





撰文:Vitalik Buterin
编译:Yangz,Techub News
起初,以太坊的路线图中有两种扩展策略。其一(可参见 2015 年的早期论述)是「分片」(sharding):每个节点只需验证和存储链上的一小部分交易,而不是所有交易。任何其他点对点网络(如 BitTorrent)都是这样运行的,因此我们肯定也能让区块链以同样的方式运行。另一种方法是 Layer 2 协议,即在以太坊之上建立网络,使其能够充分受益于以太坊的安全性,同时将大部分数据和计算放到主链之外。「Layer 2 协议」从 2015 年的状态通道(state channels),到 2017 年的Plasma,最后在 2019 年发展为Rollups。Rollups 比前两者更强大,但也需要大量链上数据带宽。幸运的是,到 2019 年,分片研究已经解决了大规模验证「数据可用性」的问题。因此,这两条道路交汇在了一起,我们有了以 Rollup 为中心的路线图,这也是以太坊今天的扩展策略。
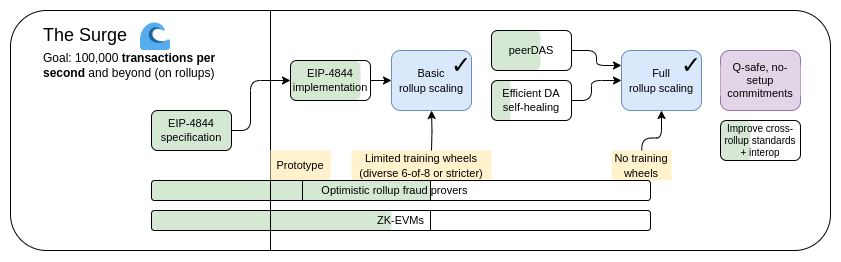
The Surge,2023 年路线图版本
以太坊 L1 专注于成为一个强大的去中心化基础层,而 L2 则承担起帮助生态扩展的任务。这种模式在社会中随处可见,比如法院系统(L1)并不是为了超高的案件处理效率而存在的,它是为了保护合同和产权,而企业家们(L2)则是为了在这个坚固的基础层之上,将人类带上火星。
今年,以太坊以 Rollup 为中心的路线图取得了重大成功:以太坊 L1 数据带宽随着EIP-4844 blobs的使用而大大增加,多个 EVM Rollups 现在处于第一阶段。此外,分片的异构和多元化实现已经成为现实,每个 L2 都可作为一个「分片」,有自己的内部规则和逻辑。但是,正如我们所看到的,走这条路本身也有一些独特的挑战。因此,我们目前的任务是完成以 Rollup 为中心的路线图,并解决这些问题,同时保持以太坊 L1 的鲁棒性和去中心化特性。
The Surge 的主要目标:
-
在 L1+L2 上实现 10 万+ TPS
-
保留 L1 的去中心化和鲁棒性
-
至少有一些 L2 完全继承以太坊的核心属性(去信任、开放、抗审查)
-
L2 之间最大程度的互操作性。以太坊应该是一个生态系统,而不是 34 条不同的区块链
不可能三角
区块链「不可能三角」是我在 2017 年提出的一个观点,认为区块链的三个特性之间存在矛盾,包括去中心化(以低成本运行节点)、可扩展性(处理的交易数量多)和安全性(攻击者需要破坏整个网络中的大部分节点,才能使单笔交易失败)。
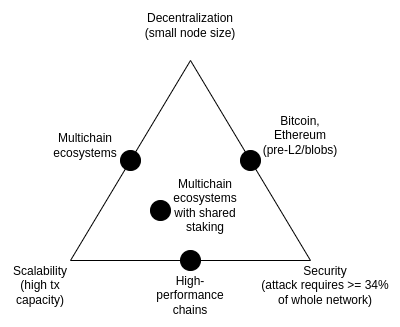
值得注意的是,不可能三角并不是一个定理,介绍该困境的帖子也没有附带数学证明。它确实给出了一个启发式的数学论证:如果一个对去中心化友好的节点(如消费者的笔记本电脑)每秒可以验证 N 笔交易,而你有一条每秒处理 k*N 笔交易的链,那么要么每笔交易只被 1/k 个节点看到,意味着攻击者只需要破坏几个节点就能将一笔糟糕的交易推送出去,要么节点就会变得很强大,而链就丢失了去中心化这一特性。当时的帖子并不是要说明打破不可能三角是不可能的;相反,我想说明的是,打破该困境是很难的,需要以某种方式跳出论证所暗示的框框。
多年来,一些高性能链通常会称自己无需在基本架构层面做任何提升(通常是通过使用软件工程技巧来优化节点),就能解决不可能三角问题。这种说法往往具有误导性,在这种链上运行节点的难度其实比在以太坊上要大得多。这篇文章深入探讨了为什么会出现这种情况的许多微妙之处,同时也解释了为什么仅靠 L1 客户端软件工程无法扩展以太坊本身。
不过,数据可用性采样和 SNARKs 的结合确实解决了该困境。通过两者的结合,客户端可以验证一定数量的数据是否可用,以及一定数量的计算步骤是否正确执行,同时只下载其中一小部分数据,并运行小得多的计算量。SNARK 是去信任的,而数据可用性采样则有一个细微的few-of-N信任模型,但它保留了不可扩展链所具有的基本特性,即即使是 51% 的攻击也无法迫使网络接受有害区块。
解决不可能三角的另一种方法是 Plasma 架构,这种架构使用巧妙的技术,以一种激励兼容的方式将观察数据可用性的责任推给用户。早在 2017-2019 年,当我们只能通过欺诈证明来扩展计算规模时,Plasma 能安全完成的工作非常有限,但 SNARKs 的主流化使得 Plasma 架构在更广泛的用例中比以前更可行数据可用性采样的进一步进展。
数据可用性采样的进一步进展
我们要解决什么问题?
