





作者:罗奔奔,前 Arbitrum 技术大使、极客 web3 贡献者
本文是 Arbitrum 前技术大使 及 智能合约自动化审计公司 Goplus Security 前联合创始人罗奔奔 对 Arbitrum One 的技术解读。
因为中文圈子里涉及 Layer2 的文章或资料,缺乏对 Arbitrum 乃至 OP Rollup 的专业解读,本文试图通过科普 Arbitrum 的运转机理,填补这一领域的空缺。由于 Arbitrum 本身的结构太复杂,全文在尽可能简化的基础上,还是超过了 1 万字篇幅,所以分成了上下两篇,建议作为参考资料收藏转发!
Rollup 排序器简述
Rollup 扩容的原理可以概括为两点:
成本优化:将⼤部分运算与存储任务移交至 L1 链下也即 L2 上。L2 大多是运⾏在单台服务器也即排序器(Sequencer/Operator)上的⼀条链。
排序器在观感上接近于一台中心化服务器,在「区块链不可能三⻆」中舍弃「去中心化」来换取 TPS 与成本上的优势。⽤户可以让 L2 来代替以太坊处理交易指令,成本比在以太坊上交易要低得多。
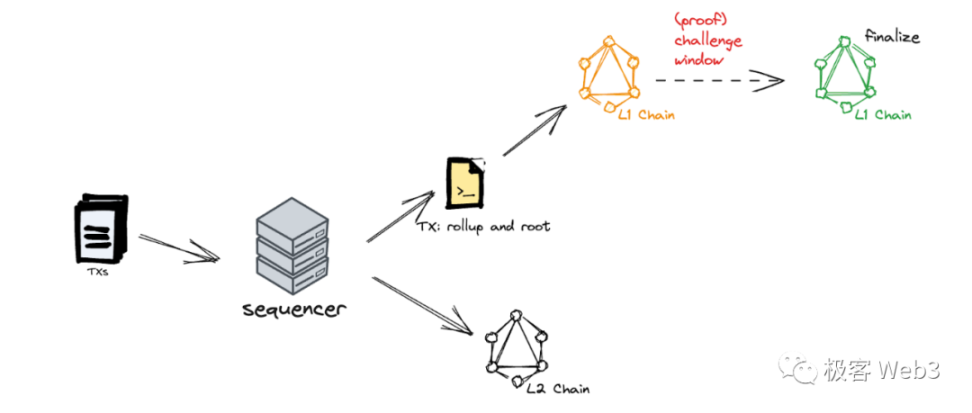
安全保障:L2 上的交易内容与交易后的状态,会同步⾄以太坊 L1,通过合约来校验 状态转换的有效性。同时,以太坊上会保留 L2 的历史记录,排序器即便永久宕机,他⼈也可以通过以太坊上的记录,还原出整个 L2 的状态。
从根本上来说,Rollup 的安全性是基于以太坊的。排序器如果不知道某个账户的私钥,就无法用该账户的名义发起交易,或者无法篡改该账户的资产余额(即便这么做了,也很快被识破)。
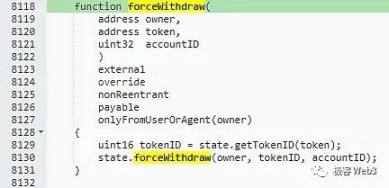
虽然排序器作为系统中枢带有中⼼化色彩,但在成熟度比较高的 Rollup 方案中,中心化排序器仅能实施交易审查等软性作恶⾏为,或者恶意宕机,但在理想状态的 Rollup ⽅案中,有相应的⼿段进⾏遏制(比如强制提款或排序证明等抗审查机制)。
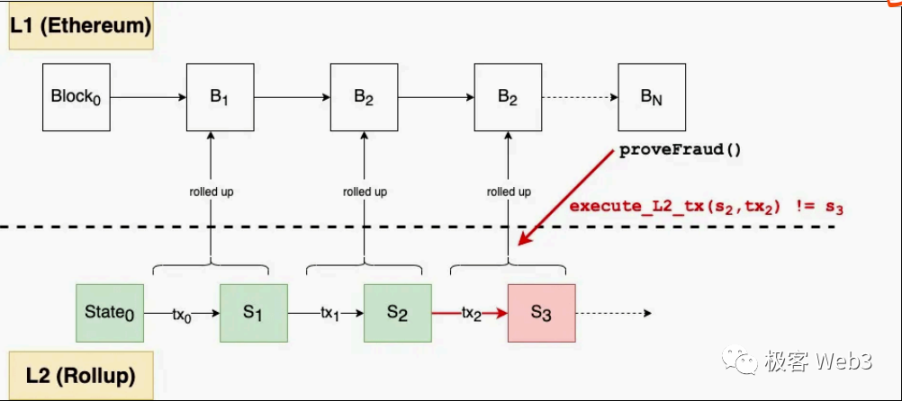
而防止 Rollup 排序器作恶的状态校验⽅式,分为欺诈证明(Fraud Proof)和有效性证明(Validity Proof)两类。使⽤欺诈证明的 Rollup ⽅案称为 OP Rollup(Optimistic Rollup,OPR),⽽因为一些历史包袱,使⽤有效性证明的 Rollup 往往被称为 ZK Rollup(Zero-knowledge Proof Rollup,ZKR),而不是 Validity Rollup。
