





引言
为了让用户掌握更多的市场信息,多家交易所上线了合约大数据产品,包括多空持仓比、未平仓量、合约基差等与合约市场息息相关的数据。这些市场数据是无数信息交易者和噪音交易者通过真金白银的投入而绘制出的市场画像,数据中包含大量有价值的信息。对市场数据进行分析有助于投资者判断当前市场所处的位置,预测未来市场的走向,从而更好地控制风险,抓住机遇。
本文主要对OKEx合约大数据产品中的多空持仓比(Long Short Position Ratio,以下均将多空持仓比简称为lspr)进行定量的分析。下面以比特币为例,回顾过去半年中lspr与市场走向的关系,并且通过建模等手段,抛砖引玉,尝试读懂lspr的预言。
第一章 多空持仓比介绍
多空持仓比的计算方式为,持有净多头的账户数量除以持有净空头的账户数量:
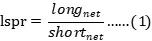
所谓净持仓,指的是:若交易者出于某种目的同时持有某数字资产的合约空头和多头合约时,将其所持多空合约一对一抵消后,剩余合约的数量和方向。
在合约市场中,交易者每开出一张多单,就会有对应的一张空单成交。也即,市场上的任何时候,多单和空单的数量都是一样的。净多头账户所持有的多头合约平均张数与净多头账户的积,即为总多头合约数。对于空头合约亦是如此。由以上两点,可以得到下式:
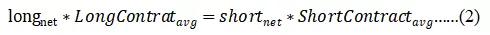
由(1)(2)式可得:
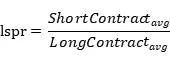
可以发现,lspr可以转化为空头账户平均持仓量与多头账户平均持仓量之比。这意味着:lspr越高,空方平均资金量越大;反之亦然。例如,若此时lspr为3,就表示平均每个净空头用于做空的保证金为净多头用于做多的保证金的三倍。通常而言,我们认为信息交易者具有资金、消息上的优势,能够在市场中获得超额收益。在资金量较小的交易者贪婪地买入或者恐惧地卖出时,藏在阴影中的信息交易者便可能会在lspr因子上露出马脚。
第二章 因子衍生
因子衍生,学名“特征工程”,是在原始数据的基础上,进行一系列变换,使得算法能够更好地从数据中获取信息的过程。本文采取的数据为OKEx平台上BTCUSD交割合约的lspr值,以及Bitfinex平台的BTC/USD现货价格。时间跨度为2019年8月1日至2020年6月9日,其中,2019年8月1日至2020年2月1日为训练集,分析和建模将只采用这一范围内的数据。2020年2月1日至2020年6月9日的数据为验证集,意在验证规律是否稳定。