截至 2024 年 3 月 13 日,即Dencun 升级上线之时,以太坊在每 12 秒 slot 中有三个约 125 kB 大小的「blob」,即每个 slot 有约 375 kB 的数据可用性带宽。假设交易数据是直接在链上发布的,ERC20 的传输量约为 180 字节,因此以太坊上 Rollups 的最大 TPS 为:375000/12/180 = 173.6 TPS
如果我们加上以太坊的 calldata(理论上最大值为:每 slot 3000 万 gas/每字节 16 gas = 每 slot 187.5 万字节),这就变成了 607 TPS。对于 PeerDAS,我们的计划是将 blob 计数目标提高到 8-16,这将为我们提供 463-926 TPS 的 calldata。
这比以太坊 L1 有了很大的提升,但还不够。我们想要更高的可扩展性。我们的中期目标是每 slot 16 MB,如果结合 Rollup 数据压缩方面的改进,我们将获得约 5.8 万 TPS。
PeerDAS 是什么,如何运作?
PeerDAS 是「1D sampling」的一种相对简单的实现方式。以太坊中的每个 blob 都是 253 位素数域上的一个 4096 度多项式。我们广播多项式的「份额」(shares),每个份额由相邻 16 个坐标的 16 次估算组成,这些坐标取自总共 8192 个坐标。8192 次评估中的任意 4096 次估算(使用当前建议的参数:128 个可能样本中的任意 64 个)都可以恢复 blob。
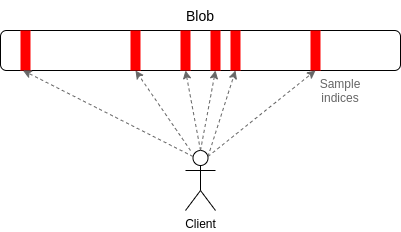
PeerDAS 的运作原理是让每个客户端监听少数几个子网,其中第 i 个子网广播任何 blob 的第 i 个样本,并通过向全球 p2p 网络中的同行(监听不同子网的同行)询问它所需的其他子网上的 blob。一个更保守的版本是SubnetDAS,它只使用子网机制,而没有询问同行的附加层。目前的建议是,参与权益证明的节点使用 SubnetDAS,其他节点使用 PeerDAS。
从理论上讲,我们可以将 1D sampling 扩展到相当大的范围。如果我们将 blob 计数最大值提高到 256(因此,目标值为 128),那么我们就能达到 16 MB 的目标值,而数据可用性采样只需耗费每 slot 1 MB (每个节点 16 个样本 * 128 个 blob * 每个 blob 每个样本 512 字节)的数据带宽即可。然而,这只勉强在我们的承受范围之内。我们可以做到,但这意味着带宽受限的客户端无法采样。我们可以通过减少 blob 数量和增大 blob 大小来进行优化,但这又会使重构成本提高。
因此,我们希望更进一步,进行2D sampling,即不仅在 blob 内,而且在 blob 之间进行随机采样。我们利用 KZG 承诺的线性特性,通过冗余编码相同信息的新「虚拟 blobs」列表来「扩展」区块中的 blobs 集。
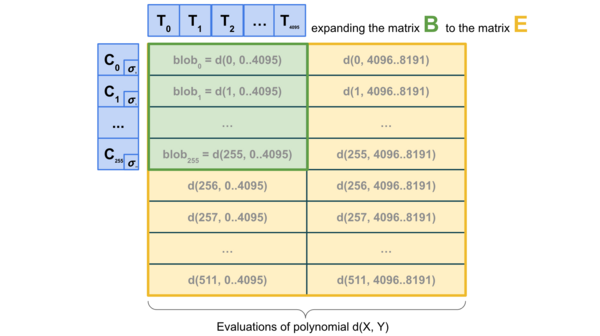
2D sampling;来源:a16z crypto
最重要的是,计算承诺的扩展并不需要拥有 blobs,因此该方案从根本上有利于分布式区块构建。实际构建区块的节点只需拥有 blob KZG 承诺,就可以依靠 DAS 来验证 blob 的可用性。1D DAS 在本质上也有利于分布式区块构建。
现有的相关研究
-
介绍数据可用性的原帖(2018 年):https://github.com/ethereum/research/wiki/A-note-on-data-availability-and-erasure-coding
-
后续论文:https://arxiv.org/abs/1809.09044
-
Paradigm 关于 DAS 的解释性帖子:https://www.paradigm.xyz/2022/08/das
-
带有 KZG 承诺的 2D 可用性:https://ethresear.ch/t/2d-data-availability-with-kate-commitments/8081
-
ethresear.ch 上关于 PeerDAS 的研究:https://ethresear.ch/t/peerdas-a-simpler-das-approach-using-battle-tested-p2p-components/16541,即相关论文:https://eprint.iacr.org/2024/1362
-
EIP-7594:https://eips.ethereum.org/EIPS/eip-7594
-
ethresear.ch 上关于 SubnetDAS 的研究:https://ethresear.ch/t/subnetdas-an-intermediate-das-approach/17169
-
2D sampling 中可恢复性的细微差别:https://ethresear.ch/t/nuances-of-data-recoverability-in-data-availability-sampling/16256
还有哪些工作要做,如何权衡?
当务之急是完成 PeerDAS 的实施和推广。我们需要逐步增加 PeerDAS 上的 blob 数量,同时仔细观察网络并改进软件,以确保安全。与此同时,我们希望开展更多的学术工作,使 PeerDAS 和其他版本的 DAS 及其与分叉选择规则安全等问题的交互正规化。
未来,我们还需要做更多的工作,找出理想版本的 2D DAS 并证明其安全属性。我们还希望最终从 KZG 迁移到抗量子、无可信设置的替代方案。目前,我们还不知道有哪些候选方案对分布式区块构建友好。即使使用费用极高的「暴力」技术,即使用递归 STARK 生成有效性证明来重建行和列也是不够的,因为从技术上讲,一个 STARK 的大小(使用 STIR)是 O(log(n) * log(log(n)) 哈希值,但实际上一个 STARK 几乎和整个 blob 一样大。
从长远来看,我认为最现实的途径是:
-
实现理想的 2D DAS
-
坚持 1D DAS,牺牲采样带宽效率并接受较低的数据上限,以求简单和稳健
-
(硬支点)放弃 DA,完全采用 Plasma 作为我们关注的主要 layer 2 架构
我们可以根据下图来权衡这些问题:
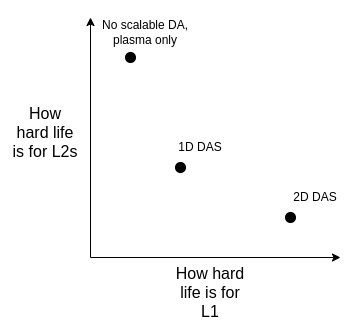
请注意,即使我们决定直接在 L1 上扩展执行,这种选择也是存在的。因为,如果 L1 要处理大量的 TPS,那么 L1 区块就会变得非常大,而客户端需要一种有效的方式来验证它们是否正确,因此我们必须在 L1 上使用与 Rollup(ZK-EVM 和 DAS)相同的技术。
对路线图的其他部分有何影响?