Arbitrum One 是典型的 OPR,它部署在 L1 上的合约,并不主动验证提交过来的数据,乐观地认为这些数据没有问题。如果提交的数据有错误,L2 的验证者节点会主动发起挑战。
因此OPR 也暗含一条信任假设:任意时刻⾄少有⼀个诚实的 L2 验证者节点。⽽ ZKR 的合约则通过密码学计算,主动但低成本地验证排序器提交的数据。
本文会深度介绍乐观式 Rollup 中的龙头项目——Arbitrum One,覆盖整个系统的方方面面,仔细阅读完后你将对 Arbitrum 和乐观式 Rollup/OPR 有深刻的理解。
Arbitrum 的核心组件与工作流程
核心合约:
Arbitrum 最重要的合约包括SequencerInbox, DelayedInbox, L1 Gateways, L2 Gateways, Outbox, RollupCore, Bridge 等。后续将详细介绍。
排序器 Sequencer:
接收用户交易并进行排序,计算交易结果,并迅速(通常<1s)返还给用户回执。用户往往在几秒内就能看到自己的交易在 L2 上链,体验就如同 Web2 平台。
同时,排序器还会在以太坊链下即时广播最新产生的 L2 Block,任何一个 Layer2 节点都可以异步的接收。但此时,这些 L2 Block 不具备最终确定性,可以被排序器回滚掉。
每隔几分钟,排序器会将排序后的 L2 交易数据进行压缩,聚合成批次(Batch),提交至 Layer1 上的收件箱合约 SequencerInbox,以保证数据可用性和 Rollup 协议的运转。一般而言,被提交至 Layer1 上的 L2 数据无法回滚,可以具备最终确定性。
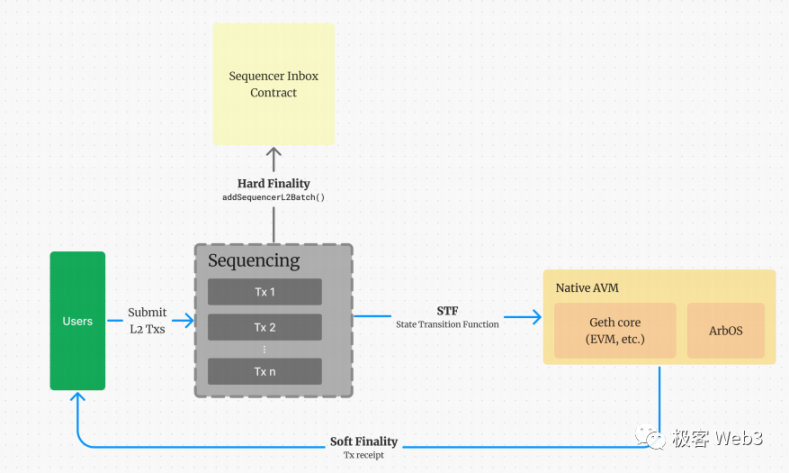
从以上流程中我们可以概括:Layer2 有自己的节点网络,但这些节点数量稀少,且一般没有公链惯用的共识协议,所以安全性是很差的,必须要依附于以太坊来保证,数据发布的可靠性与状态转换的有效性。
Arbitrum Rollup 协议:
定义 Rollup 链的区块 RBlock 的结构,链的延续方式,RBlock 的发布,以及挑战模式流程等⼀系列的合约。注意,这⾥说的 Rollup 链并不是大家理解的 Layer2 账本,而是 Arbitrum One 为了施展欺诈证明机制,而独立设置的一条抽象出来的「链状数据结构」。