第一节 衍生因子介绍
为了充分提取lspr中蕴含的信息,同时兼顾可观测样本的限制,我们设计了长短两个时间维度,三个统计维度,总计六个因子:
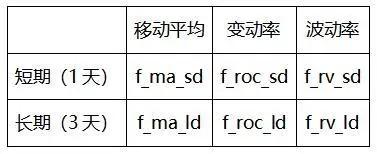
表2.1 衍生因子
(一) lspr移动平均值
通过计算lspr的移动平均,可以一定程度上消除极端值的影响,从而获得更加稳定的lspr值。其中,f_ma_ld为过去72小时的lspr平均值,f_ma_sd为过去24小时的平均值。两者反映了近一段时间内lspr的绝对水平。下文将探索当lspr处于不同水平时,标的未来一段时间内涨跌表现是否存在不同。
(二) lspr变动率
lspr变动率衡量了近期lspr变动情况。当lspr下降时,这一指标则为负值,反之亦然。其中,f_roc_ld为当前lspr值较72小时前值的变动率,f_roc_sd为当前lspr较24小时前值的变动率。当lspr值开始上升,可能意味着资金量较小的交易者开始做多,或者拥有资金和信息优势的交易方开始加仓押注未来即将下跌,那么lspr的变动率便可以直观地描述这一现象,为投资者提供变盘的信号。
(三) lspr波动率
相比上述两个因子,lspr波动率的计算可能稍有复杂。主观上分析,若lspr波动率较低,那么意味着这一段时间内多空持仓陷入了焦灼的状态,双方相持难下;反之,若lspr波动率较高,则说明资金博弈层面上,资金量较小的交易者的资金在多空两边反复横跳,这种情形可以被描述为“躁动”。而“躁动”和“焦灼”分别对应了未来的哪一种行情,则需要定量地进行分析。下面,我们分别对过去72小时和24小时内的lspr计算其变异系数(Coefficient of Variation),作为其波动率的估计量。
第二节 衍生因子表现
出于经验考虑,预测标的选择为未来72小时,即未来三天的收益率。训练集时间段内,BTC未来72小时的涨跌幅如下图所示,基本涵盖了震荡和趋势的行情。
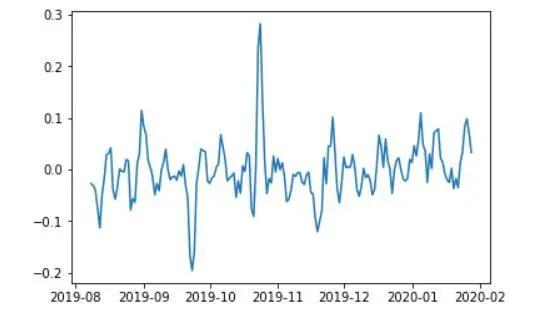
图2.1 BTC未来72h收益率序列
一般而言,在对各个因子进行加工之后,首先需要对衍生因子的预测能力做一个快速、初步的评估。在本研究中,将不同因子从小到大排序,并且通过CART决策树算法确定切分阈值,将样本分为若干个区间。进而计算每个区间内因子的平均值,以及对应的收益率的平均值,从而直观的判断各个因子对收益率的影响。
CART决策树算法,大多数情况下,是使用二叉树对数据进行分类或回归的算法。如图所示:
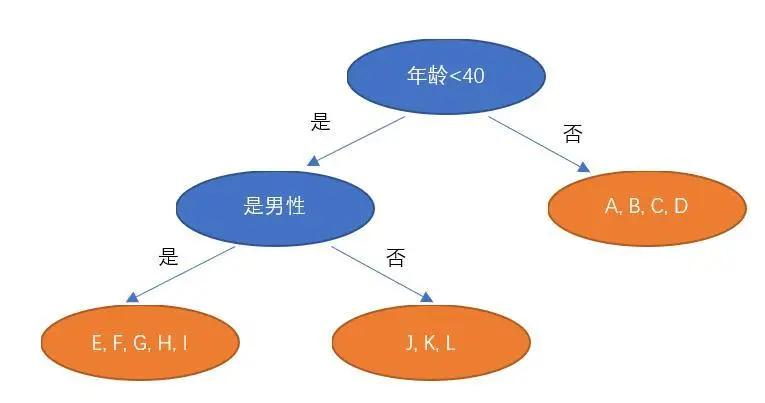