如果实现了数据压缩(见下文),那么对 2D DAS 的需求就会有所减少,或者至少会有所延迟;如果 Plasma 得到广泛应用,那么对它的需求就会进一步减少。DAS 还对分布式区块构建协议和机制提出了挑战:虽然 DAS 在理论上对分布式重构是友好的,但在实践中需要与包含列表建议及其周围的分叉选择机制相结合。
数据压缩
我们要解决什么问题?
Rollup 中的每笔交易都会占用链上大量的数据空间:ERC20 的传输大约需要 180 个字节。即使有理想的数据可用性采样,也会对 Layer 2 协议的可扩展性造成限制。每个 slot 16 MB,我们可以得到:16000000/12/180 = 7407 TPS
如果除了解决分子的问题,我们还能解决分母的问题,让 Rollup 中的每笔交易在链上占用更少的字节,那会怎样?
如何进行数据压缩?
在我看来,两年前的这张图就是最好的解释:
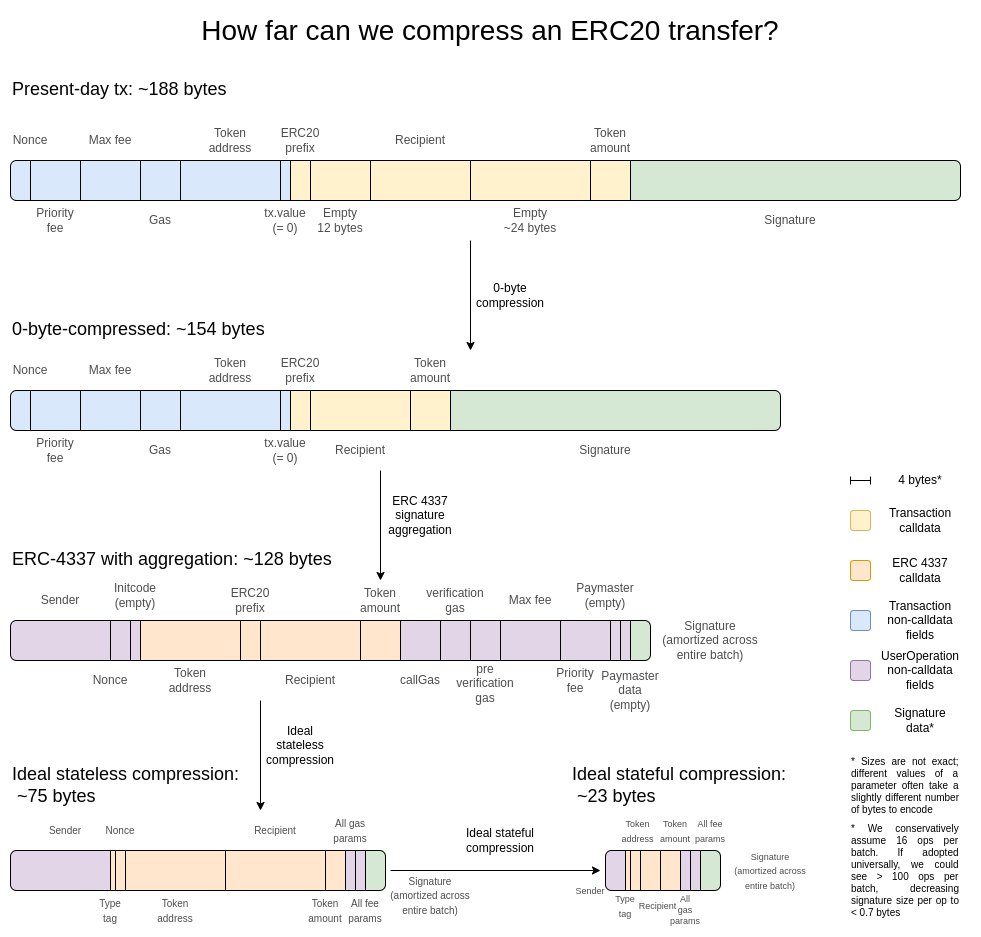
最简单的增益就是零字节压缩:用代表零字节数量的两个字节替换每个长的零字节序列。为更进一步,我们利用了交易的特殊属性:
-
签名聚合:我们将 ECDSA 签名转换为 BLS 签名。BLS 签名的特性是,许多签名可以合并为一个签名,证明所有原始签名的有效性。这种方法在 L1 中没有被应用,因为即使使用聚合的方式,验证的计算成本也会更高,但在像 L2 这样数据稀缺的环境中,可以说这是合理的。ERC-4337的聚合功能提供了一种实现途径。
-
用 pointer 取代地址:如果一个地址以前使用过,我们可以用一个指向历史位置的 4 字节 pointer 取代 20 字节的地址。要想获得最大收益,就必须这样做,不过实施起来需要付出努力,因为这需要(至少一部分)区块链历史有效地成为状态的一部分。
-
交易值的自定义序列化:大多数交易值的数字很少,例如 0.25 ETH 表示为 250,000,000,000,000,000 wei。Gas max-basefees 和优先级费用的工作原理类似。因此,我们可以使用自定义的十进制浮点格式,甚至是特别常用值的归集来简洁地表示大多数币值。
现有的相关研究
-
来自 sequence.xyz 的探索:https://sequence.xyz/blog/compressing-calldata
-
来自 ScopeLift 的针对 L2 Calldata 优化合约的研究:https://github.com/ScopeLift/l2-optimizoooors
-
基于有效性验证的 Rollups(即 ZK rollups)发布状态差异而非交易:https://ethresear.ch/t/rollup-diff-compression-application-level-compression-strategies-to-reduce-the-l2-data-footprint-on-l1/9975
-
BLS 钱包:通过 ERC-4337 实现 BLS 聚合:https://github.com/getwax/bls-wallet
还有哪些工作要做,如何权衡?
