 t 之后 ( 如果交易修改了任何状态 ),可以通过用修改过的叶子计算新子树的新根来生成新的结果 NewstateRoot。
如果 w 不是正确的 witness,并且不包含执行过程中交易所需的所有叶子部分,那么它将抛出异常错误 err。
对于本系列的其余部分,将在此总结一些注释:

什么是 innerRoot?
innerRoot 是应用一定数量交易后区块中的中间根的表示。
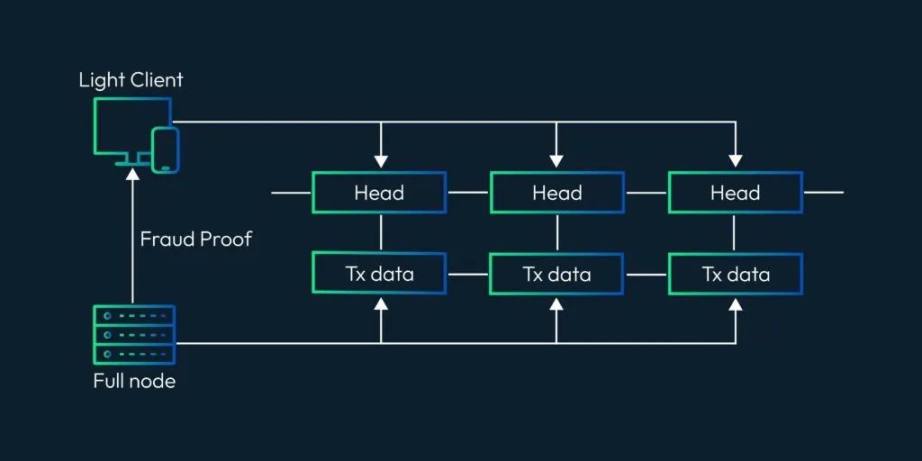
当我们讨论 Rollup 状态验证时,数据是最重要的东西。数据帮助我们重构状态,并验证由 Rollup 发布的状态是否有效。这就是为什么将 DataRoot 传递给轻客户端非常重要。
什么是 DataRoot?
dataRoot_i 是固定大小的交易数据块,以字节为单位,我们称为「shares」。shares 不会包含所有的交易,而是包含交易的固定部分。我们保留每个 share 中的第一个字节作为第一个交易的起始位置。这允许协议消息解析器建立消息边界,而不需要区块中的每个交易。
给定一个 shares 列表 (sh0, sh1,…)shn),我们定义一个函数 parseShares,它解析这些 shares 并输出消息列表 (m0、m1、……mt),这些消息要么是交易,要么是中间状态根。例如,在某些区块 i 中间的一些 share 上的 parseShares 可能会返回 (trace1i, t4i, t5i, t6i,trace2i)。
我们不能在每个交易之后都包含状态根,所以我们可以定义一个周期,例如在 g 个 gas 的 p 个交易之后,我们可以在区块中包含一个中间状态根。因此,我们有一个函数 parsePeriod,它解析一个消息列表并返回一个状态前中间根 tracexi 和状态后中间根 tracex+1i 和一个交易列表 (tig, tig+1,…tig+h),这样当我们在 tracexi 上应用这些交易时,它必须给我们 tracex+1i。如果交易不符合条件,则函数必须返回一个 err。

如何验证状态转换无效?
如果恶意的 sequencer 为我们提供了不正确的 stateRoot 呢?我们可以通过「VerifyTransitionFraudProof」函数检查 stateRoot 的无效。该函数接受完整节点提交的欺诈证明并对其进行验证。
什么是欺诈证明?
欺诈证明包括以下内容:
- 区块中包含错误状态转换的相关 shares。
- 这些 shares 的 Merkle 证明。
- shares 交易的 State witness。
VerifyTransitionFraudProof 函数将特定受挑战时期的交易应用到前状态中间,这必须导致中间后状态根。

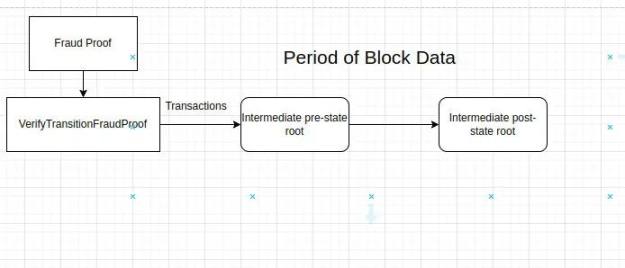
如果所有给定条件都为真,则函数 VerifyTransitionFraudProof 返回真,否则返回假。


我们已经了解了 DA 和欺诈证明,现在开始讨论第二个概念,也就是如果 sequencer 计算了一个无效的交易,而我作为轻客户端检测到它,那该怎么办。现在我需要为它计算一个欺诈证明。然而,sequencer 并没有发布完整的数据,通过这些数据我可以重建状态以进行验证。对于这个问题,Optimism 等 Rollup 提出了一个解决方案,即强制 sequencer 发布数据。