⼀个 RBlock 可以包含多个 L2 区块的结果,⽽且数据也迥异,它的数据实体 RBlock 存储在 RollupCore 的⼀系列合约中。如果⼀个 RBlock 存在问题,Validator 将⾯向该 RBlock 的提交者对其进⾏挑战。
验证者 Validator:
Arbitrum 的验证者节点其实是 Layer2 全节点的特殊子集,目前有白名单准入。
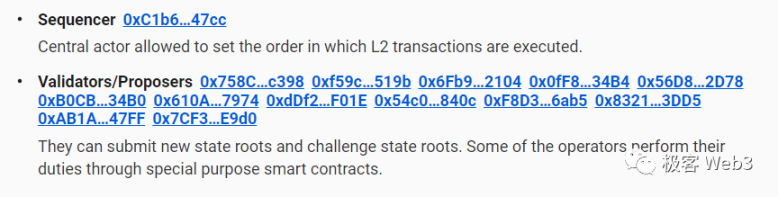
Validator 根据排序器提交至 SequencerInbox 合约的交易批次 batch,来创建新的 RBlock(Rollup 区块,也叫断⾔ assertion),并监控当前 Rollup 链的状态,对排序器提交的错误数据进⾏挑战。
主动型的 Validator 需要事先在 ETH 链上质押资产,有时我们也称其为 Staker。不进⾏质押的 Layer2 节点虽然也可以监控 Rollup 的运⾏动态,向⽤户发送异常报警等,但⽆法在 ETH 链上直接对排序器提交的错误数据进行⼲预。
挑战:
基础步骤可以概括为多轮互动式细分、单步证明。在细分环节,挑战双⽅先对有问题的交易数据进⾏多轮回合制细分,直⾄分解出有问题的那⼀步操作码指令,并进⾏验证。「多轮细分 - 单步证明」这种范式,被 Arbitrum 开发者认为是欺诈证明中最节省 gas 的实现⽅式。所有环节都在合约控制之下,没有⼀⽅可以作弊。
挑战期:
由于 OP Rollup 的乐观 optimistic 本质,每个 RBlock 提交上链后,合约并不主动检查,预留给验证者一段时间窗⼝期去证伪。此时间窗⼝即为挑战期,在 Arbitrum One 主⽹上为 1 周。挑战期结束后,该 RBlock 才会被最终确认,块内对应的从 L2 传递到 L1 的消息(比如通过官方桥执行的提款操作)才能被放行。
ArbOS, Geth, WAVM:
Arbitrum 采用的虚拟机名为 AVM,包含 Geth 和 ArbOS 两部分。Geth 是以太坊最常⽤的客户端软件,Arbitrum 对其进⾏了轻量化的修改。ArbOS 负责所有 L2 相关的特殊功能,如⽹络资源管理、⽣成 L2 区块、与 EVM 协同⼯作等。我们将两者的组合视为⼀个 Native AVM,也就是 Arbitrum 采用的虚拟机。WAVM 是把 AVM 的代码编译为 Wasm 后的结果。Arbitrum 挑战流程中,最后的那个「单步证明」,验证的就是 WAVM 指令。
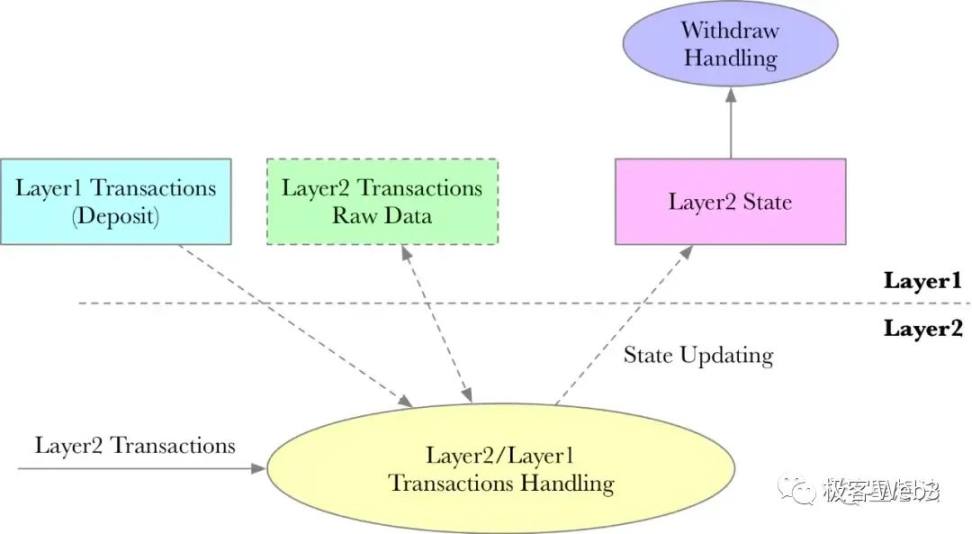