剩下要做的主要是实际实施上述计划。主要的权衡是:
-
改用 BLS 签名需要耗费大量精力,而且会降低与可提高安全性的可信硬件芯片的兼容性。可以使用其他签名方案的 ZK-SNARK wrapper 来替代。
-
动态压缩(如用 pointers 替换地址)会使客户端代码复杂化。
-
将状态差异发布到链上而不是交易上会降低可审计性,并使许多软件(如区块浏览器)无法工作。
对路线图的其他部分有何影响?
采用 ERC-4337 并最终将其部分内容纳入 L2 EVM,可以大大加快聚合技术的部署。将 ERC-4337 的部分内容纳入 L1 可以加快其在 L2 上的部署。
Plasma
我们要解决什么问题?
即使使用 16 MB blobs 和数据压缩技术,58000 TPS 也不一定足以完全接管消费支付、去中心化社交或其他高带宽领域,如果我们开始考虑隐私问题,情况会变尤其明显,可能会使可扩展性下降 3-8 倍。对于高流量、低价值的应用,目前的一种选择是 validium,它将数据保存在链外,并有一个有趣的安全模型,即运营商无法窃取用户的资金,但他们可以消失,并暂时或永久冻结所有用户的资金。然而,我们可以做得更好。
Plasma 是什么,如何运作?
Plasma 是一种扩展解决方案,涉及运营商在链外发布区块,并将这些区块的 Merkle 根放到链上(与 Rollup 不同,Rollup 是将整个区块放到链上)。对于每个区块,运营者都会向每个用户发送一个 Merkle 分支,证明该用户的资产发生了什么或没有发生什么。用户可以通过提供 Merkle 分支来提取资产。重要的是,该分支不必植根于最新状态。因此,即使数据可用性失效,用户仍可通过提取其可用的最新状态来恢复资产。如果用户提交了一个无效的分支(例如,撤回已经发送给他人的资产,或者运营者自己凭空创建了一个资产),链上质疑机制可以裁定资产的合法归属。
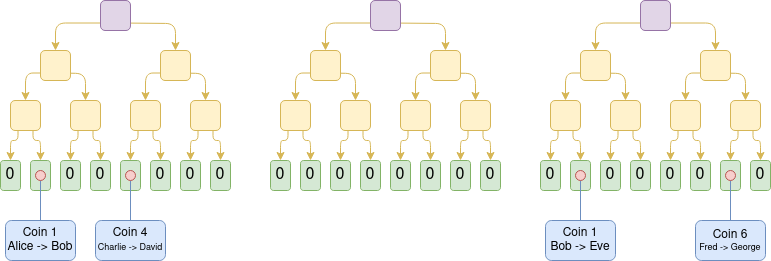
Plasma Cash chain 示意图
Plasma 的早期版本只能处理支付用例,无法有效地进一步推广。然而,如果我们要求每个根都要经过 SNARK 验证,Plasma 就会变得更加强大。每个挑战都可以大大简化,因为我们消除了运营者作弊的大部分可能途径。我们还开辟了新的途径,使 Plasma 技术可以扩展到更广泛的资产类别。最后,在运营者没有作弊的情况下,用户可以立即提取资金,而无需等待一周的挑战期。
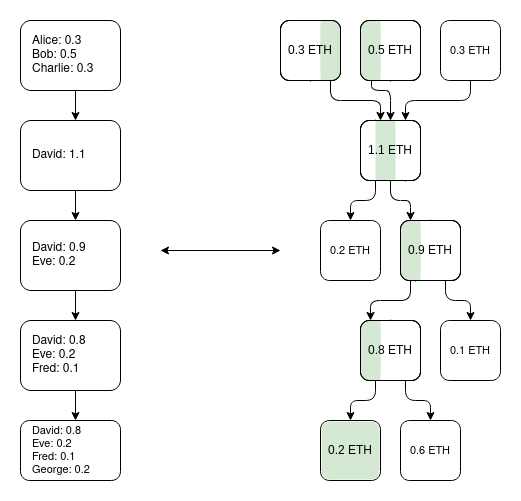
打造 EVM plasma chain 的一种方法(并非唯一方法):使用 ZK-SNARK 构建一个平行的 UTXO 树,该树反映了 EVM 所做的平衡变化,并定义了历史上不同时刻「相同币」的独特映射。然后在此基础上构建 Plasma 结构。
需要注意的是,Plasma 系统并不需要完美无缺。即使你只能保护资产的一个子集,你也已经大大改善了超可扩展 EVM 的现状,这就是有效的。
另一类结构是混合 Plasma 和 Rollup,如Intmax。这些结构将每个用户的极少量数据(例如 5 字节)放在链上,从而获得了介于 Plasma 和 Rollup 之间的特性:在 Intmax 中,你可以获得极高的可扩展性和隐私性,不过即使在 16 MB 的世界里,理论上容量上限也只有大约 16,000,000 / 12 / 5 = 266,667 TPS。
现有的相关研究
-
Plasma:https://plasma.io/plasma-deprecated.pdf
-
Plasma Cash:https://ethresear.ch/t/plasma-cash-plasma-with-much-less-per-user-data-checking/1298
-
Plasma Cashflow:https://hackmd.io/DgzmJIRjSzCYvl4lUjZXNQ?view#
-
Intmax (2023):https://eprint.iacr.org/2023/1082
还有哪些工作要做,如何权衡?
剩下的主要任务是将 Plasma 系统投入生产。如上所述,Plasma 与 validium 并不是二元对立的:任何 validium 都可以通过在退出机制中加入 Plasma 特性,至少可在一定程度上提高其安全性能。研究工作的重点在于为 EVM 获取最佳特性(在信任要求、最坏情况下的 L1 gas 成本和 DoS 脆弱性方面),以及其他特定应用结构。此外,相对于 Rollup,Plasma 的概念复杂性更高,这需要通过研究和构建更好的通用框架来直接解决。
使用 Plasma 设计的主要代价是,它们更依赖于运营者,并且更难实现通用,尽管 Plasma 和 Rollup 的混合设计通常可以避免这一弱点。
对路线图的其他部分有何影响?