图2.2 CART决策树示意
图中对A, B, C, …, L这些人进行了分类。蓝色的节点被称为分裂点,橙色的节点被称为叶片。叶片的数量也就决定了这一棵决策树最终将样本分成了几类。在本文的算法中,考虑到样本数量不是很多,最大叶片数可以设置为5,即最多将样本分为5份,单个叶片包含最小样本量为总体的16%。
计算完所有因子以及收益率后,在每天零点取一个样本加入训练集,总计获得174个样本。
(一) lspr移动平均值
过去24小时lspr均值对未来72小时收益率有显著反向影响。f_ma_sd观测值越大,未来72小时内越可能下跌,反之亦然。这与前文的假设一致,具有极强的逻辑解释性。如下图所示,将样本按照因子大小升序分为5份,进行分组统计。其中,第0组中,因子均值为1左右,对应的平均收益率略大于0;而第4组中因子均值超过1.5,对应的平均收益率小于-2%。且均分较低的组平均收益率显著大于得分较高的组。
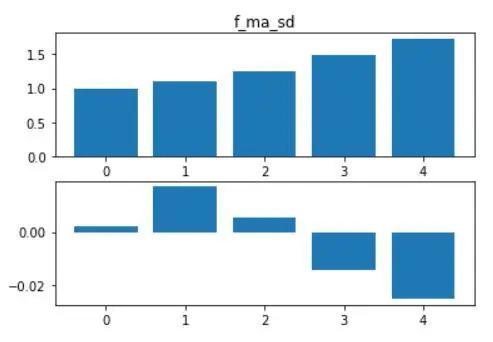
图2.3 f_ma_sd分组结果
过去72小时lspr均值也在训练集中展现出类似的性质,在此不再赘述。
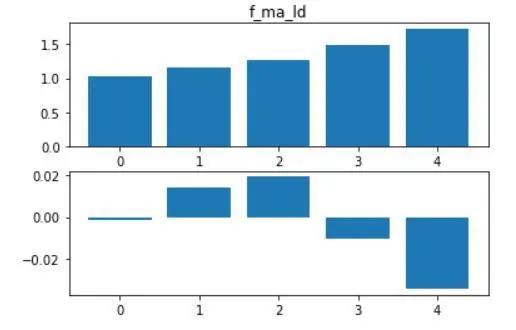
图2.4 f_ma_ld分组结果
(二) lspr变动率
在训练集中,通过观察f_roc的分组结果,可以发现:f_roc大幅减少确实意味着未来72小时更可能上涨,而f_roc大幅上涨对于多头来说却不是什么好迹象。如果当前lspr较3天前大幅上升,那么多头处于不利地位。若当前lspr较3天前大幅下降,那做多的预期收益可能会更高。不过,当变动率接近零时,这个因子对未来收益率的预测能力则几乎很弱。详情请见下图:
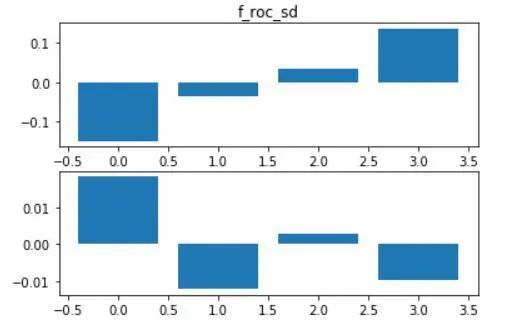
图2.5 f_roc_sd分组结果
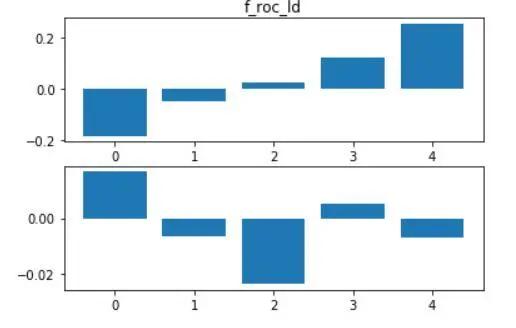
图2.6 f_roc_ld分组结果
(三) lspr波动率
现在,我们得以回答上一节中提出的问题。资金层面上多空双方的“焦灼”更可能预示着未来的下跌,而lspr的“躁动”,实则是新一轮行情的预兆。
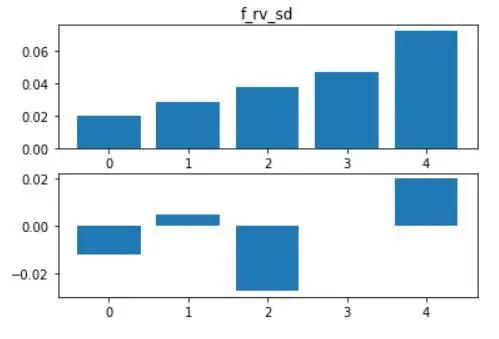
图2.7 f_rv_sd分组结果
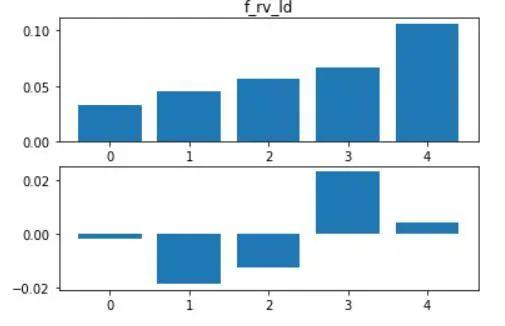
图2.8 f_rv_ld分组结果
第三章 模型搭建
在上一章中,我们已经总结出来一些规律。但各个因子之间可能存在交互作用,也可能存在一些非线性关系。为了从lspr中提取更加有投资指导价值的信息,需要进一步建立量化模型。
