
以太坊基金会研究员Dankrad Feist曾在一条推文中表示,不使用以太坊获得数据可用性就不是L2。如果按照他的说法,那么许多链都要被踢出L2的队伍,例如Arbitrum Nova、Polygon和Mantle等。
那么,数据可用性究竟是什么?L2面临怎样的数据可用性问题?为何对于数据可用性层L2有这么多争议?本文将聚焦这几个问题,试图揭开数据可用性的神秘面纱。
数据可用性是什么
简单来说,数据可用性是指区块生产者将区块的所有交易数据都发布到网络中,以便使验证者可以进行下载。
如果一个区块生产者发布了完整数据并使验证者可以下载,我们就说数据是可用的;如果它隐瞒了一些数据使验证者无法下载完整数据,我们就说数据是不可用的。
数据可用性与数据可检索性的区别
通常,我们容易将数据可用性与数据可检索性相混淆,但其实二者大不一样。
- 数据可用性涉及的是在区块被生产出来但还未通过共识添加到区块链时的阶段,因此数据可用性并不与历史数据有关,而是与新发布的数据是否能通过共识有关。
- 数据可检索性涉及的是数据已经通过共识并被永远储存在区块链后的阶段,即检索历史数据的能力。在以太坊中存储所有历史数据的节点被称为归档节点。
因此,L2BEAT联合创始人曾在一条长推中表示全节点并没有义务向我们提供历史数据,之所以我们能得到,只是因为全节点足够善良。
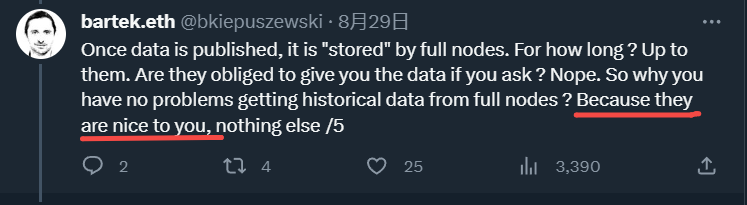
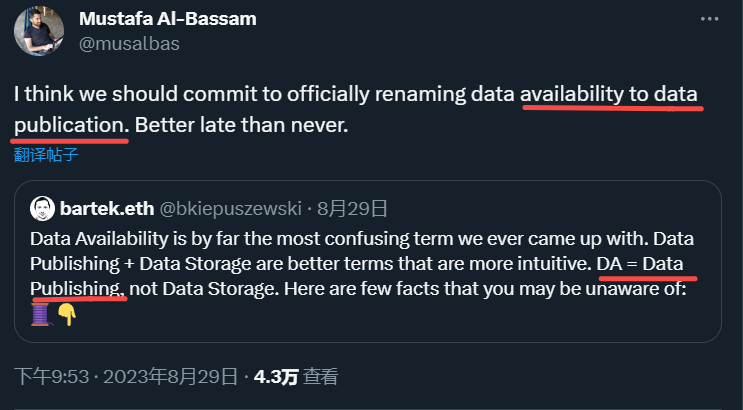
同时他还表示数据可用性(Data Availability)一词会使人对其作用产生误解,应该将它替换成数据发布(Data Publishing),这种说法还得到了Celestia创始人的赞同。
L2中的数据可用性问题
虽然数据可用性这个概念来源于以太坊,但目前我们着重关注的是L2层面的数据可用性。
在L2中排序器(Sequencer)就是区块生产者,他们要发布足够的交易数据以便验证者能够检查交易是否有效。(想了解关于排序器(Sequencer)的更多内容请阅读洞鉴周刊往期文章《研报|排序器(Sequencer)的原理、现状及未来》)
但在这过程中面临着两个问题,一是确保验证机制安全进行,二是降低发布数据的成本。以下将具体介绍。
确保验证机制安全进行的问题
我们知道OP Rollup采用欺诈证明的方式来验证交易的有效性,ZK Rollup则采用有效性证明的方式。
- 对于OP Rollup:如果排序器(Sequencer)不发布完整的能重溯区块的数据,欺诈证明中的挑战者将无法发起有效挑战;
- 对于ZK Rollup:虽然有效性证明本身不需要数据可用性,但ZK Rollup作为一个整体仍然需要数据可用性,如果没有能重溯区块的数据,那么用户将无法知道其余额,很可能丢失资产。
为了使验证安全进行,目前的L2排序器(Sequencer)普遍都将L2的状态数据与交易数据都发布在安全性较强的以太坊上,依靠以太坊进行结算并获得数据可用性。
因此,数据可用性层实际就是L2发布交易数据的地方,目前主流的L2都将以太坊当做数据可用性层。
降低发布数据的成本问题
如今的L2简单的将数据可用性与结算都发生在以太坊上,虽然有了足够的安全性,但也承担着巨大成本。这也是L2面临的第二个问题,即如何降低发布数据的成本。