Plasma 解决方案越有效,L1 拥有高性能数据可用性功能的压力就越小。将活动转移到 L2 还能减少 L1 的 MEV 压力。
成熟的 L2 证明系统
我们要解决什么问题?
如今,大多数 Rollup 实际上还不是去信任的;安全委员会有能力推翻(optimistic 或 validity)证明系统的行为。在某些情况下,证明系统甚至根本不存在,即使存在,也只有「咨询」功能。目前走得最远的是一些针对特定应用的 Rollup,如 Fuel,它是去信任的;其次,截至本文撰写时,Optimism 和 Arbitrum,这两全 EVM Rollup 已经达到了部分去信任的里程碑,也就是我们所称的「stage 1」。Rollup 没有进一步实现去信任的原因是担心代码中的错误。我们需要去信任的升级,因此我们需要正面解决这个问题。
如何实现去信任的升级?
首先,让我们回顾一下最初介绍的「stage」系统,大致情况如下:
-
Stage 0:用户必须能够运行节点并同步链。如果验证是完全可信的/中心化的,就没问题。
-
Stage 1:必须有一个(去信任的)证明系统,确保只有有效的交易才能被接受。允许安全委员会推翻证明系统,但必须达到 75% 的投票门槛。此外,委员会中法定人数限制的部分(26% 以上)必须在 Rollup 构建者之外。允许使用功能较弱的升级机制(如 DAO),但必须有足够长的延迟时间,如果批准恶意升级,用户可以在升级上线前退出资金。
-
Stage 2:必须有一个(去信任的)证明系统,确保只有有效的交易才能被接受。只有在代码中出现可证明的错误时,例如两个冗余的证明系统相互不同意,或一个证明系统接受了同一区块的两个不同的后状态根(或在足够长的时间内(如一周)不接受任何东西),安全委员会才被允许干预。升级机制是允许的,但必须有很长的延迟时间。
我们的目标是达到 Stage 2。主要的挑战是获得足够的信心,证明系统确实足够可信。要做到这一点,主要有两种方法:
-
形式验证:我们可以使用现代数学和计算技术来证明(optimistic 或 validity)证明系统只接受通过 EVM 规范的区块。这些技术已经存在了几十年,但最新的进展(如Lean 4)使其更加实用。此外,人工智能辅助证明的进步有可能进一步加快这一趋势。
-
多验证器:制作多个验证系统,并将资金投入到这些验证系统与安全委员会(和/或其他具有信任假设的小工具,如 TEE)之间的 2-of-3(或更大)多验证器中。如果证明系统同意,安全委员会就没有权力;如果证明系统不同意,安全委员会只能选择其中之一,不能单方面强加自己的答案。
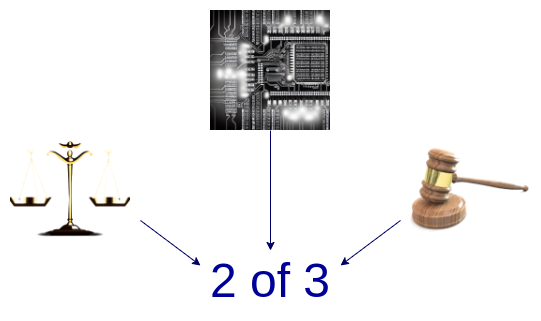
结合 optimistic 证明系统、 validity 证明系统和安全委员会的多验证器样式图
现有的相关研究
-
EVM K Semantics(2017年):https://github.com/runtimeverification/evm-semantics
-
关于多验证器想法的介绍(2022 年):https://www.youtube.com/watch?v=6hfVzCWT6YI
-
Taiko 计划使用多验证器:https://docs.taiko.xyz/core-concepts/multi-proofs/
还有哪些工作要做,如何权衡?
对于形式验证来说,我们还有很多工作要做。我们需要为 EVM 的整个 SNARK 验证器创建一个经过形式验证的版本。这是一个非常复杂的项目,但我们已经开始实施了,且有一个小窍门可以大大简化这项任务:我们可以构建一个最小虚拟机(如RISC-V或Cairo)的经过正式验证的 SNARK 验证器,然后在该最小虚拟机中编写 EVM 的实现(并正式证明其与其他 EVM 规范的等价性)。
对于多验证器来说,剩下的重点包括两个部分。首先,我们需要对至少两个不同的证明系统有足够的信心,既要相信它们各自都是相当安全的,又要相信如果它们发生故障,故障的原因是不同的、互不相关的(因此它们不会同时发生故障)。其次,我们需要在合并证明系统的底层逻辑中获得极高的保证。这是一段小得多的代码,有一些方法(只需将资金存储在一个Safe 多签合约中,其签名者代表各个证明系统的合约)可以让它变得非常小,但这样做的代价是高昂的链上 gas 成本。我们需要在效率和安全之间找到某种平衡。
对路线图的其他部分有何影响?
将活动转移到 L2 可以减少 L1 的 MEV 压力。
改进跨 L2 的互操作性
我们要解决什么问题?