第一节 算法增强
本文构造的因子在已知数据中均展现出与未来收益率的一定联系,且逻辑上能够进行合理解释,故可以将上述六个因子全部加入模型。
在实践中,单个算法的预测虽然对未来的行情走势存在一定指导意义,但比较模糊。根据机器学习的理论,我们使用了多个算法,进行增强(Boosting)训练,达到综合多种算法学习能力,获得更好预测结果的目的。在建模的思路上,可以先使用六个因子以及其对应的因变量,采用线性和非线性的模型进行样本内训练,得到多个弱分类器;再将弱分类器输出的拟合值作为因子,以线性模型进行集成,得到最终的模型,并在测试集中使用。之所以进行集成,是为了减少单个模型不可靠的可能,增强模型的稳定性和在未知数据上的泛化能力。
其中,线性模型分别为OLS,RidgeCV。前者最为朴素,可以通过观察回归方程给出直观的理解和解释,但分析因子效果时可能会受到因子多重共线性的影响。后者引入了正则项减少多重共线性的影响,交叉验证虽然减少了引入后验知识的可能,但也增加了模型的复杂度。
由于某些因子与收益率的对应关系并非线性,所以我们也决定使用非线性模型决策树与随机森林算法。决策树算法可以抽象出容易理解的规则,适用于特征维度较高,样本量较少的数据集,我们给定单个叶片的最小样本量以环节过拟合。但其输出的预测集中于几个叶片上,所以可以明显看到它输出的预测“挤在一团”。随机森林算法则以bagging的方法随机挑选因子和样本训练大量独立的决策树,并且采用各个决策树投票的方式得到最终模型。它可以很好地提取训练样本的信息,但牺牲了解释性,一定程度上可以视为黑箱。
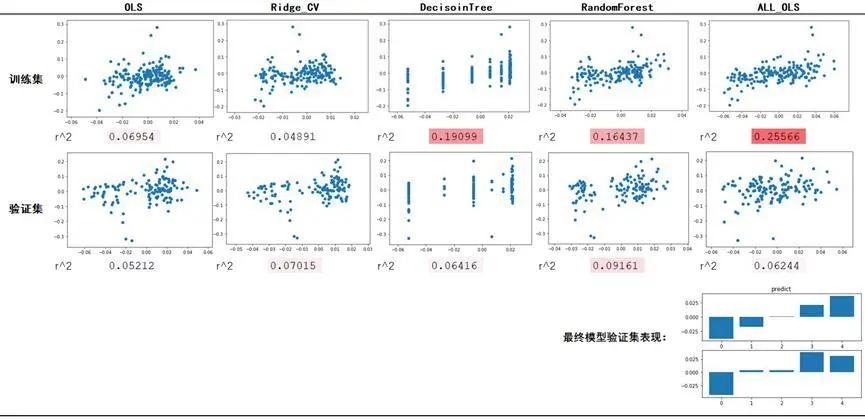
图3.1 模型表现
上图为各个模型在训练集和测试集上的表现。其中,OLS、Ridge_CV、DecisionTree、RandomForest分别为四个子模型。第一行展示了模型在训练集中的表现,每幅散点图中,横纵轴分别是子模型的预测值与BTC实际的未来三天涨跌幅。在每幅散点图的下方,列出了模型的拟合优度R^2,这一数值越高,说明模型预测能力越强,虽然这一数值普遍不大,但作为预测模型,已经极具实践意义。第二行为验证集,这一行展示了各个采用不同算法的模型在未知数据上的泛化能力。非常合理的是,预测效果较训练集中有所衰减,但超过0.05的R^2表示,各个子模型也都具有一定的预测作用。
第五列ALL_OLS中,展示了以所有子模型的预测值为因子,采用OLS算法搭建的集成模型的表现。虽然其R^2在测试集上表现并非最佳,但由于其避免了模型选择的偶然性,并以此降低了单个模型的失效对整体的影响,因此选择将其作为最终模型。