用户支付给L2的总Gas主要由L2执行交易发生的Gas和L2向L1提交数据发生的Gas组成,前者费用微乎其微,后者才是用户费用的大头,其中为保证数据可用而发布的交易数据占L2向L1提交数据的主要部分,而验证交易有效的证明数据只占很小一部分。

因此,要想让L2整体更加便宜就得降低发布数据的成本。那么,该如何降低成本呢?主要有两种方法:
- 降低在L1上发布数据的成本,例如以太坊即将进行的EIP-4844升级,对EIP-4844升级感兴趣的小伙伴,可以阅读洞鉴周刊往前文章《Web3 科普|轻松搞懂 Layer2 的大利好:EIP-4844》;
- 仿照Rollup将交易执行从L1中剥离,数据可用性也可以从L1中剥离从而降低成本,也就是不使用以太坊作为数据可用性层。
L2对于数据可用性层的争议
要讲L2对于数据可用性层的争议,还得从模块化区块链说起。模块化区块链就是将整体区块链的各个核心功能进行解耦,形成相对独立的各个部分,并通过各种专用网络的组合来扩展单一区块链的性能。
虽然对于模块化区块链的分层还有些争议,但目前普遍被接受的是将模块化区块链分为四层,即执行层(Execution)、结算层(Settlement)、共识层(Consensus)和数据可用性层(Data Availability)。其各模块功能如下图
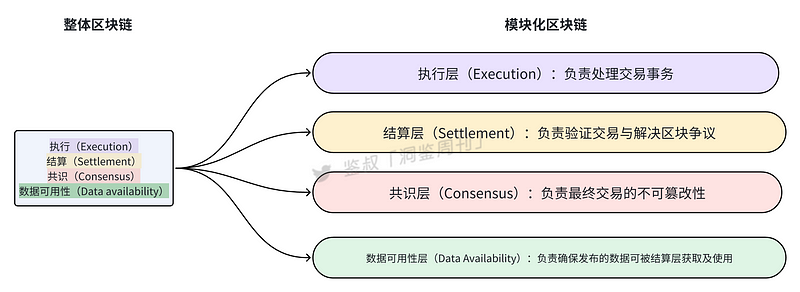
模块化区块链类似于乐高积木,可以通过定制化,使用最好的积木块搭建了一个良好的模型,缓解了区块链“不可能三角”的问题。
不过,现在的L2除了将执行层从以太坊中分离以外,其他三层的功能依然在以太坊上进行。但出于成本方面的考量,许多L2也在准备将数据可用性层从以太坊中剥离,而将以太坊只当做结算层和共识层使用。
有趣的是,以太坊似乎并不想让L2从其他地方获取数据可用性,以太坊基金会的研究员Dankrad Feist就曾在一条推文中表示不使用以太坊作为数据可用性层就不是Rollup,因此也不是L2。
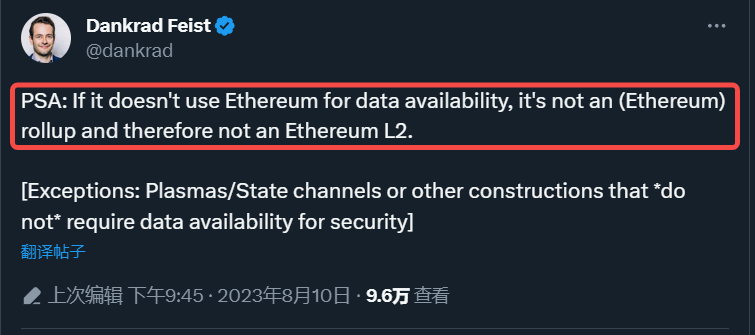
同时,在L2BEAT最新对于L2的定义中也指出不在L1发布数据的扩容方案都不是L2,因为使用链下数据可用性解决方案无法保证运营商会提供发布的数据。

当然具体关于什么是L2目前还未有盖棺定论,以上以太坊基金会成员和L2BEAT坚持认为L2要将数据可用性层留在以太坊看似是出于安全性的考量,但实际是否有对以太坊地位动摇的担心呢?
以太坊的愿景是要成为一个超级计算机平台,后来为了提升网络性能,不得不发展Rollup并使许多生态跑到了更加便宜的L2上发展,但因为安全性由以太坊提供,对以太坊的地位并未有多大影响。但如果L2将涉及数据发布的数据可用性层也剥离了以太坊,本质上是削弱了对以太坊安全性的依赖,逐渐的远离了以太坊,这就对以太坊的地位造成了威胁。
不过不管怎样,也依然阻挡不了数据可用性层相关项目的蓬勃发展。在下一篇关于数据可用性的文章中,笔者将详细介绍目前市面上主要的数据可用性解决方案及具体的相关项目,敬请期待。
参考资料:
【1】以太坊文档:数据可用性
【3】开除Validium?从Danksharding提出者的视角重新理解Layer2