目前,L2 生态面临的一个主要挑战是用户难以跨 L2 进行互操作,而最简单的方法往往会重新引入信任假设,包括中心化跨链桥、RPC 客户端等。如果我们认真对待「L2 是以太坊一部分」的理念,我们就需要让使用 L2 生态的感觉就像使用统一的以太坊生态一样。
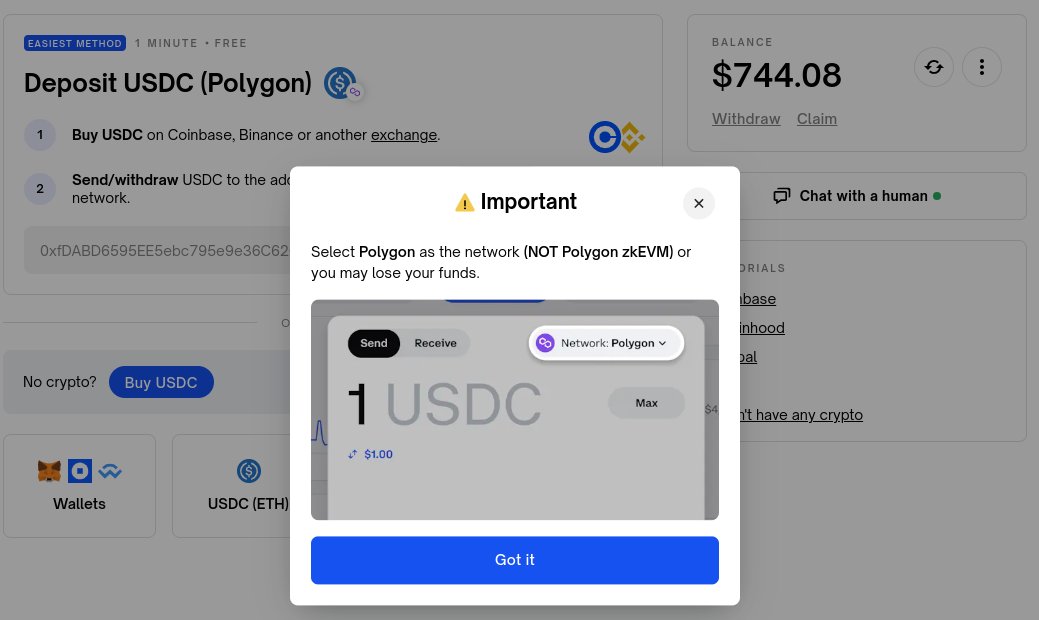
跨 L2 用户体验极差的一个例子(我个人就因为链选择错误损失了 100 美元):虽然这不是 Polymarket 的错,但跨 L2 互操作性应该是钱包和以太坊标准(ERC)社区的责任。在一个运作良好的以太坊生态中,从 L1 向 L2 或从一个 L2 向另一个 L2 发送代币,应该感觉就像在同一个 L1 中发送代币一样。
跨 L2 的互操作性如何改进?
跨 L2 的互操作性改进有很多方法。一般来说,只要意识到从理论上讲,以 Rollup 为中心的以太坊与 L1 执行分片是一回事,然后观察当前的各以太坊 L2 在实践中与这一理想有哪些差距,就可以得出结论。下面是一些例子:
-
特定链地址:链(L1、Optimism、Arbitrum......)可以是地址的一部分。一旦实现了这一点,只需将地址放入「send」字段,就能实现跨 L2 发送流程,此时钱包就能在后台找出发送方法(包括使用跨链协议)。
-
特定链的支付请求:「向我发送 Z 链上 Y 类型的 X 代币」这一信息应该是简单而标准化的。这有两种主要用例:首先是支付,无论是个人对个人还是个人对商家服务;其次是请求资金的 Dapp,例如上面的 Polymarket。
-
跨链兑换和 gas 支付:应该有一个标准化的开放协议来表达跨链操作,例如「我在 Optimism 上向 Arbitrum 上向我发送 0.9999 ETH 的人发送 1 ETH」,以及「我在 Optimism 上向 Arbitrum 上包含此交易的人发送 0.0001 ETH」。ERC-7683是对前者的一种尝试,而RIP-7755则是对后者的一种尝试,尽管两者都比这些特定用例更通用。
-
轻客户端:用户应能实际验证与之交互的链,而不仅仅是信任 RPC 提供商。A16z crypto 的轻客户端Helios帮以太坊做到了这一点,但我们需要将这种去信任扩展到 L2。ERC-3668(CCIP-read)是实现这一目标的策略之一。
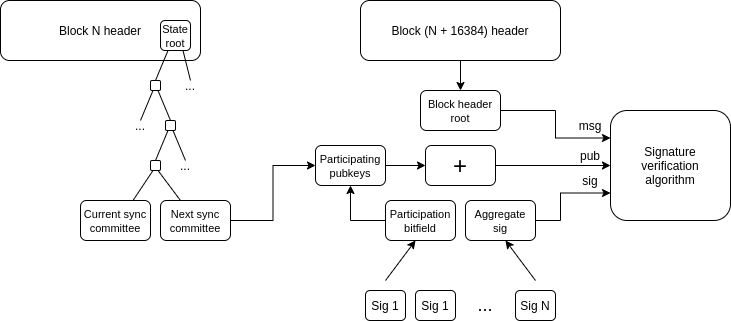
轻客户端如何更新以太坊 header chain:一旦拥有了 header chain,就可以使用 Merkle 证明来验证任何状态对象。一旦有了正确的 L1 状态对象,就可以使用 Merkle 证明(如果你想检查预先确认,还可以使用签名)来验证 L2 上的任何状态对象。Helios 已经实现了前者,扩展至后者则是一个标准化的挑战。
密钥存储钱包:如今,如果要更新控制智能合约钱包的密钥,必须在该钱包所在的所有 N 个链上进行更新。密钥存储钱包是一种技术,允许密钥存在于一个地方(或者在 L1 上,或者以后可能在 L2 上),然后可以从任何拥有钱包副本的 L2 上读取。这意味着更新只需进行一次。为了提高效率,密钥存储钱包要求 L2 有一种标准化的方式来低成本地读取 L1;有两个关于这方面的提议:L1SLOAD和REMOTESTATICCALL。
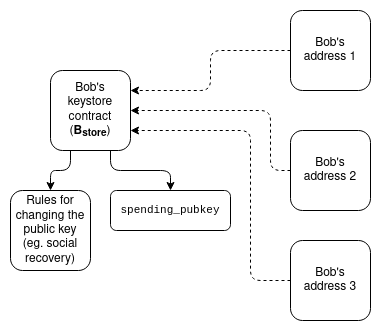
密钥存储钱包工作原理示意图
更激进的「共享代币桥」方案:想象一下这样一种情况,即所有的 L2 都是有效性证明 Rollup,每个 slot 都会提交到以太坊上,那么将资产「原生得」从一个 L2 转移到另一个 L2 也需要提款和存款,需要支付大量的 L1 gas。解决这个问题的一种方法是创建一个共享的最小 Rollup,其唯一的功能就是维护哪个 L2 拥有多少代币的余额,并允许通过任何一个 L2 发起的一系列跨 L2 发送操作来大规模更新这些余额。这将允许跨 L2 传输,而无需为每次传输支付 L1 gas,也无需使用基于流动性提供者的技术(如 ERC-7683)。
同步可合成性:允许在特定 L2 和 L1 之间或多个 L2 之间进行同步调用。这有助于提高 DeFi 协议的财务效率。前者可以在没有任何跨 L2 协调的情况下完成;后者则需要共享排序。Based Rollups自动适用于所有这些技术。
现有的相关研究
-
特定链地址(ERC-3770):https://eips.ethereum.org/EIPS/eip-3770
-
ERC-7683: https://eips.ethereum.org/EIPS/eip-7683
-
RIP-7755: https://github.com/wilsoncusack/RIPs/blob/cross-l2-call-standard/RIPS/rip-7755.md
-
Scroll 密钥存储钱包设计:https://hackmd.io/@haichen/keystore
-
Helios:https://github.com/a16z/helios
-
ERC-3668(有时称为 CCIP-read):https://eips.ethereum.org/EIPS/eip-3668
-
Justin Drake 提出的「基于(共享)预确认 」提议:https://ethresear.ch/t/based-preconfirmations/17353
-
l1sload (rip-7728): https://ethereum-magicians.org/t/rip-7728-l1sload-precompile/20388
-
Optimism 的 REMOTESTATICCALL:https://github.com/ethereum-optimism/ecosystem-contributions/issues/76
-
含有共享代币桥想法的 AggLayer:https://github.com/AggLayer
还有哪些工作要做,如何权衡?