在第三行中,采用决策树对ALL_OLS模型在训练集中的输出值与实际值进行最优分组,得到其切分点。然后将ALL_OLS在验证集中做出的预测值以前一步中得到的切分点进行分组。柱形图(上)为验证集每组预测值的均值,柱形图(下)为其对应真实值的均值。据此,可以直观地看出,模型确实具备一定的预测能力。不过,由于算法的复杂性和数据量的限制,模型背后的经济逻辑尚待未来进一步探究。
第二节 预测结果离散化
出于对模型稳定性的追求,下面采取两步方法。第一步上一节提到过的采用集成模型的方法,这减少了单个模型失效对整体的影响以及模型选择上的偶然性和主观性。第二步则为将预测结果离散化。离散化可以减少过拟合的概率,提升模型泛化能力,从而更加自信地在未知数据上使用模型。
预测结果离散化的大致流程如下:
首先,在训练集中得到了ALL_OLS模型输出的对于真实涨跌幅得到拟合值,将拟合值通决策树进行切分得到最优分组,此时便得到了一张映射表:
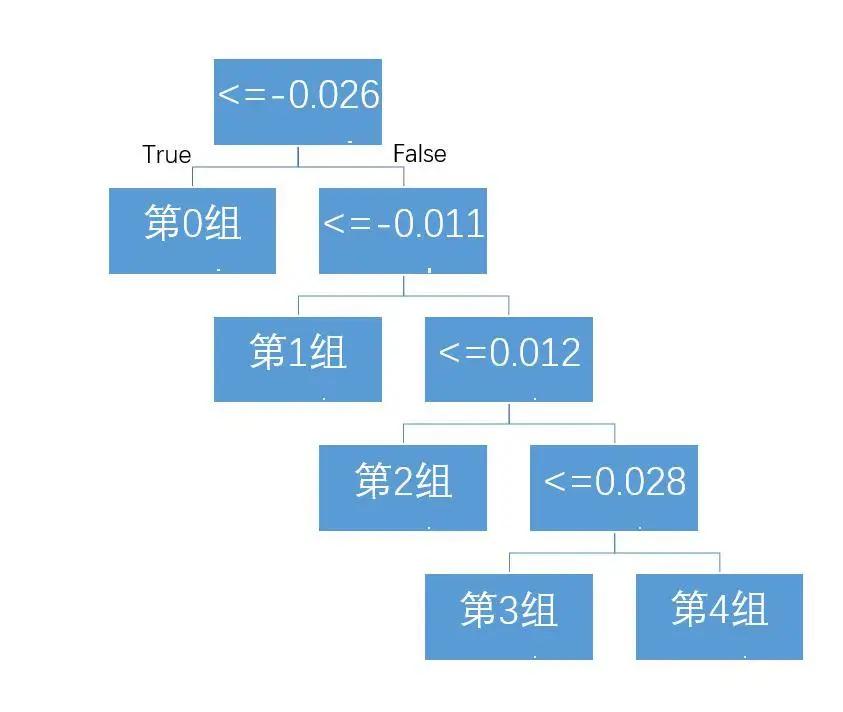
图3.2 离散化映射表
当将验证集数据输入训练好的ALL_OLS模型后,它会输出一个预测值,然后便可以通过映射表将其转化为离散值。若这个预测值为0.01,那么便将其根据上述映射表转换为2,若预测值为0.05,那么转换后的值则为4。本研究中采取了左开右闭的处理方式,但改变这一设置不会对策略产生决定性的影响。
第四章 模型应用
模型基于BTC合约多空持仓比数据,因此,这一策略主要的操作标的也是BTC。根据模型预测结果的分组,我们构造了如下的策略。
模型会预测未来72小时的BTC走势,但它每天都会产生一个预测结果,即一个0到4的打分。持仓的范围为[-1,1],即满仓做空至满仓做多。取过去三日的打分结果均值,作为今日的持仓指标,用于指导持仓。
举例而言,若过去三日的打分结果分别为2,3,3,则三日的平均分为2.67分,将2.67在[0, 4]区间的位置映射到[-1, 1]区间,得到今日持仓比例应为0.335,即使用33.5%的资金做多。
第一节 策略构造
基于这一思想,可以构造三个策略:
五层策略:即使用-1,-0.5,0,0.5,1的仓位比例对应0,1,2,3,4的打分,这一构造方式相对中性,不包含对市场的先验主观判断,并且仓位相对连续,调仓成本较小;
五层纯多头策略:即使用0.2,0.4,0.6,0.8,1的仓位比例对应0,1,2,3,4的打分,这一构造方式包含了先验的主观判断,认为比特币应该长期持有,因此比较适合“囤币党”(意即长期持有数字资产的投资人)用于短期对冲风险;