在此,我们可以将上述各个组件之间的关系和⼯作流⽤下图来表示:
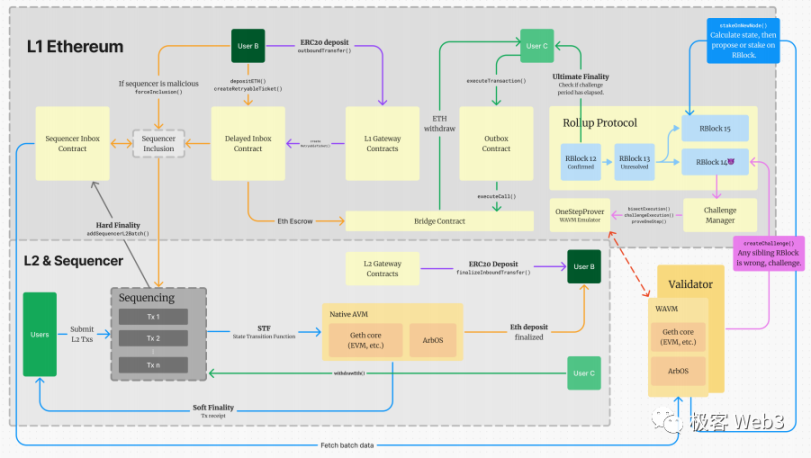
L2 交易生命周期
一笔 L2 交易的处理流程如下:
1.用户向排序器发送交易指令。
2.排序器先对待处理交易进数字签名等数据的验证,剔除无效交易,并进行排序和运算。
3.排序器将交易回执发送给⽤户(通常都⾮常快),但这只是排序器在 ETH 链下进行的「预处理」,处于 Soft Finality 的状态,并不可靠。但对于信任排序器的⽤户(⼤部分⽤户),可以乐观的认为交易已经完成,不会被回滚。
4.排序器将预处理后的交易原始数据,⾼度压缩后封装为⼀个 Batch(批次)。
5.每隔⼀段时间(受到数据量、ETH 拥堵程度等因素影响),排序器会向 L1 上的 Sequencer Inbox 合约发布交易 Batch。此时可认为,交易已拥有最终性 Hard Finality。
Sequencer Inbox 合约
合约会接收排序器提交的交易 batch,保证数据可⽤性。深⼊地看,SequencerInbox 中的 batch 数据完整记录了 Layer2 的交易输入信息,即使排序器永久宕机,任何⼈都可以根据 batch 的记录还原 Layer2 的当前状态,接替故障 / 跑路的排序器。
⽤物理的⽅式理解,我们所看到的 L2,只是 SequencerInbox 中 batch 的投影,光源则是 STF。因为光源 STF 不会轻易变化,所以影⼦的形状只由充当物体的 batch 来决定。
Sequencer Inbox 合约⼜称为快箱,排序器专门向其提交已经被预处理的交易,且只有排序器可向其提交数据。对应快箱的是慢箱 Delayer Inbox,其功能在后续流程中会有描述。
Validator 会一直监听 SequencerInbox 合约,每当排序器向该合约发布 Batch 后,就会抛出一个链上事件,Validator 监听到这个事件发生后,就会去下载 batch 数据,在本地执⾏后,向 ETH 链上的 Rollup 协议合约发布 RBlock 。
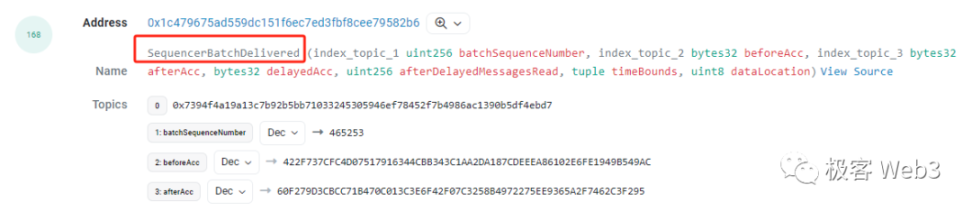
Arbitrum 的 bridge 合约内有个叫累加器 accumulator 的参数,会针对新提交的 L2 batch,以及慢 Inbox 上新接收的交易数和信息,进行记录。
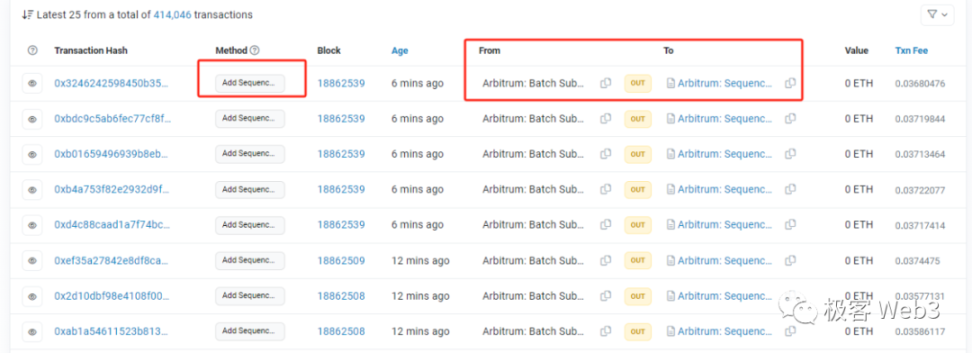