上述许多例子都面临着何时标准化和标准化哪一层的难题。如果标准化过早,就有可能使劣质解决方案根深蒂固。如果标准化太晚,则有可能造成不必要的碎片化。在某些情况下,既有性能较弱但易于实施的短期解决方案,也有「最终正确」但需要数年才能实现的长期解决方案。
该部分的一个独特之处在于,这些任务不仅仅是技术问题,它们还是(甚至可能主要是!)社会问题。它们需要 L2、钱包和 L1 的合作。我们能否成功解决这个问题,考验着我们作为一个群体团结一致的能力。
对路线图的其他部分有何影响?
这些提议中的大多数都是「更高层」的结构,因此对 L1 的影响不大。共享排序是一个例外,它对 MEV 有很大影响。
扩展 L1
我们要解决什么问题?
如果 L2 的可扩展性和成功率都很高,但 L1 仍然只能处理极少量的交易,那么以太坊可能会面临许多风险:
-
ETH 的经济形势变得更加危险,这反过来又会影响网络的长期安全性。
-
许多 L2 因与 L1 上高度发达的金融生态紧密相连而受益,如果该生态大大削弱,成为 L2(而不是独立的 L1)的动力就会减弱
-
L2 需要很长时间才能获得与 L1 完全相同的安全保证。
-
如果 L2 出现故障(例如,由于运营者的恶意行为或消失),用户仍需通过 L1 才能恢复其资产。因此,L1 需要足够强大,至少能够偶尔实际处理某单个 L2 衰败后出现的高度混乱的情况。
出于这些原因,继续扩展 L1 本身的规模并确保它能继续支持越来越多的用例是非常有价值的。
如何扩展 L1?
最简单的扩展方法就是简单地增加 gas 上限。但是,这样做有可能使 L1 中心化,从而削弱以太坊 L1 强大的另一个重要特性,即其作为稳健基础层的可信度。人们一直在争论将 gas 上限增加到何种程度才是可持续的,以及这会根据其他哪些技术的实施而发生变化,以使更大的区块更容易验证(例如,历史过期、无状态、L1 EVM 有效性证明)。另一个需要不断改进的重要方面是以太坊客户端软件的效率,现在的客户端软件比五年前优化得多。有效的 L1 gas 限制增加策略将涉及加速这些验证技术。
另一种扩展策略涉及识别特定功能和计算类型,在不损害网络去中心化或其安全属性的情况下,使其成本更低。这方面的例子包括:
-
EOF:一种新的 EVM 字节码格式,对静态分析更友好,可加快实现速度。考虑到这些效率,EOF 字节码的 gas 成本可以更低。
-
多维 gas 定价:为计算、数据和存储建立单独的基础费用和限制,可以提高以太坊 L1 的平均容量,而不增加其最大容量(从而产生新的安全风险)。
-
降低特定操作码和预编译的 gas 成本:从历史上看,为了避免拒绝服务攻击,我们已经对某些定价过低的操作增加了几轮 gas 成本。而降低定价过高的操作的 gas 成本,我们其实可以做得更多。例如,加法比乘法便宜得多,但目前 ADD 和 MUL 运算代码的成本是一样的。我们可以让 ADD 更便宜,甚至让 PUSH 等更简单的操作码更便宜。整体而言,EOF 的成本更低。
-
EVM-MAX和SIMD:EVM-MAX(模块化算术扩展)旨在将更高效的本地大数模块化算术作为 EVM 的一个独立模块。由 EVM-MAX 计算得出的值只能由其他 EVM-MAX 操作码访问,除非特意输出;这为以优化格式存储这些值提供了更大的空间。SIMD(单指令多数据)允许在数值数组上高效执行同一指令。这两者结合在一起,可以在 EVM 旁创建一个功能强大的协处理器,用于更高效地执行加密操作。这对隐私协议和 L2 证明系统尤其有用,因此对 L1 和 L2 扩展都有帮助。
这些改进将在未来有关 Splurge 的文章中详细讨论。
最后,第三种策略是原生 Rollup 或「enshrined Rollups」:本质上讲,就是创建许多并行运行的 EVM 副本,从而产生与 Rollup 所能提供的等效的模型,但更原生地集成在协议中。
现有的相关研究
-
Polynya 的以太坊 L1 扩展路线图:https://polynya.mirror.xyz/epju72rsymfB-JK52_uYI7HuhJ-W_zM735NdP7alkAQ
-
多维 gas 定价:https://vitalik.eth.limo/general/2024/05/09/multidim.html
-
EIP-7706:https://eips.ethereum.org/EIPS/eip-7706
-
EOF:https://evmobjectformat.org/
-
EVM-MAX:https://ethereum-magicians.org/t/eip-6601-evm-modular-arithmetic-extensions-evmmax/13168
-
SIMD:https://eips.ethereum.org/EIPS/eip-616
-
原生 Rollup:https://mirror.xyz/ohotties.eth/P1qSCcwj2FZ9cqo3_6kYI4S2chW5K5tmEgogk6io1GE
-
Bankless 与 Max Resnick 就扩展 L1 的价值采访:https://x.com/BanklessHQ/status/1831319419739361321
-
Justin Drake 关于使用 SNARKs 和原生 Rollup 进行扩展的思考:https://www.reddit.com/r/ethereum/comments/1f81ntr/comment/llmfi28/
还有哪些工作要做,如何权衡?