两层策略:即使用-1,0,0,0,1的仓位比例对应0,1,2,3,4的打分,观察第三章的分组结果,可以发现预测的分组在极端组内(第一组与第五组)的预测效果比较稳健,在中间组(第二、三、四组)内预测效果相对模糊。因此,可以考虑仅在行情落入第一组时全仓做空,落入第五组时全仓做多。
第二节 策略回测
三个策略在测试期(2020年2月1日至2020年6月9日)内的表现如图所示:
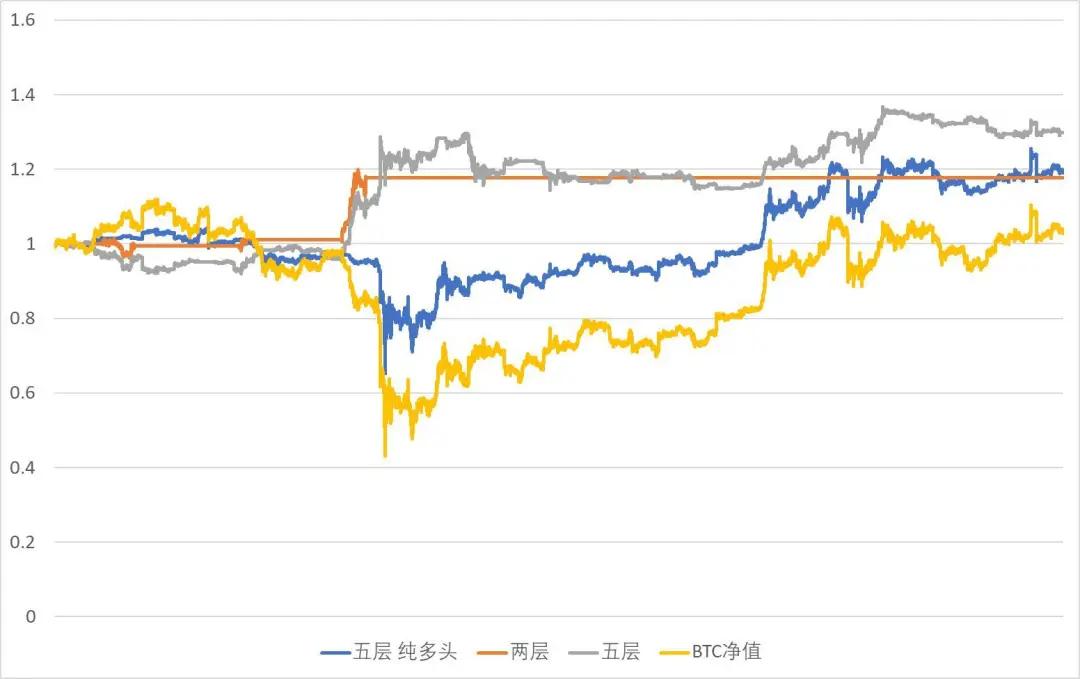
图4.1 策略回测资金曲线
计算常用的策略评价指标,可得:
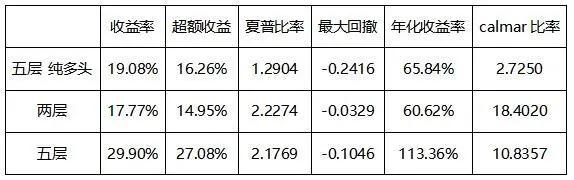
表4.1 策略评价指标
各个策略都取得了相对净持有BTC的超额收益。两层策略的夏普比率最高,在无风险收益率为3%的情况下,夏普达到了2.22。但是观察其净值曲线,可以发现在绝大多数时间里,由于策略的开仓条件过于苛刻,策略是空仓的。开仓次数过少意味着回测结果对策略的评价很有可能不够稳健,在更长的时间里,有可能会与本次回测的观测结果产生冲突,因此,我们不认为这是一个好的策略。
五层策略与五层纯多头策略相比,允许做空的策略明显取得了更好的效果。这是因为在回测期内,BTC基本走出了0的收益。不过,作为“囤币党”,或者BTC的忠实信众,这一策略也能够为他们对冲掉一些BTC的短期下跌风险。
三个策略中表现最好的是五层多空策略。在三个月左右的回测期内,取得了接近30%的收益,夏普比率也达到了2.17,最大回撤仅10%,最大的持仓比例为100%,即不带任何杠杆,因而不存在理论爆仓风险。这个策略同时也符合我们在投资活动中的一些想法:不要相信故事,而要相信市场的波动。
第五章 总结
综上,OKEx交易所的合约大数据中,lspr这一指标能够对未来BTC行情起到比较好的指导作用。直观来看,近三天的lspr均值与未来72小时BTC收益负相关,并且lspr的大幅波动往往预示着大概率的上涨。
使用lspr数据,我们构造了一个简单的策略。策略在2020年2月至6月这一段时间中,相对BTC,取得了27%的超额收益,夏普比率2.17,表现优异。
受限于lspr数据量,本文构造的策略测试时间较短,在未来更长期限的投资中,有可能存在表现不稳定的情况。但无论如何,lspr数据的确能够从一个特殊角度提炼市场信息。进一步的研究可以将多频率,多品种的lspr数据与其他的有效因子相结合,以求对未来市场中数字资产的长期和短期走势进行更准确的估计。











 APP
APP 