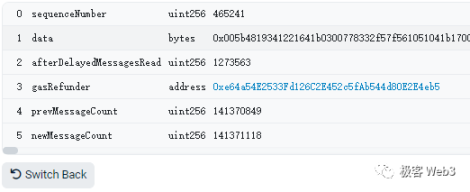
SequencerInbox 合约有两个主要函数:
add Sequencer L2Batch From Origin(),排序器每次都会调用该函数向 Sequencer Inox 合约提交 Batch 数据。
force Inclusion(),该函数任何人都可以调用,用于实现抗审查交易。这个函数的生效方式,会在后面谈到 Delayed Inbox 合约时详细解释。
上述两个函数都会调用 bridge.enqueueSequencerMessage(),来更新 bridge 合约内的累加器参数 accumulator。
Gas 定价
显然,L2 的交易不可能免费,因为这样会引来 DoS 攻击,另外则是排序器 L2 本身的运⾏成本,以及在 L1 上提交数据都会有开销。⽤户在 Layer2 网络内发起交易时,gas 费的结构如下:
占用 Layer1 资源产生的数据发布成本,主要来自于排序器提交的 batch(每个 batch 有很多用户的交易),成本最终由交易发起者们均摊。数据发布产生的手续费定价算法是动态的,排序器会根据近期的盈亏状况、batch ⼤⼩、当前以太坊 gas 价格进⾏定价。
用户因占用 Layer2 资源产生的成本,设定了⼀个可以保证系统稳定运⾏的,每秒处理的 gas 上限(⽬前 Arbitrum One 是 700 万)。L1 和 L2 的 gas 指导价格均由 ArbOS 跟踪并调整,公式暂时不在此赘述。
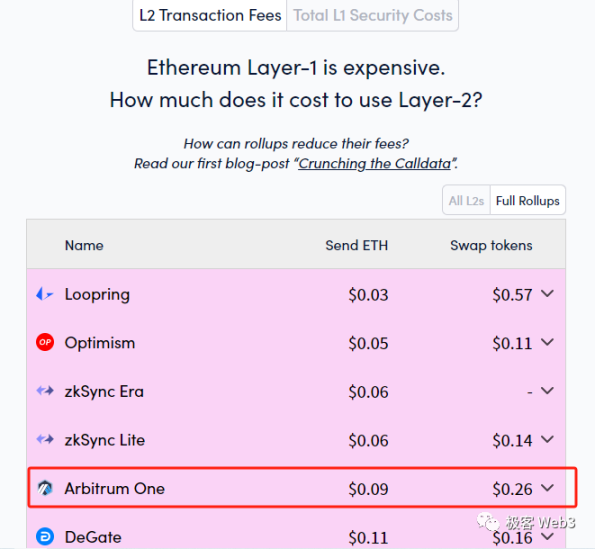
虽然具体的 gas 价格计算过程⽐较复杂,但⽤户无需感知到这些细节,可以明显感到 Rollup 交易费⽤比 ETH 主网便宜的多。
乐观式欺诈证明
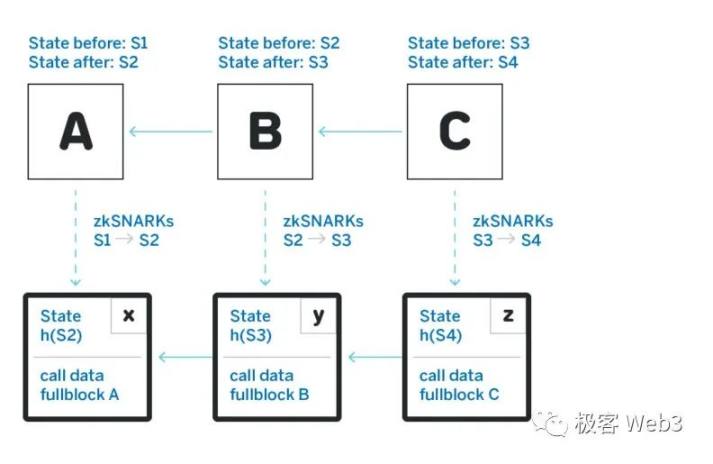
回顾上文,L2 实际上只是排序器在快箱中提交的交易输入 batch 的投影,也即:
Transaction Inputs -> STF -> State Outputs。输入已经确定,STF 是不变的,则输出结果也是确定的,而欺诈证明和 Arbitrum Rollup 协议这套系统就是把输出的状态根,以 RBlock (aka 断言)的形式发布到 L1 上并对其进行乐观式证明的一套系统。
在 L1 上有排序器发布的输⼊数据,也有验证者发布的输出状态。我们再仔细考量⼀下,是否有必要向链上发布 Layer2 的状态呢?