扩展 L1 有三种策略,可单独或同时进行:
-
改进技术(如客户端代码、无状态客户端、历史过期),使 L1 更容易验证,然后提高 gas 上限
-
降低特定操作的成本,在不增加最坏情况风险的情况下提高平均容量
-
原生 Rollup,即「创建 EVM 的 N 个并行副本」,但保留允许开发人员在部署副本参数上有很大灵活性的可能
值得注意的是,这些技术各不相同,各有利弊。例如,原生 Rollup 在可组合性方面有许多与普通 Rollup 相同的弱点。提高 gas 限制会影响其他好处,而这些好处可以通过让 L1 更容易验证来实现,比如增加运行验证节点的用户比例,以及增加单一质押者。降低 EVM 中特定操作的成本(取决于如何操作)会增加 EVM 的总复杂度。
L1 扩展路线图需要回答的一个大问题是:什么应归属于 L1,什么应归属于 L2?显然,将所有东西都放在 L1 上是荒谬的。高达每秒数十万笔交易的潜在用例,将使 L1 完全无法验证(除非我们走原生 Rollup 路线)。我们确实需要一些指导原则,这样才能确保我们不会造成这样一种情况,即我们将 gas 限制提高了 10 倍,严重破坏了以太坊 L1 的去中心化,却发现我们只是实现了 90% 的活动都在 L2 上,而不是 99%,除了不可逆转地丧失了以太坊 L1 的大部分特色之外,其他结果看起来几乎是一样的。
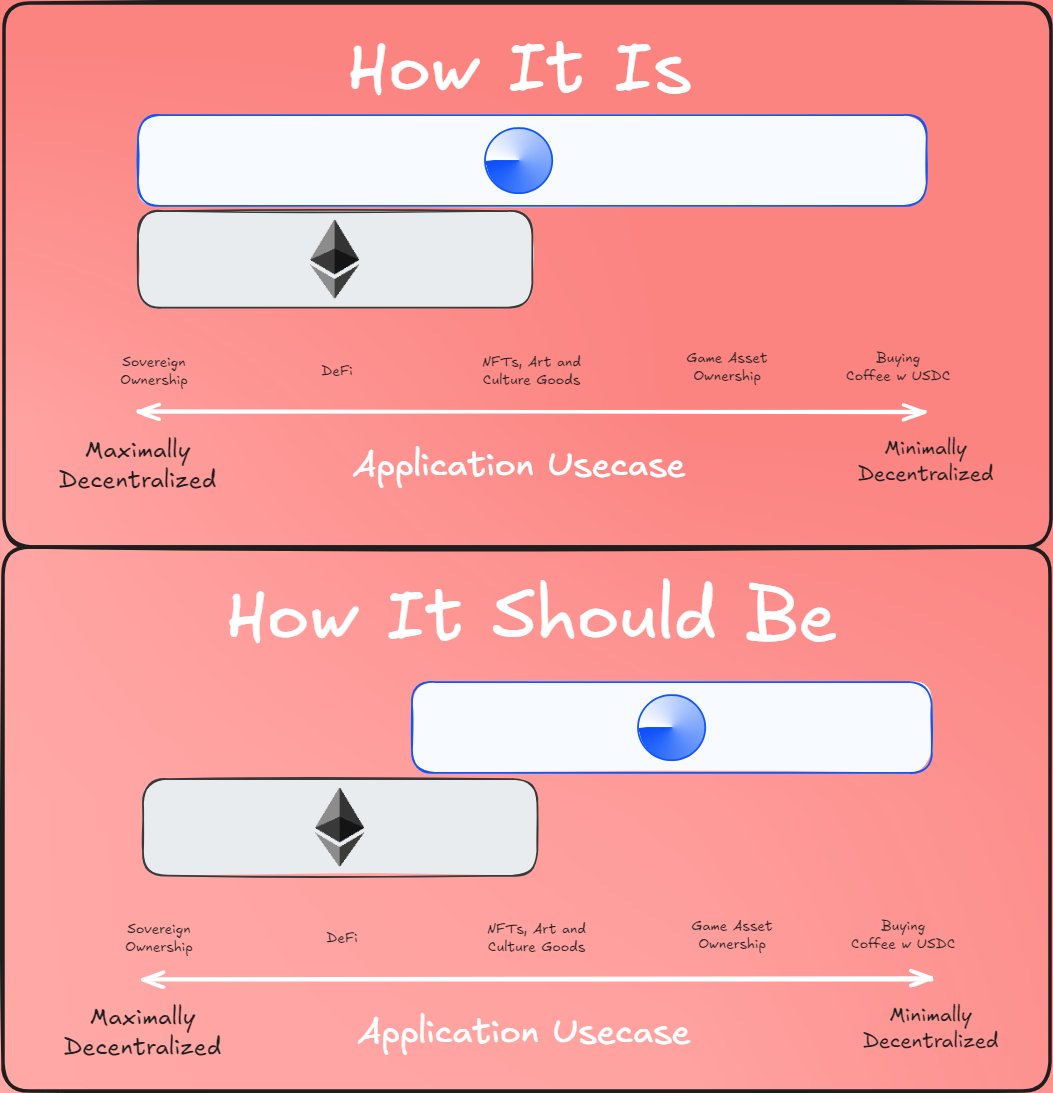
有观点认为 L1 和 L2 之间存在「分工」;来源:@0xBreadguy
对路线图的其他部分有何影响?
让更多用户使用 L1 意味着不仅规模将得到改善,还可以改善 L1 的其他方面。这意味着更多的 MEV 将留在 L1 上(而不是仅仅成为 L2 的问题),因此明确处理 MEV 的需求将更加迫切。这将大大提高 L1 快速 slot 时间的价值。而这在很大程度上也取决于 L1 验证(the Verge)是否顺利。











 APP
APP 