因为输⼊已经完全决定了输出,而输入数据是公开可见的,再提交输出结果 - 状态似乎是多余的?但这种想法忽略了 L1-L2 两个系统之间实际上需要状态结算,也即 L2 向 L1 ⽅向的提现⾏为,需要有对状态的证明。
在搭建 Rollup 的时候,⼀条最核⼼的思想就是把⼤部分运算和存储放到 L2 上来规避 L1 ⾼昂的费⽤,这也就意味着,L1 并不知道 L2 的状态,它仅仅帮助 L2 排序器发布全体交易的输入数据,但并不负责计算出 L2 的状态。
⽽提现⾏为,本质上是依照 L2 给出的跨链消息,从 L1 的合约⾥解锁相应资⾦,划转到⽤户的 L1 账户中或完成其他事情。
此时 Layer1 的合约就会问:你在 Layer2 上的状态是怎样的,怎么证明你真的拥有这些声明要跨走的资产。这个时候用户要给出对应该的 Merkle Proof 等。
所以,如果我们构建⼀条没有提现功能的 Rollup,理论上不向 L1 进⾏状态同步是可以的,也不需要欺诈证明等状态证明系统(虽然可能带来其他问题)。但在现实应⽤中,这显然是不可⾏的。
所谓的乐观式证明中,合约不会去检查提交到 L1 的输出状态是否正确,乐观地认为一切都是准确无误的。乐观证明系统会假设,在任意时刻都有⾄少⼀名诚实的 Validator,如果出现错误的状态,则通过欺诈证明进⾏挑战。
这么设计的好处是,不需要主动验证每⼀个发布到 L1 上的 RBlock,避免浪费 gas。实际上对于 OPR ⽽⾔,对每⼀个断⾔进⾏验证也是不现实的,因为每个 Rblock 都包含着一或多个 L2 区块,要在 L1 上去对每笔交易重新执⾏⼀遍,与直接在 L1 上执行 L2 交易无异,这就失去了 Layer2 扩容的意义。
⽽ ZKR 不存在这个问题,因为 ZK Proof 有简洁性,只需要验证⼀个很⼩的 Proof,不需要真地去执⾏该 Proof 背后所对应的许多条交易。所以 ZKR 并不是乐观式运⾏,每次发布状态都会有 Verfier 合约进⾏数学验证。
欺诈证明虽然不能像零知识证明那样具有⾼度的简洁性,但 Arbitrum 使⽤了⼀种「多轮分割 - 单步证明」的轮流式交互流程,最终需要证明的仅仅是单⼀的虚拟机操作码,成本相对较⼩。
Rollup 协议
我们先来看一下,发起挑战和启动证明的入口,也即 Rollup 协议是如何工作的。
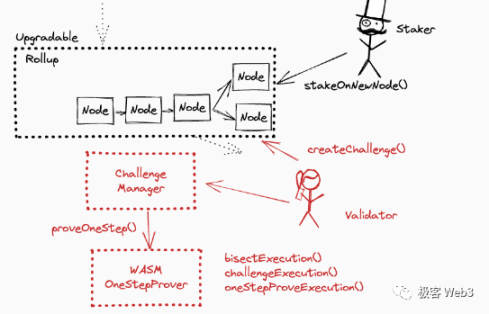
Rollup 协议的核心合约是 RollupProxy.sol,在保证数据结构一致的情况下,使用了一个罕见的双重代理结构,一个代理对应两个实现 RollupUserLogic.sol 和 RollupAdminLogic.sol,在 Scan 等工具中目前还无法很好的解析。
另外还有ChallengeManager.sol 合约负责管理挑战,OneStepProver 系列合约来判定欺诈证明。
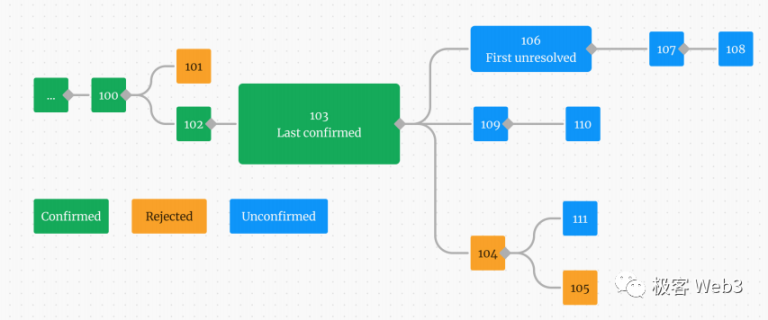
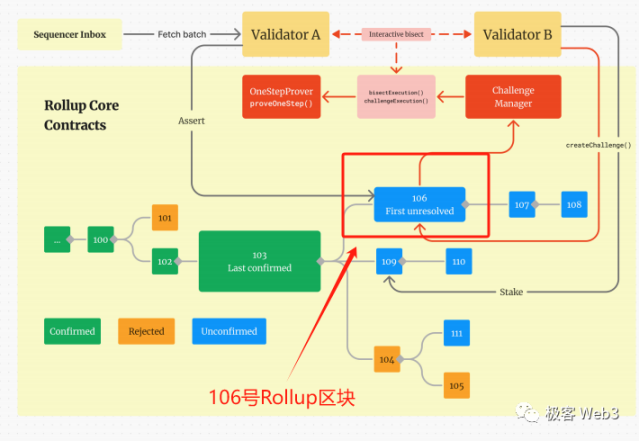
在 RollupProxy 中,记录由不同 Validator 提交的一系列 RBlock(aka 断言),也即下图中的方块:绿色 - 已确认,蓝色 - 未确认,黄色 - 已证伪。
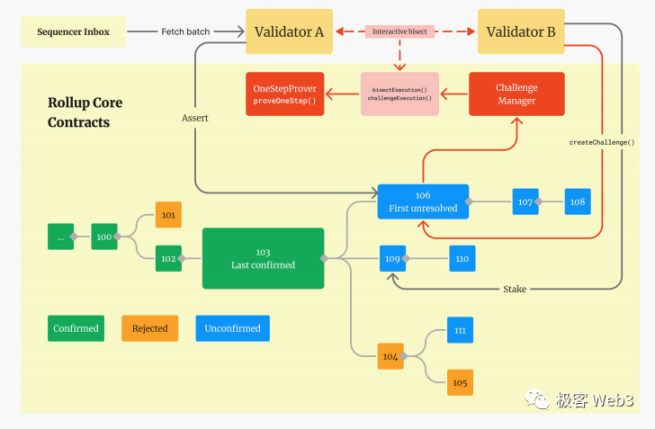
RBlock 中包含了自上一个 RBlock 以来,一个或多个 L2 区块执行后的最终状态。这些 RBlock 在形态上构成了一条形式上的 Rollup Chain(注意 L2 账本本身相区别)。在乐观情况下,这条 Rollup Chain 应该是没有分叉的,因为有分叉意味着有 Validator 提交了彼此冲突的 Rollup Block。
要提出或认同断言,需要验证者先为该断言质押一定数量的 ETH,成为 Staker。这样在发生挑战 / 欺诈证明时,输者的质押品将被罚没,这是保障验证者诚实行为的经济学基础。
图中右下角的 111 号蓝色块最终会被证伪,因为其父块 104 号区块是错误的(黄色)。
此外,验证者 A 提出了 106 号 Rollup Block,而 B 不同意,对其进行挑战。
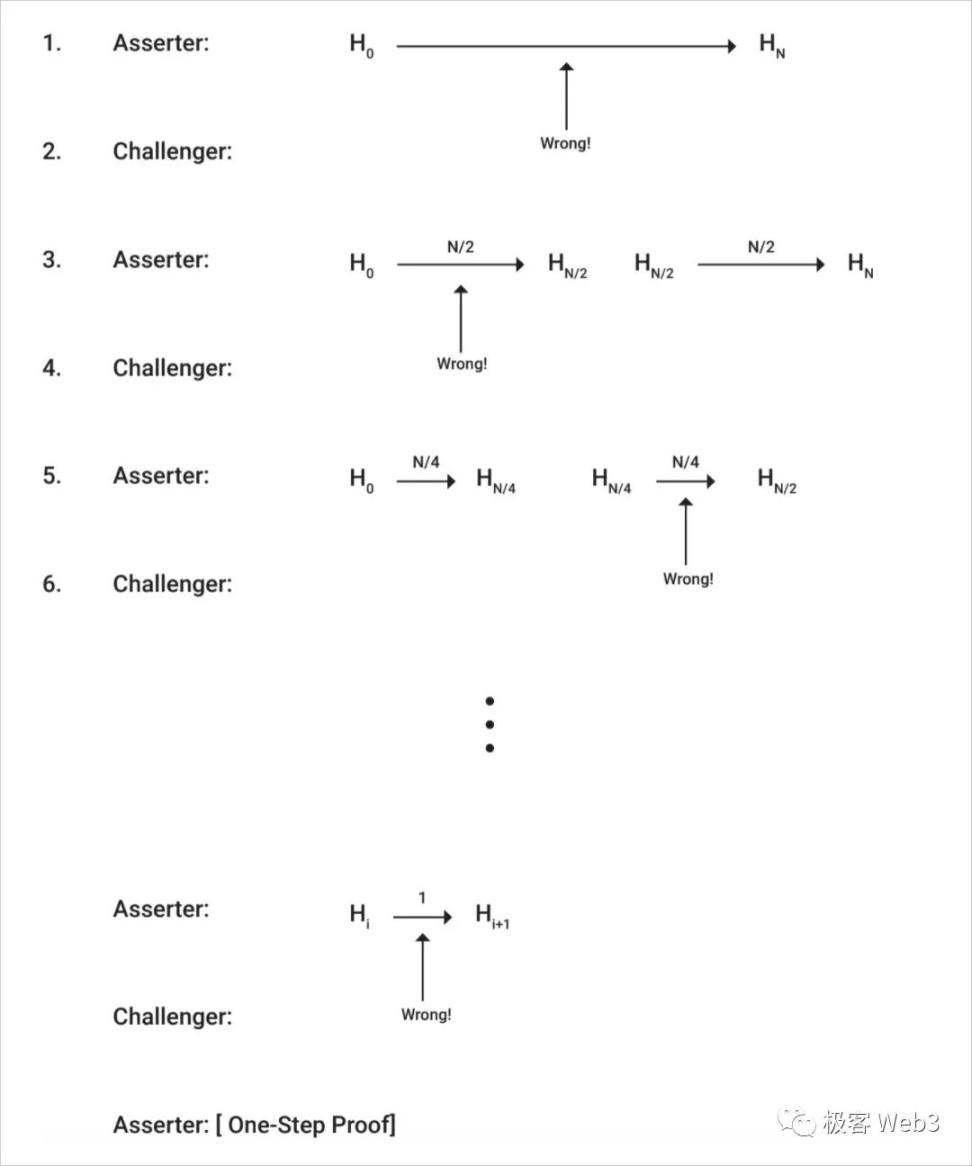
在 B 发起挑战后,ChallengeManager 合约负责验证对挑战步骤的细分过程:
1.细分是一个双方轮流互动的过程,一方对某个 Rollup Block 中包含的历史数据进行分段,另一方指出是哪部分数据片段有问题。类似于二分法(实际是 N/K)不断渐进缩小范围的一个过程。
2.之后,可以继续定位至哪条交易及结果有问题,再进一步细分至该交易中有争议的某条机器指令。
3.ChallengeManager 合约只检查对原始数据进行细分后,产生的『数据片段』是否有效。
4.当挑战者和被挑战者定位到了将被挑战的那条机器指令后,挑战者调用 oneStepProveExecution(),发送单步欺诈证明,证明这条机器指令的执行结果有问题。
单步证明
单步证明是整个 Arbitrum 的欺诈证明的核心。我们看一下单步证明具体证明的是什么内容。
这需要先理解 WAVM,Wasm Arbitrum Virtual Machine,它是一个由 ArbOS 模块和 Geth(以太坊客户端)核心模块共同编译成的虚拟机。由于 L2 与 L1 有许多截然不同的地方,原始的 Geth 核心必须经过轻量修改,并且配合 ArbOS 一起工作。
所以,L2 上的状态转换其实是 ArbOS+Geth Core 的共同手笔。
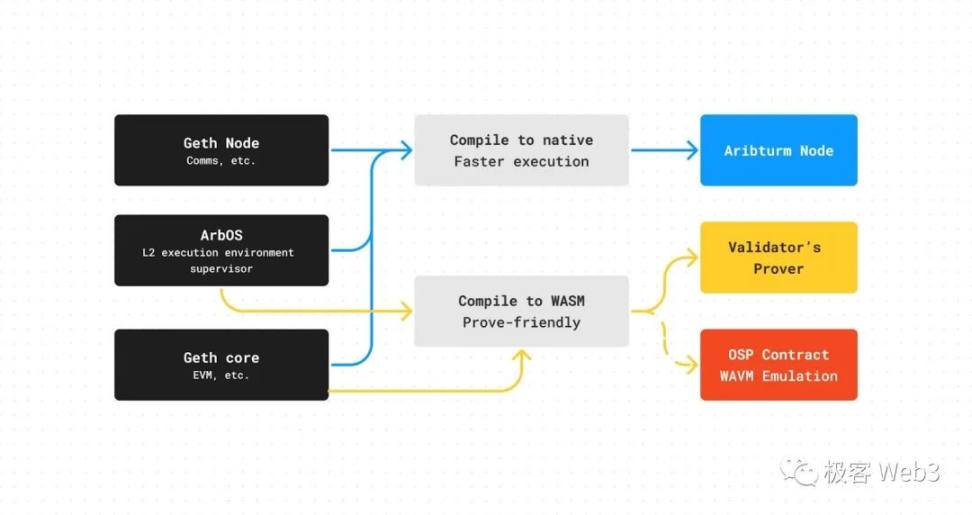
Arbitrum 的节点客户端(排序器、验证者、全节点等),是将上述 ArbOS+Geth Core 处理的程序,编译为节点主机能直接处理的原生机器代码(for x86/ARM/PC/Mac/etc.)。
如果把编译后得到的目标语言更改为 Wasm,就得到了验证者生成欺诈证明时使用的 WAVM,而验证单步证明的合约上,模拟的也是 WAVM 虚拟机的功能。
那为什么在生成欺诈证明时,要编译为 Wasm 字节码?主要还是因为,验证单步欺诈证明的合约,要用以太坊智能合约模拟出 能处理某套指令集的虚拟机 VM,而 WASM 易于在合约上实现模拟。
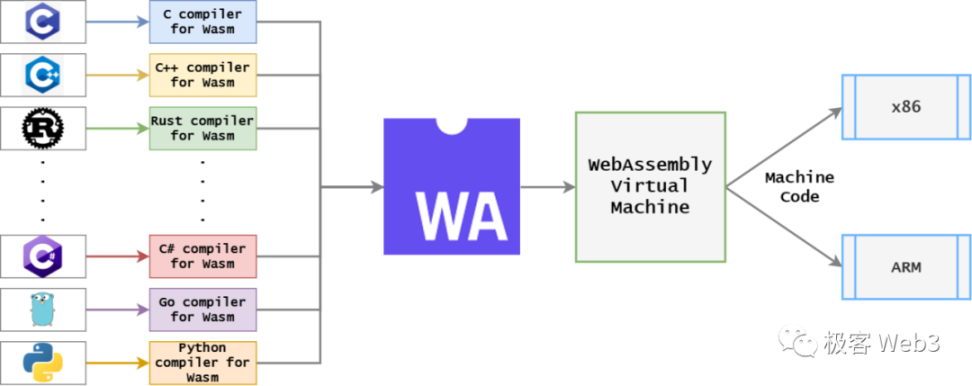
但 WASM 相比于 Native 机器代码,运行速度略慢,所以只有在欺诈证明生成及验证的时候,Arbitrum 的节点 / 合约才会用到 WAVM。
在之前的多轮互动细分后,单步证明最终证明的是 WAVM 指令集中的单步指令。
下面的代码中可以看到,OneStepProofEntry 首先要判定,待证明指令的操作码属于哪个类别,再调用相应的 prover 如 Mem,Math 等,将单步指令传入该 prover 合约。
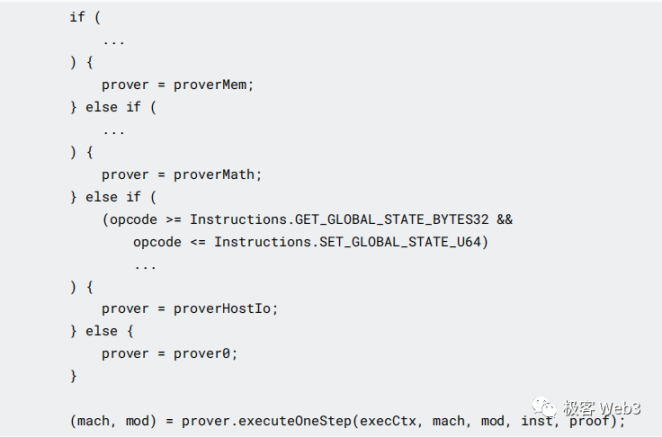
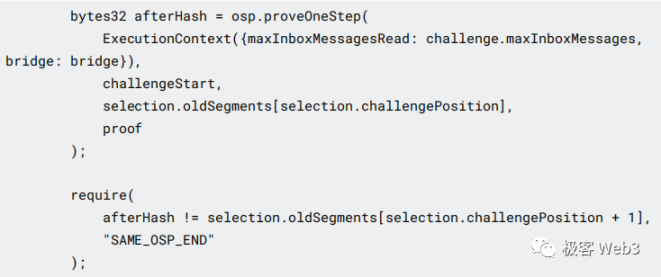
最终结果 afterHash 会回到 ChallengeManager,如果该哈希与 Rollup Block 上记录的,指令运算后的哈希不一致,则挑战成功。如果一致,则说明 Rollup Block 上记录的这个指令运行结果没问题,挑战失败。
在下一篇文章中,我们将解析 Arbitrum 乃至于 Layer2 与 Layer1 之间处理跨链消息 / 桥接功能 的合约模块,并进一步阐明,一个真正意义的 Layer2 应该怎么实现抗审查。












 APP
APP 
